


新智元报道
新智元报道
【新智元导读】谷歌DeepMind刚拿下金牌后,3位Gemini核心研究员光速离职了。没错,这一次又是小扎干的好事。
前脚刚夺下IMO金牌,后脚就被小扎抄家了。
刚刚,Information爆料称,Meta从谷歌DeepMind金牌模型团队中,再次挖走了三位华人学者。

这三人分别是Tianhe Yu、Cosmo Du和Weiyue Wang,一同参与了Gemini开发。
而且,就在谷歌庆祝IMO夺金的第二天,三位研究员「闪电」离职,转投入Meta超级智能实验室。

就在昨天,GDM的官宣博文中,详细列出了所有参与Gemini模型开发的研究人员。
这些研究人员的含金量,不言而喻。

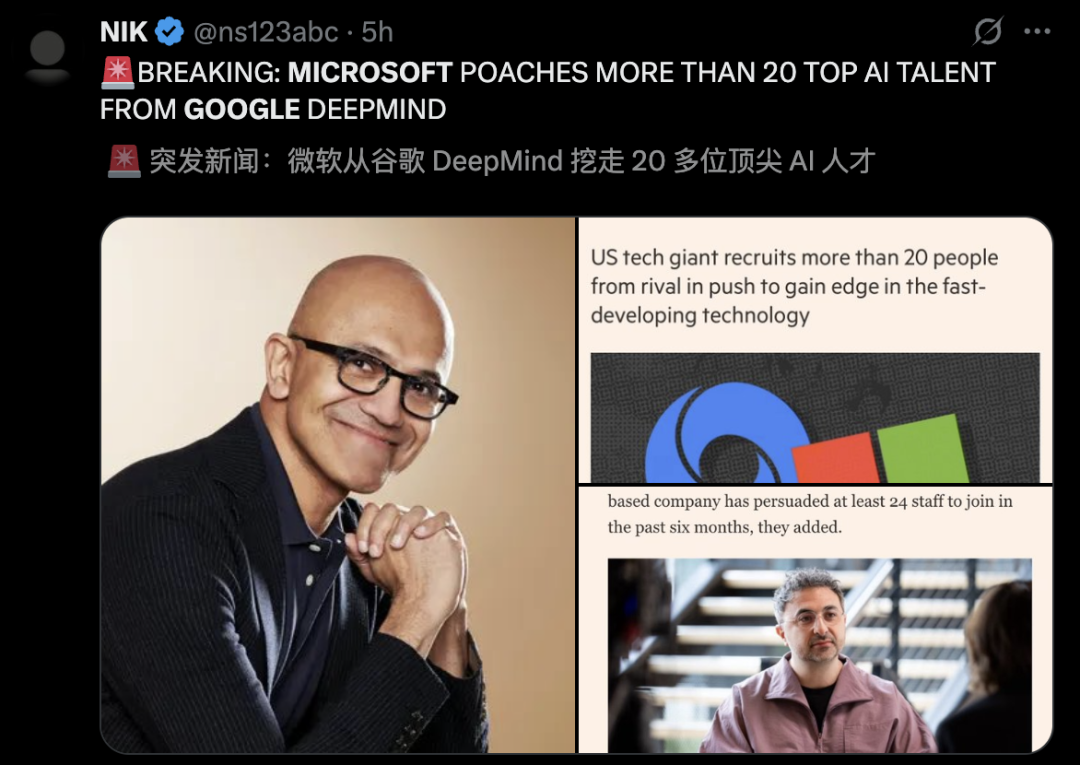
讽刺的是,今早,微软也被爆出从谷歌DeepMind挖走了20多位顶尖研究人员。
2016年,AlphaGO在围棋领域击败李世石;如今不到10年的时间,Gemini再次攻克奥数难题斩获金牌。
不容置疑的是,这场AI军备赛,正向ASI阶段全面迈进,顶尖人才争夺战也变得愈发激烈。


