
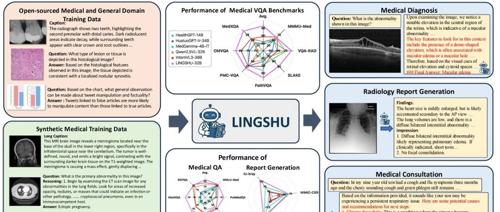

Lingshu是阿里巴巴达摩院开源的通用多模态医疗大模型,支持超过12种医学影像模态,包括X光、CT、MRI、超声、病理等,并在医疗多模态/文本问答和报告生成任务上达到SOTA性能,为医疗AI领域提供了强大的技术支撑。
一、技术原理
(一)多模态数据融合
Lingshu采用了先进的多模态数据融合技术,将医学影像与文本数据相结合,通过深度学习模型实现跨模态的信息理解与推理。模型能够同时处理图像和文本输入,提取关键特征并进行综合分析,从而更准确地理解医疗场景中的复杂信息。
(二)多阶段训练范式
Lingshu的训练过程分为多个阶段,包括浅层对齐、深层对齐、指令调优和医疗导向的强化学习。这种分阶段训练策略使模型能够逐步吸收医疗知识,提升任务解决能力。在浅层对齐阶段,模型学习基本的视觉–语言对应关系;深层对齐阶段则进一步整合复杂的医疗知识;指令调优阶段优化模型对医疗指令的理解和执行;最后,通过强化学习提升模型的医疗推理能力。
(三)数据合成与增强
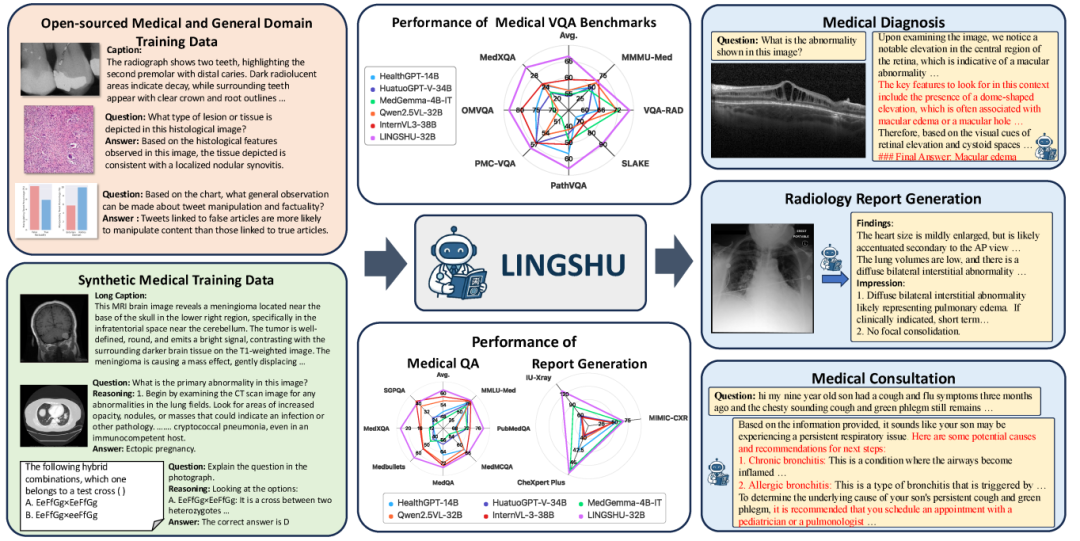
为了丰富训练数据,Lingshu团队开发了数据合成管道,生成高质量的医学图像描述、视觉问答样本和推理链数据。这些数据不仅提高了模型对医学影像的理解能力,还增强了其在实际医疗任务中的泛化性能。
二、主要功能
(一)多模态医疗问答
Lingshu能够处理多种医学影像模态的视觉问答任务,如识别病变、判断疾病类型等。模型在多个医疗VQA基准测试中表现优异,准确率显著高于其他开源模型,甚至在某些任务上超越了GPT-4.1和Claude Sonnet 4等专有模型。
(二)医疗报告生成
Lingshu具备强大的医疗报告生成能力,能够根据医学影像自动生成详细的诊断报告。在MIMIC-CXR、CheXpert Plus和IU-Xray等数据集上,Lingshu生成的报告在语义和临床相关性方面均达到了较高水平,为医生提供了有力的辅助诊断工具。

(三)医疗知识推理
Lingshu不仅能够识别医学影像中的异常,还能进行深入的医学知识推理。例如,在解释神经递质合成与释放过程时,模型能够准确识别突触类型,并结合相关医学知识进行详细解释,展现出对复杂医学概念的深刻理解。

三、应用场景
(一)辅助诊断
Lingshu可广泛应用于辅助诊断场景,帮助医生快速识别医学影像中的病变,提高诊断效率和准确性。在多模态医疗问答任务中,模型能够为医生提供即时的诊断建议,辅助医生做出更准确的判断。
(二)医疗教育与培训
Lingshu生成的详细医学影像描述和推理过程,可用于医疗教育和培训。医学生和医生可以通过与模型互动,学习如何解读医学影像,提升专业技能。
(三)医疗研究与数据分析
Lingshu能够处理大规模的医学影像数据,为医疗研究提供支持。研究人员可以利用模型对医学影像进行自动标注和分析,加速研究进程,发现潜在的医学规律。
四、性能评估
(一)多模态医疗问答性能
