
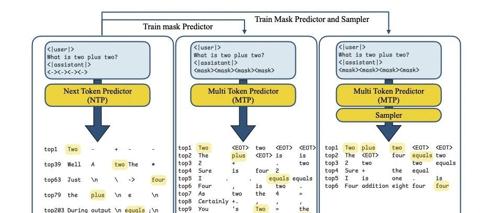
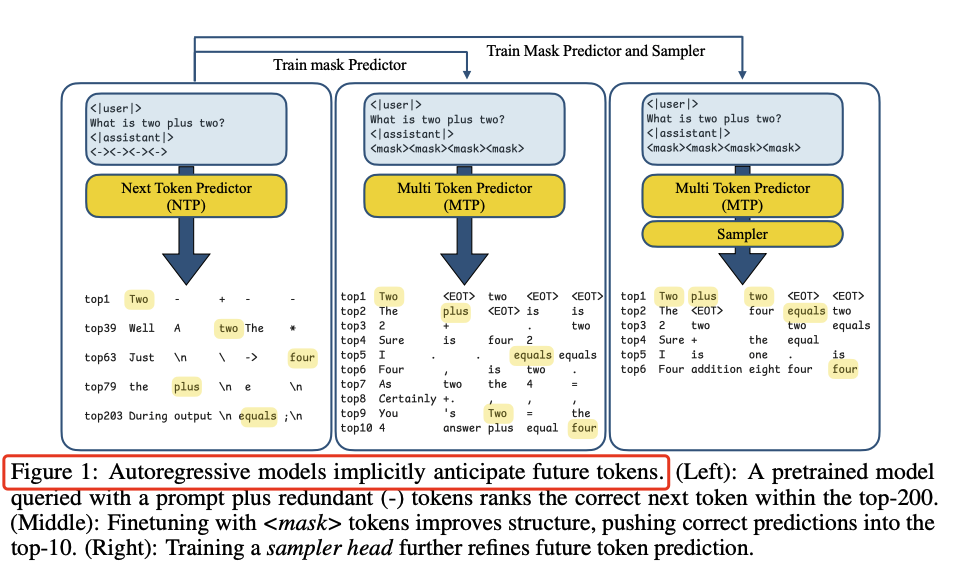

核心创新包括:
-
掩码输入机制:以同一前缀为条件,联合预测多个未来词元;
-
门控 LoRA 结构:在完整保留原 LLM 功能的同时,为其注入多词元预测能力;
-
轻量级可学习采样器:将并行预测的词元快速组合成连贯序列;
-
辅助训练损失(含一致性损失):提升并行输出的一致性与准确率;
-
推测式生成策略:在保证高保真的前提下,实现未来词元的二次方级扩展。
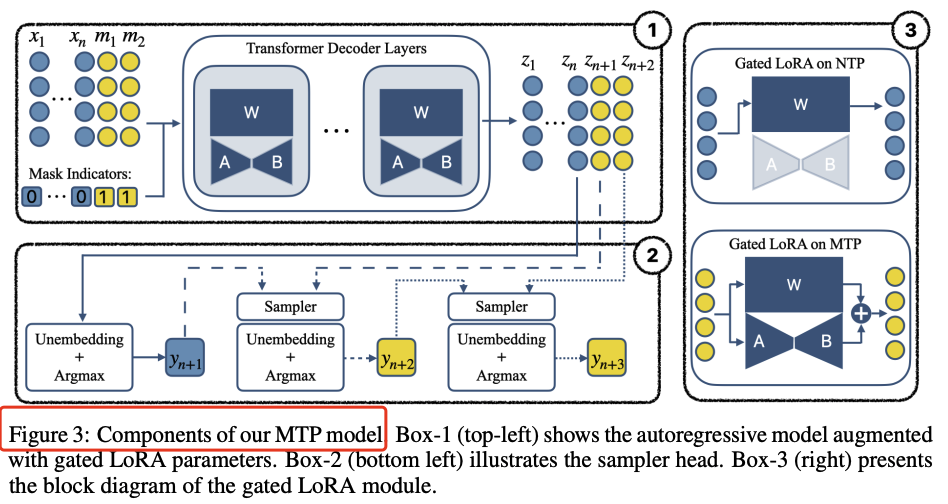
方法细节
-
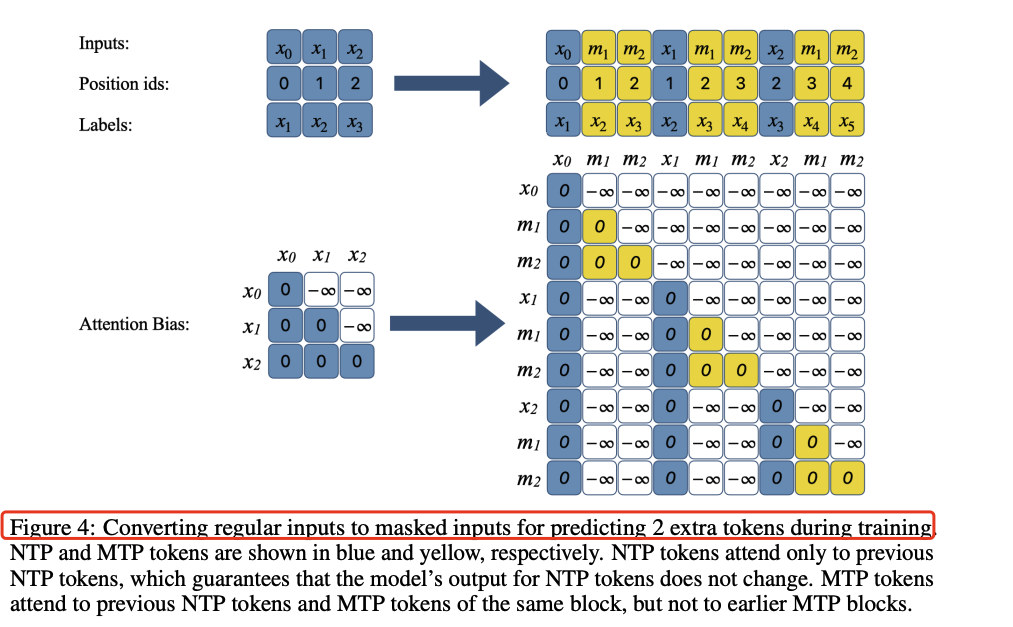