被挖走IMO金牌模型团队三位研究员,都有怎样的背景呢?
Tianhe Yu

Tianhe Yu现任谷歌DeepMind研究科学家。
在GDM期间,Tianhe Yu曾参与了Gemini 2.5、初代Gemini、Gemini 1.5等全家桶的研发,甚至包括千亿参数大模型PaLM-E的开发。
值得一提是,他还在谷歌RT-1、RT-2机器人模型上做出了贡献。
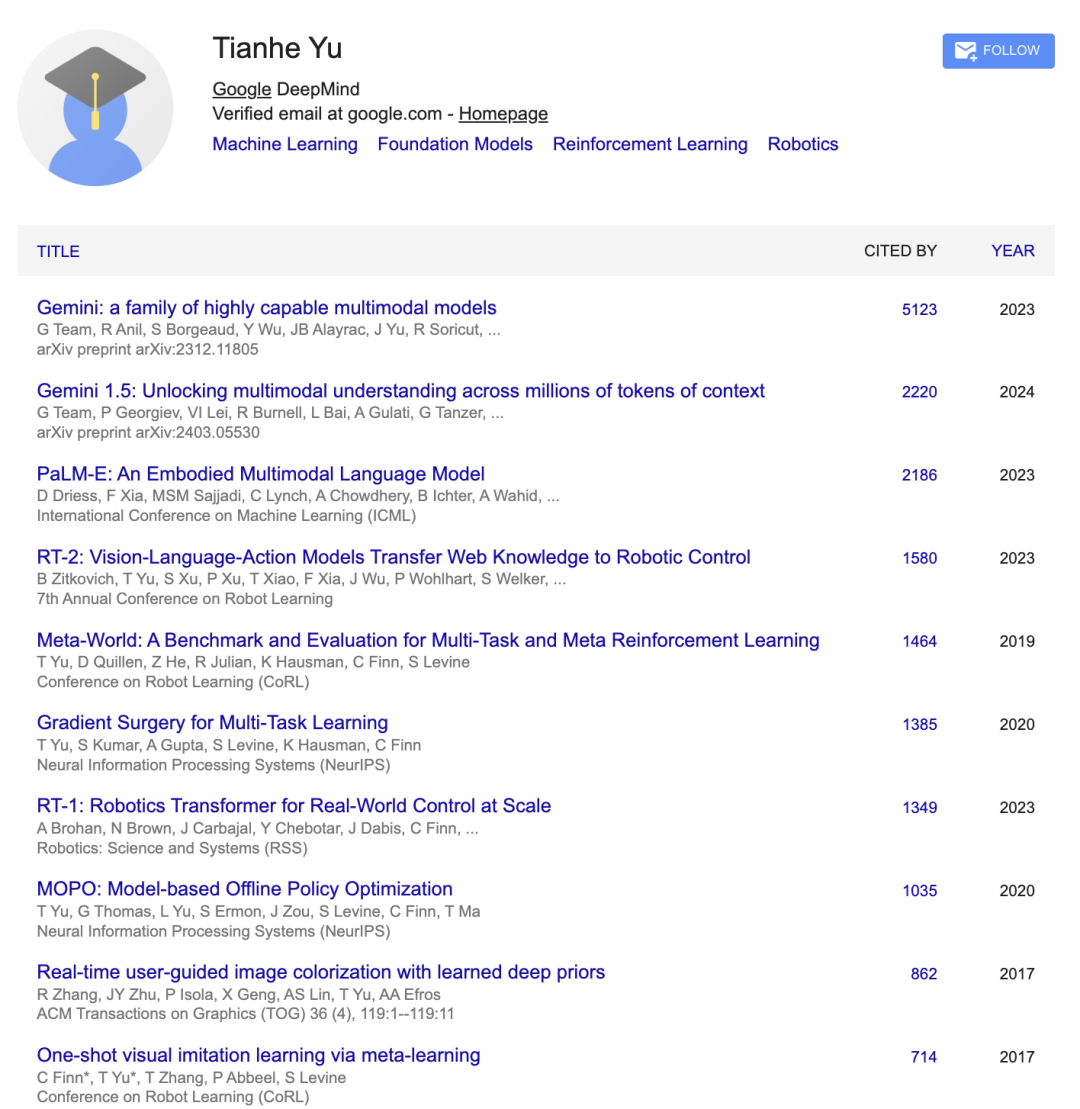
他曾获得了坦福大学计算机科学博士学位,师从Chelsea Finn教授。本科毕业于加州大学伯克利分校,以最高荣誉同时获得计算机科学、应用数学与统计学三个学位。
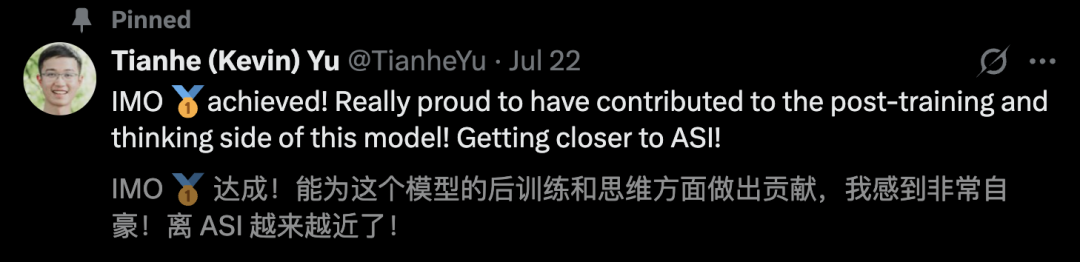
昨天,GDM公布IMO金牌结果后,Tianhe Yu本人也发文称,参与了Gemini Deep Think模型后训练、思维研发。
他激动表示,「离ASI越来越近了」!
Cosmo Du(杜宇)