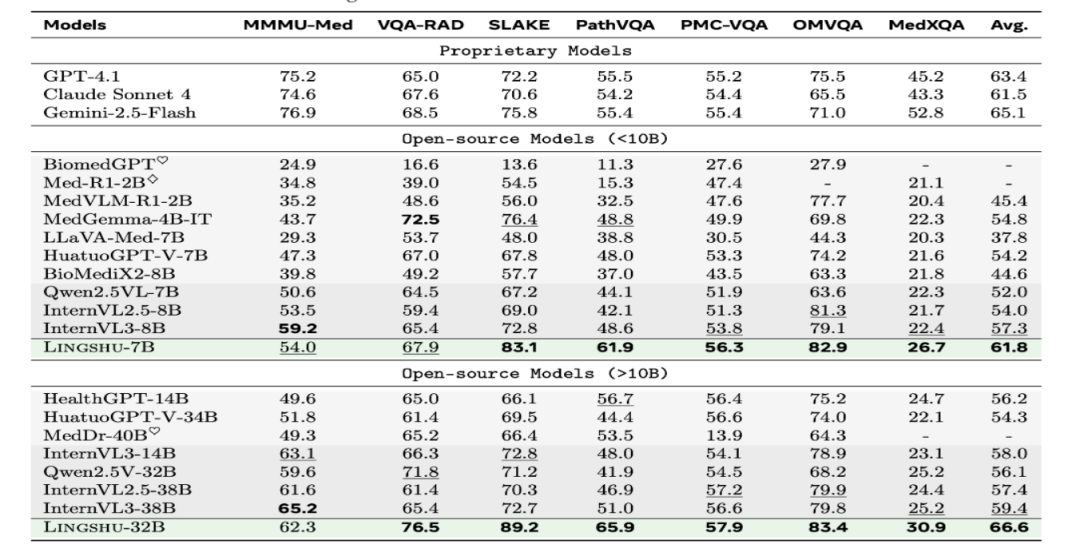
在多个医疗多模态问答基准测试中,Lingshu-7B和Lingshu-32B均取得了优异的成绩。Lingshu-7B在SLAKE、PathVQA、PMC-VQA等数据集上排名第一,平均准确率达到61.8%;Lingshu-32B的平均准确率更是达到了66.6%,在所有基准测试中均排名第一,超越了其他开源模型和专有模型。
(二)医疗文本问答性能
Lingshu在医疗文本问答任务中也表现出色。Lingshu-7B在PubMedQA、MedQA-USMLE等数据集上取得了最高分,平均准确率为52.8%;Lingshu-32B的平均准确率达到了61.8%,在多个数据集上排名第一,展现了强大的医疗文本理解能力。
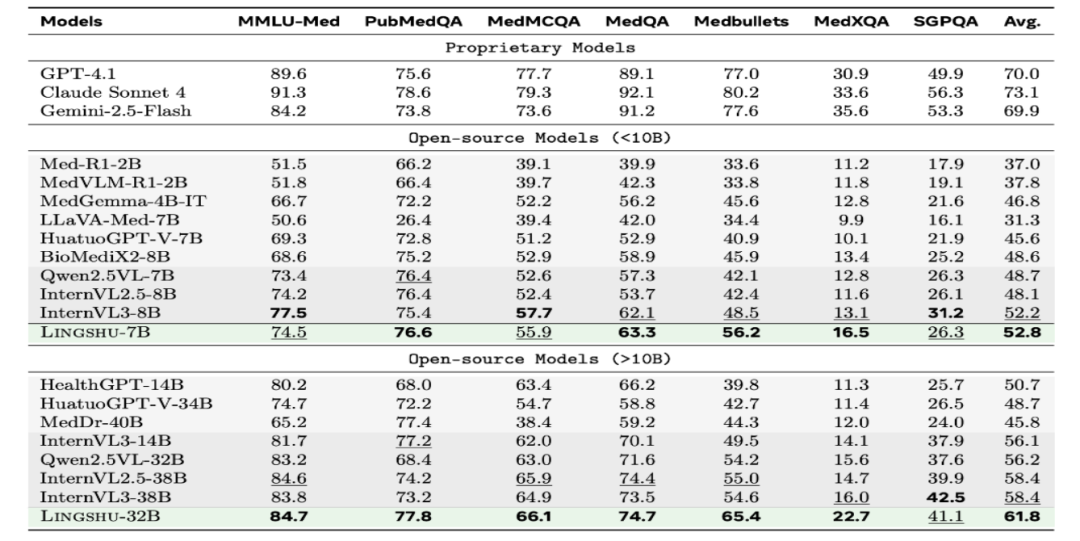
(三)医疗报告生成性能
在医疗报告生成任务中,Lingshu-7B和Lingshu-32B在MIMIC-CXR、CheXpert Plus和IU-Xray数据集上均取得了领先的性能。Lingshu-32B在IU-Xray数据集上的ROUGE-L、CIDEr等指标上表现尤为突出,生成的报告在语义和临床相关性方面均达到了较高水平。
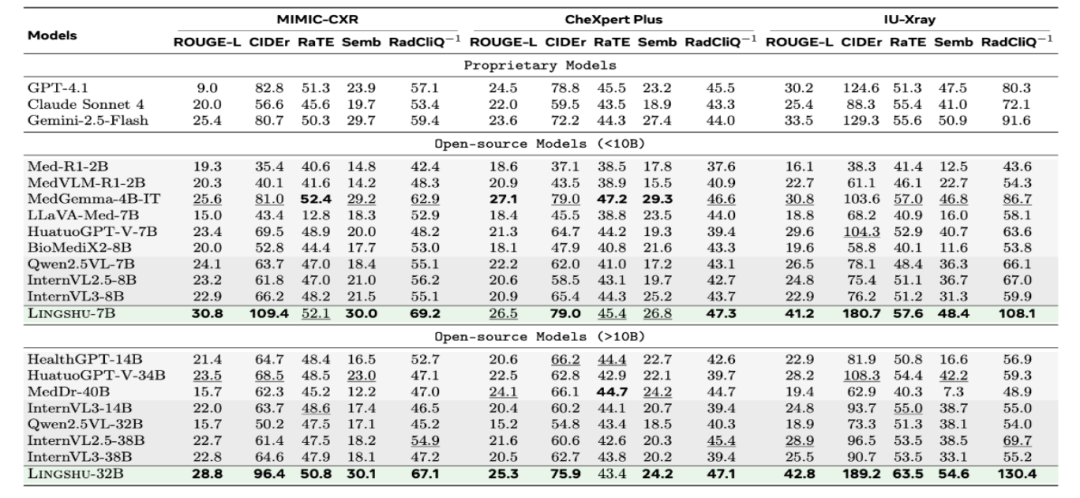
五、快速使用
(一)环境准备
1. 安装Python环境,推荐使用Python 3.8及以上版本。
2. 安装必要的依赖库,如transformers、torch等。
(二)模型下载
你可以从[HuggingFace模型库](https://huggingface.co/lingshu-medical-mllm/models)下载Lingsh模型。可以选择Lingshu-7B和Lingshu-32B;下载完成后,将模型文件保存到本地目录中。

(三)模型推理
使用Transformers库加载下载的Lingshu模型,并进行推理使用。以下是一个简单的代码示例:
# 导入必要的库和模块from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessorfrom qwen_vl_utils import process_vision_info# 加载预训练的Lingshu模型# 推荐使用flash_attention_2以加速推理并节省内存,特别是在处理多图像和视频场景时model = Qwen2_5_VLForConditionalGeneration.from_pretrained("lingshu-medical-mllm/Lingshu-7B", # 模型名称torch_dtype=torch.bfloat16, # 使用bfloat16数据类型以节省内存attn_implementation="flash_attention_2", # 启用flash_attention_2device_map="auto", # 