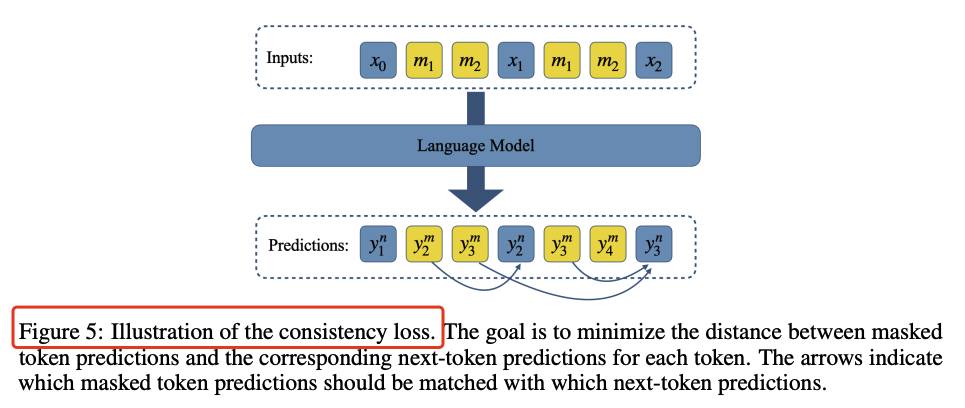
掩码token的使用:通过在输入序列末尾添加掩码token,模型被训练直接预测这些掩码token,从而实现多token预测。
-
-
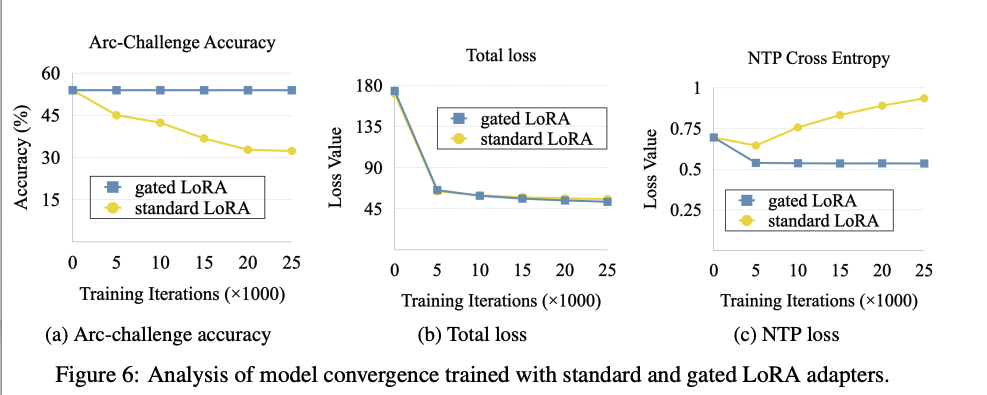
门控LoRA模块:在微调过程中,只有LoRA参数和采样器头部参数被更新,原始解码器权重保持不变。这种门控机制确保了微调不会影响原始的下一个token预测(NTP)行为。
-
采样策略:通过训练一个采样器头部,将预测的token条件化在当前上下文和前面生成的token上,从而提高多token生成的连贯性。
-