杜宇在2017年便加入谷歌,任谷歌DeepMind首席科学家兼总监,专注于Gemini的后训练、思维与代码生成。
他同样是Gemini 1、1.5、2和2.5的核心贡献者,并开发了Gemini-0801——谷歌首个在LMSYS排行榜上位列第一的模型。
此前,他还主导了Bard/LaMDA的后训练工作,并开发了Bard首个内部版本。
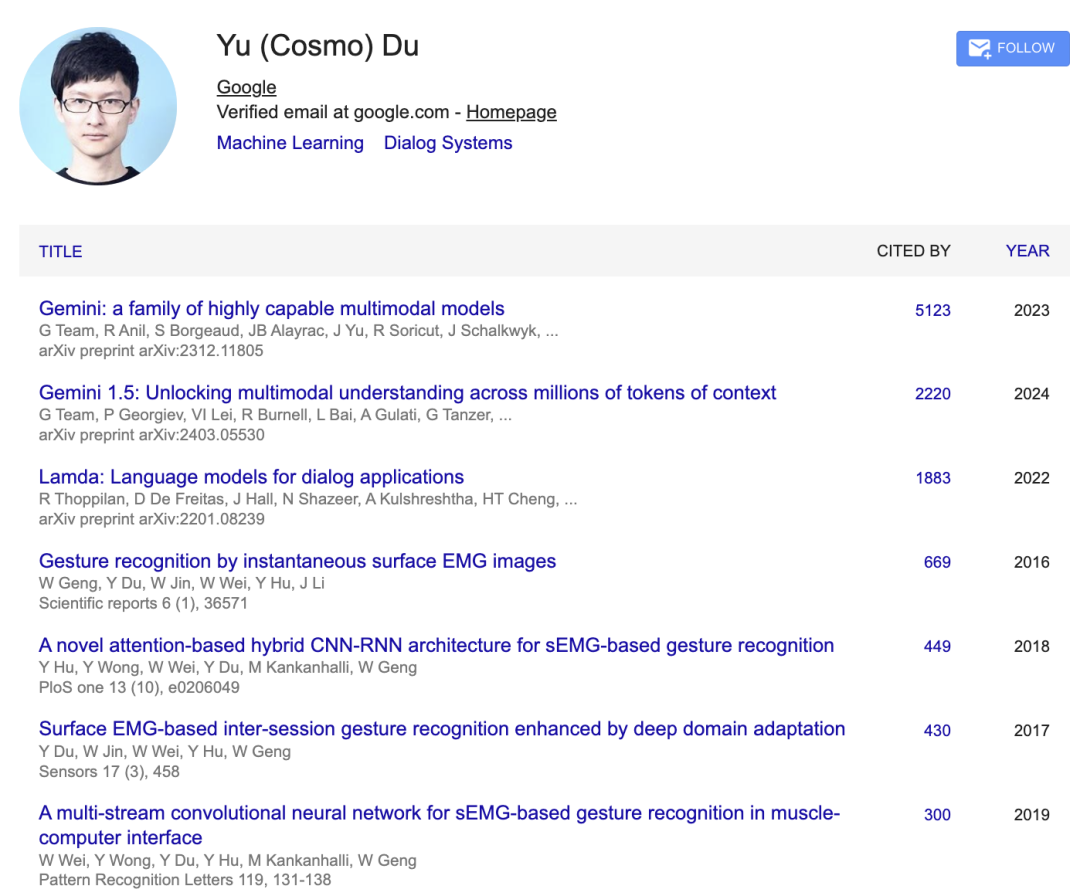
更早之前,他专注于任务型对话系统,帮助Duplex实现了10倍Scaling。
他曾获得了浙江大学计算机科学博士学位,本科毕业于华东理工大学计算机科学专业。

