


极市导读
本文提出一种名为REG的全新方法,通过将低级图像潜在表示与高级类别令牌进行“纠缠”,极大地提高了扩散模型的训练效率和生成质量,在ImageNet上实现了高达63倍的训练加速。>>加入极市CV技术交流群,走在计算机视觉的最前沿

-
作者: Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Jian Yang, Ming-Ming Cheng, Xiang Li -
发表机构: 南开大学、南开国际先进研究院、极豪科技、哈佛大学、中国科学院大学 -
论文地址: https://arxiv.org/abs/2507.01467v1 -
项目地址: https://github.com/Martinser/REG -
录用信息: ICCV 2025
背景与意义
近年来,扩散模型在图像生成领域取得了SOTA的性能,但其训练过程通常需要巨大的计算资源和时间成本,这限制了其在更广泛场景下的应用。为了解决这个问题,研究者们提出了各种方法来加速训练,例如引入预训练模型的外部视觉表示(如REPA方法)。
然而,作者认为,现有的方法(如REPA)在推理过程中并没有完全利用这些判别性表示的潜力,因为这种外部对齐在整个去噪推理过程中是缺失的。这启发了作者去探索一种更直接、更高效的方式来利用判别性信息,从而诞生了本文方法REG(Representation Entanglement for Generation)方法。