推测性解码:通过比较标准自回归生成的token和多token预测生成的token,验证预测token的有效性。提出了线性解码和二次解码两种策略,其中二次解码策略保证了每个生成步骤都能产生固定数量的新推测token,从而维持一致的解码进度。
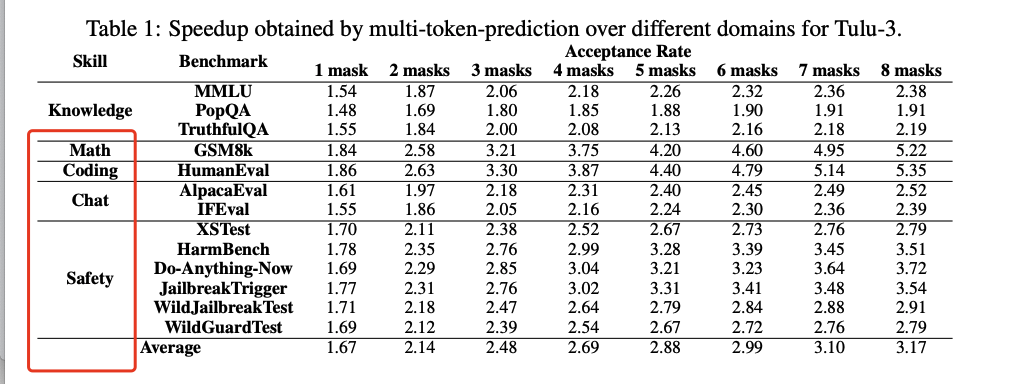
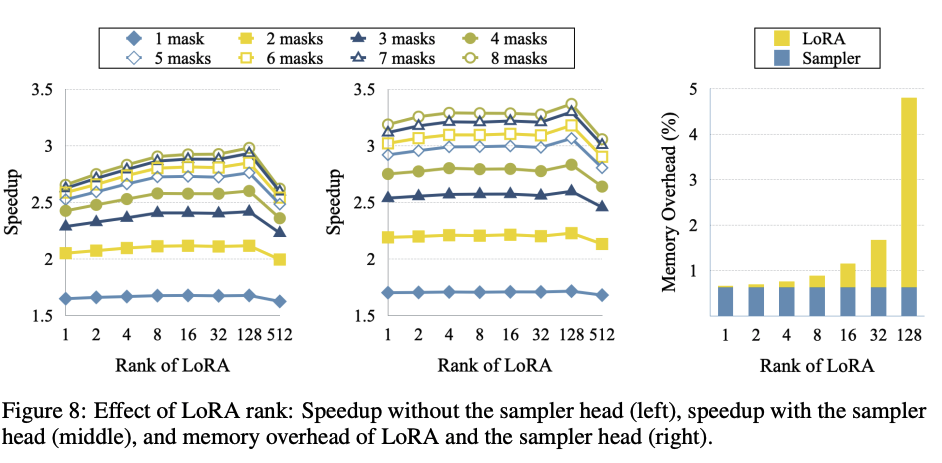
仅需在预训练模型上做监督微调,即可显著提速:代码与数学题生成速度提升近 5 倍,通用聊天与知识问答任务提升约 2.5 倍,且输出质量毫无损失。
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potentialhttps://arxiv.org/pdf/2507.11851
(文:PaperAgent)