Weiyue Wang

Weiyue Wang任谷歌DeepMind研究工程师,在加入谷歌之前,她曾在Waymo担任软件工程师。
她曾获得了南加州大学博士学位,导师是Ulrich Neumann教授;获得了俄亥俄州立大学电子和计算机工程硕士学位;上交大EEE学士学位。

她本人的研究专注于计算机视觉领域,特别是3D场景理解与重建。
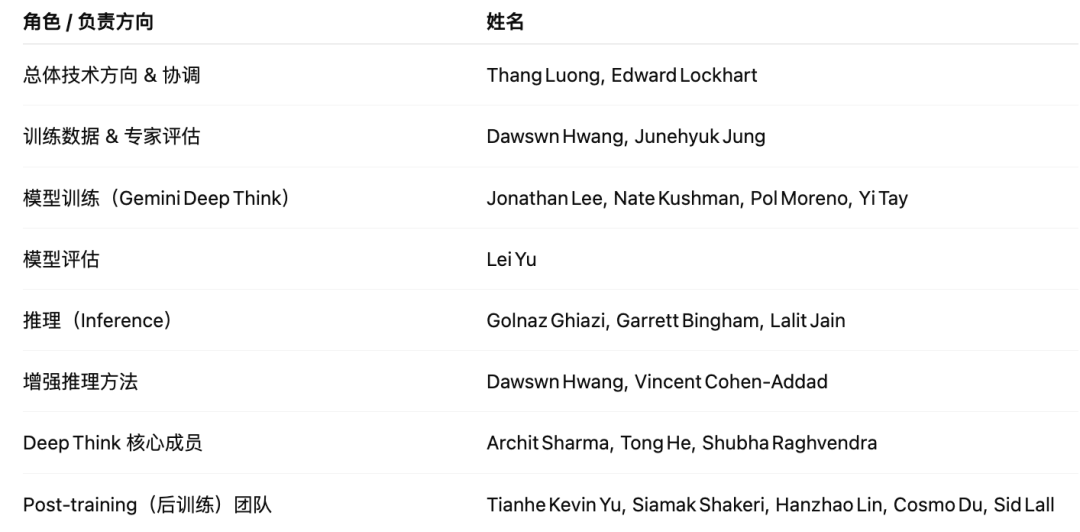
以下是所有参与谷歌IMO 2025系统的研究人员。