主要方法
REG的核心思想非常直接:在去噪过程中,将低级的图像潜在表示与一个来自预训练基础模型的高级的单个类别令牌进行“纠缠”(Entanglement)。
具体来说,REG框架在训练时,将带有噪声的图像潜在表示和带有噪声的类别令牌拼接在一起,作为SiT(Scalable Interpolant Transformers)模型的输入。这样,模型在去噪的同时,不仅要重建图像,还要重建其对应的全局语义(类别信息)。
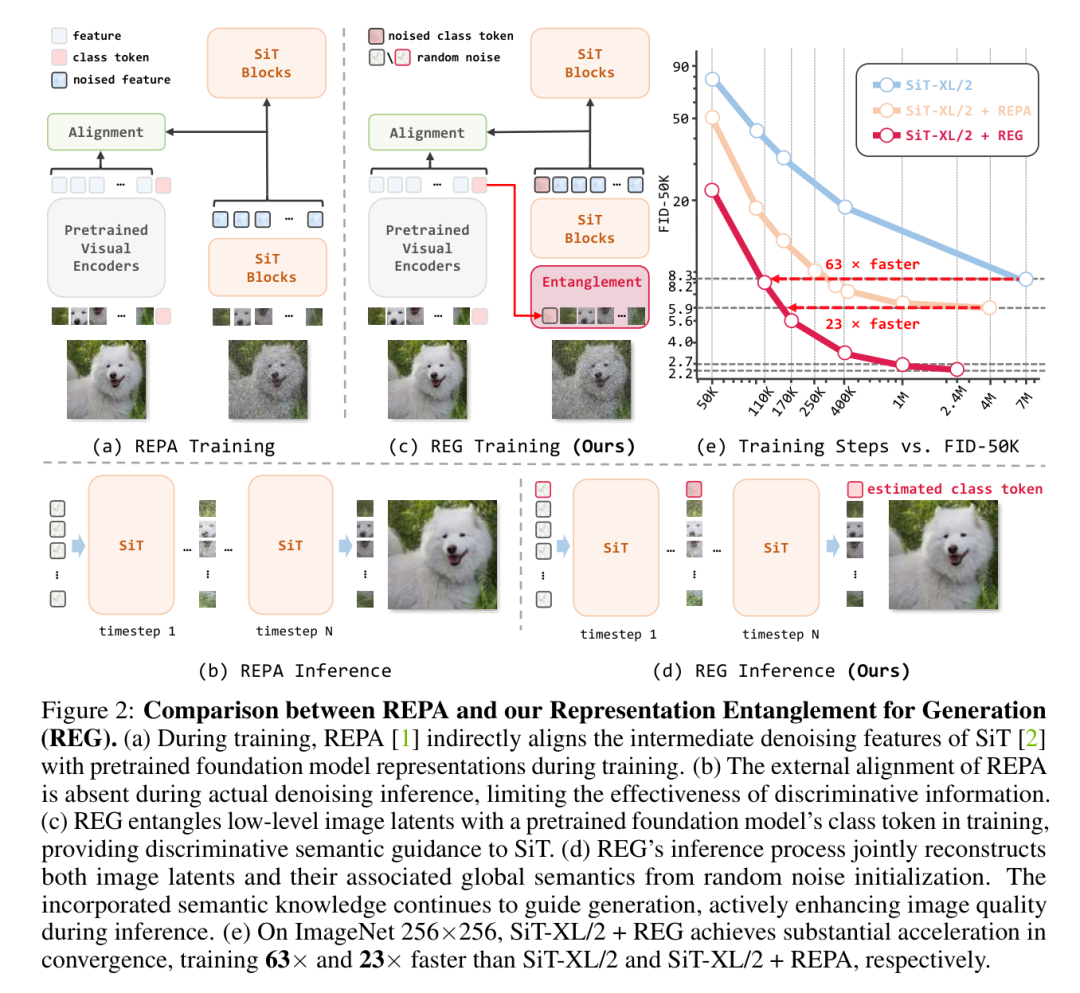
这种设计带来了几个关键优势:
-
持续的语义引导: 在整个推理过程中,重建的语义知识能够持续地、主动地引导和增强图像生成过程。 -
极低的额外开销: 相比于其他方法,REG只增加了一个额外的令牌用于去噪,带来的计算开销(FLOPs和延迟)增加小于0.5%,几乎可以忽略不计。 -
端到端的生成: REG能够直接从纯噪声生成连贯的“图像-类别”对,而不需要像一些方法那样需要一个额外的模型来生成类别令牌。
实验结果
REG在多个基准上都取得了惊人的效果,充分证明了其高效性和优越性。
训练速度和生成质量
在ImageNet 256×256数据集上,REG展现了恐怖的训练加速能力:
-