自动分配模型到可用设备)# 加载与模型配套的处理器processor = AutoProcessor.from_pretrained("lingshu-medical-mllm/Lingshu-7B")# 定义输入消息,包含用户角色、图像和文本内容messages = [{"role": "user", # 用户角色"content": [{"type": "image", # 内容类型为图像"image": "example.png", # 图像文件路径},{"type": "text", "text": "Describe this image."}, # 用户提问的文本内容],}]# 准备推理所需的输入数据# 使用处理器将消息转换为模型可接受的格式text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)# 处理视觉信息,提取图像和视频输入image_inputs, video_inputs = process_vision_info(messages)# 将文本、图像和视频输入打包为模型输入inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True, # 对输入进行填充以保持一致性return_tensors="pt", # 返回PyTorch张量)# 将输入数据移动到模型所在的设备上inputs = inputs.to(model.device)# 执行推理,生成输出generated_ids = model.generate(**inputs, max_new_tokens=128) # 生成最多128个新token# 去除输入部分的token,仅保留生成的tokengenerated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]# 将生成的token解码为文本output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)# 打印生成的文本输出print(output_text)
结语
Lingshu作为阿里巴巴达摩院开源的多模态医疗大模型,凭借其强大的多模态数据处理能力和优异的性能表现,为医疗AI领域带来了新的发展机遇。无论是辅助诊断、医疗教育还是医疗研究,Lingshu都展现出了巨大的应用潜力。随着医疗AI技术的不断进步,Lingshu有望在未来的医疗场景中发挥更加重要的作用,助力医疗行业实现智能化转型。
相关资料
项目官网:https://alibaba-damo-academy.github.io/lingshu/
模型下载:https://huggingface.co/lingshu-medical-mllm/Lingshu-7B
技术报告:https://arxiv.org/pdf/2506.07044
(文:小兵的AI视界)