上下滑动查看
我们让ChatGPT将核心负责人,以及Gemini Deep Think团队列出。
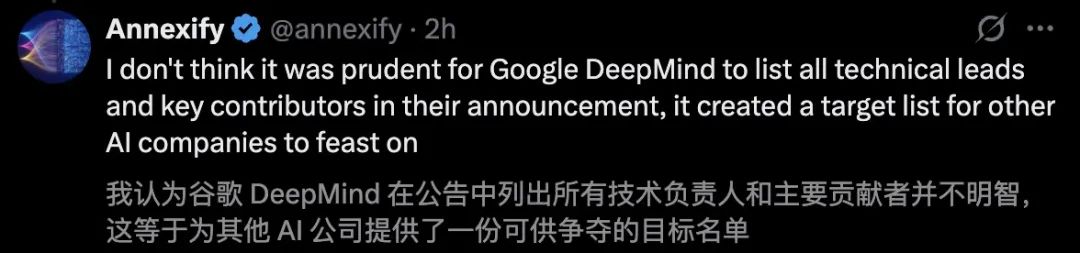
有网友对此表示,GDM列出所有人名单有些太不明智了。
其实,不用Gemini Deep Think,Gemini 2.5 Pro也能拿下IMO金牌。

来自加州大学洛杉矶分校副教授Lin Yang和Yichen Huang(黄溢辰)一起做了这个实验,并将结果发表在arXiv上。

论文地址:https://arxiv.org/pdf/2507.15855
他们通过精心设计的流程和提示工程,让Gemini 2.5 Pro也能攻克5道奥数难题。这究竟是如何做到的?
研究人员的流程设计,一共分为了以下六步:
· 初始解答生成:通过第3.1节的提示词生成初始解;
· 自我改进:对初始解进行优化;
· 验证:进入步骤4或步骤;
· 验证检查:判断解的合理性;
· 纠正:若验证失败,返回步骤3;
· 接受或拒绝:最终决定是否采纳该解。
在初始阶段,需要多次运行Gemini 2.5 Pro以获取问题的若干初始解样本。
这一采样过程类似于探索性尝试,希望至少有一个样本能部分接近正确解法。随后,再通过迭代优化这些解,最终筛选出高质量结果。
具体而言,首先让Gemini 2.5 Pro尝试通过提示词解决问题,第二步中,模型被要求自我审查并改进其解答。
尽管Gemini 2.5 Pro擅长数学推理,但作为通用LLM,它并非专为解决极高难度数学问题而设计。一个关键限制是思维预算:即使证明一个简单事实也可能消耗数千token,而Gemini 2.5 Pro的最大上下文token为32768,这通常不足以完整解决一道IMO试题。
研究人员观察到,在第一步中模型几乎总会耗尽全部预算,导致无法完成完整求解。
因此,他们将解题过程分解为多步骤,第二步的核心目标是通过额外分配32768 token的预算,让模型能够复查并延续其工作。实际监测显示,第二步的输出质量显著提升。
接下来,验证器将参与迭代优化并决定是否接受改进后的解。
详细指令参考,覆盖了核心要求、输出格式、自我纠正的指令,具体可参见下图。


上下滑动查看
比如,让Gemini 2.5 Pro去解决P1题,再向模型发送问题陈述后,又追加了一句话「让我们尝试用归纳法来解决这个问题」。
别小瞧了这句话,可以为模型提供一个强大的方向性引导。而且,就题目组合问题而言,确实也可以通过数学归纳法解决。
设想一个旨在解决复杂问题的多智能体系统:这类任务通常需要大量探索——需要让不同智能体尝试不同方法,以期其中某个能找到可行路径。
在此情境下,对于任何适用于正整数的命题,数学归纳法都是标准且常用的有效方法。
其余题目的提示,以及解题过程,可参考论文中的细节。
顺便提一句,字节也在今年IMO上,凭借Seed Prover取得了银牌分数。

具体来说,Seed Prover完整破解了6题中的4题,最终获取了30分。另外,在赛后尝试后,AI一共证明了5道题,也算是拿下了金牌。

如今,OpenAI和GDM先后凭借AI,攻克了前5题,拿下了IMO金牌。
IMO的人类阵地,就仅剩下P6题了。
(文:新智元)