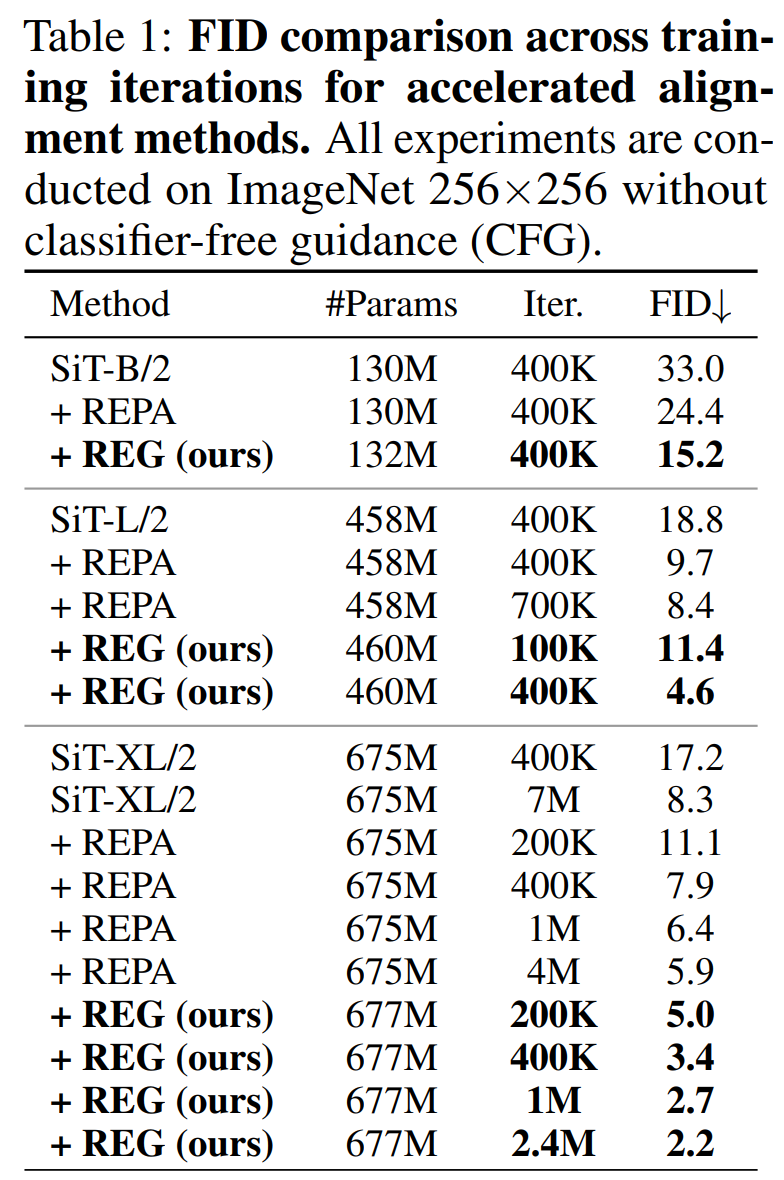
SiT-XL/2 + REG 分别比原始的 SiT-XL/2 和 SiT-XL/2 + REPA 快63倍和23倍。 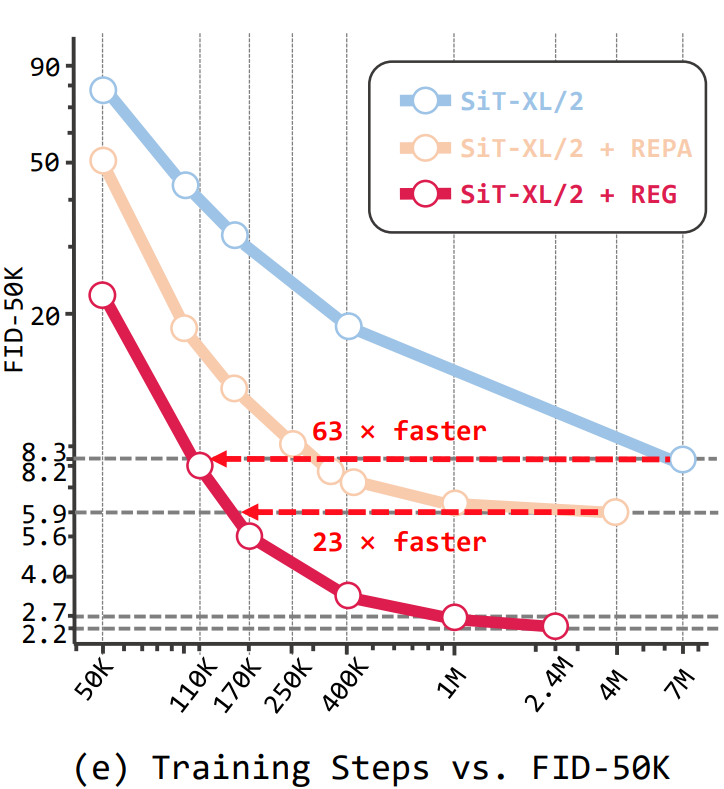
-
更夸张的是,仅训练了40万次迭代的SiT-L/2 + REG,其性能就超过了训练了400万次迭代(10倍时长)的SiT-XL/2 + REPA。
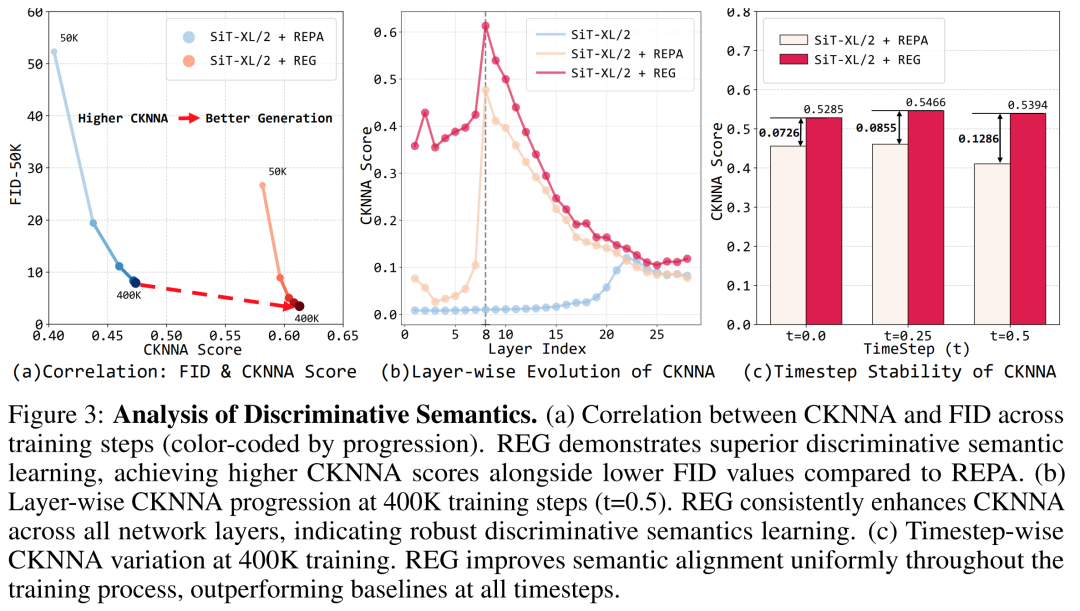
判别性语义学习
通过CKNNA分数(一种衡量表示相似性的指标)分析,REG在整个训练过程中都保持了更高的判别性语义学习能力,并且在网络的所有层和所有时间步上都优于基线模型。
生成样本
从论文展示的生成样本来看,REG生成的图像质量非常高,细节丰富,语义连贯。

结论与展望
REG框架通过一种简单而直接的“表示纠缠”方法,将判别性信息有效地融入到扩散模型的生成过程中,极大地提升了训练效率和生成质量,可以说是为扩散模型的训练找到了“捷径”。
这项工作证明了,我们不必总是依赖于复杂的模型结构修改来提升性能,通过更巧妙地利用预训练模型中的知识,同样可以实现SOTA的结果,甚至“以小博大”。REG的提出,无疑为未来生成模型的研究,特别是如何高效利用现有知识库,开辟了新的、令人兴奋的方向。
(文:极市干货)