

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!
这两天,一个名为「DeepSeek R1T2」的模型火了!
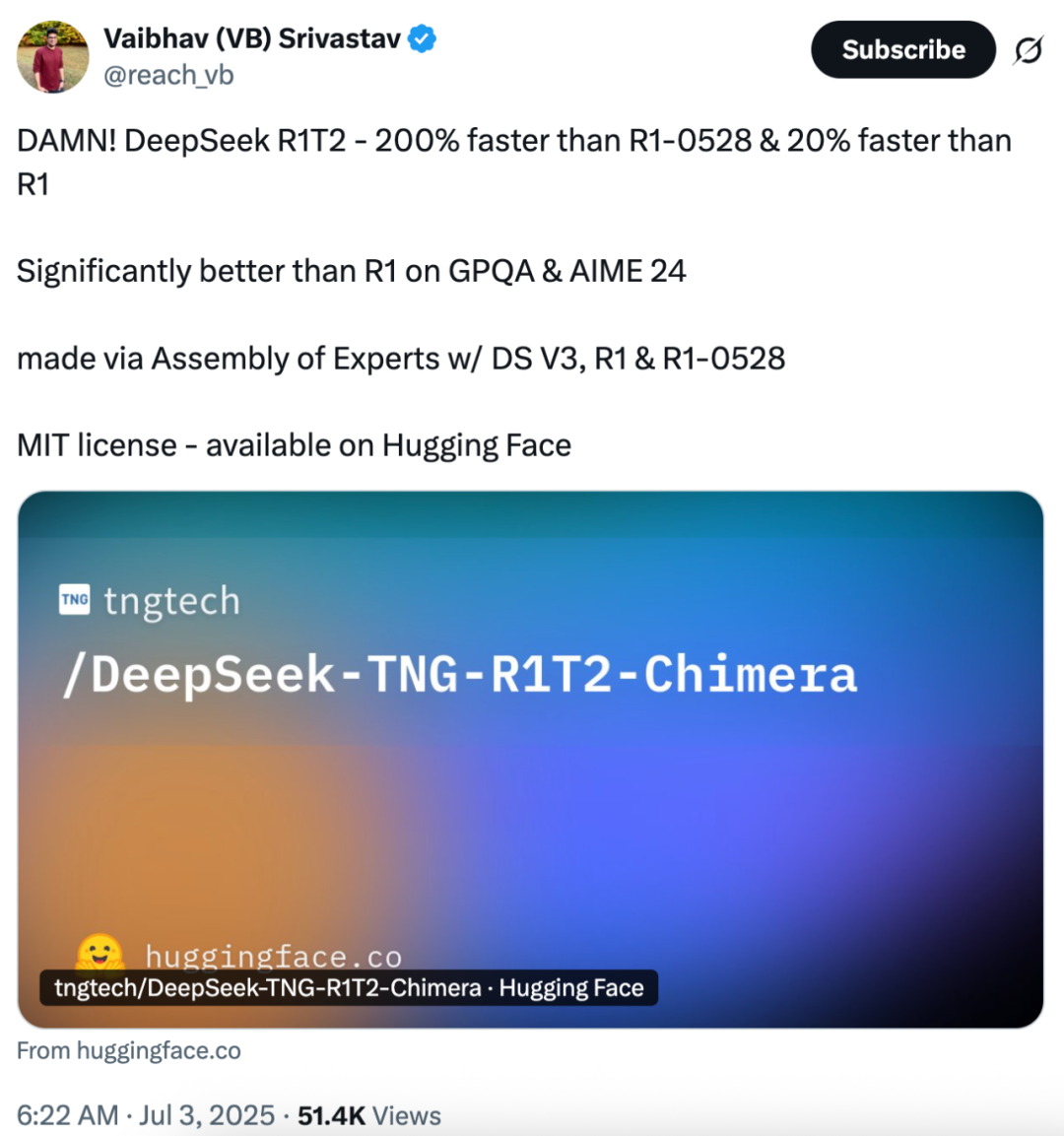
这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
在技术层面,采用了专家组合(Assembly of Experts,AoE)技术开发,并融合了 DeepSeek 官方的 V3、R1 和 R1-0528 三大模型。
当然,这个模型也是开源的,遵循 MIT 协议,并在 Hugging Face 上开放了权重。
Hugging Face 地址:https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
经过进一步了解,我们发现:DeepSeek R1T2 是德国一家 AI 咨询公司「TNG」推出的,模型全称为「DeepSeek-TNG R1T2 Chimera」(以下简称 R1T2)。
该模型除了前文提到的在智力水平和输出效率之间实现完美平衡之外,相较于这家公司的初代模型「R1T Chimera」,智力大幅跃升,并实现了突破性的 think-token 一致性。
不仅如此,即使在没有任何系统提示的情况下,该模型也能表现稳定,提供自然的对话交互体验。

在评论区,有人误以为这个模型出自 DeepSeek 官方,并且认为他们是不是也在走相同的路线:给模型起各种名称,就是不用主系列下一代版本号?

更多的人认可该模型「找到了智能与输出 token 长度之间的最佳平衡点,并且提升了速度」,并对该模型在现实世界的表现充满了期待。


模型细节概览
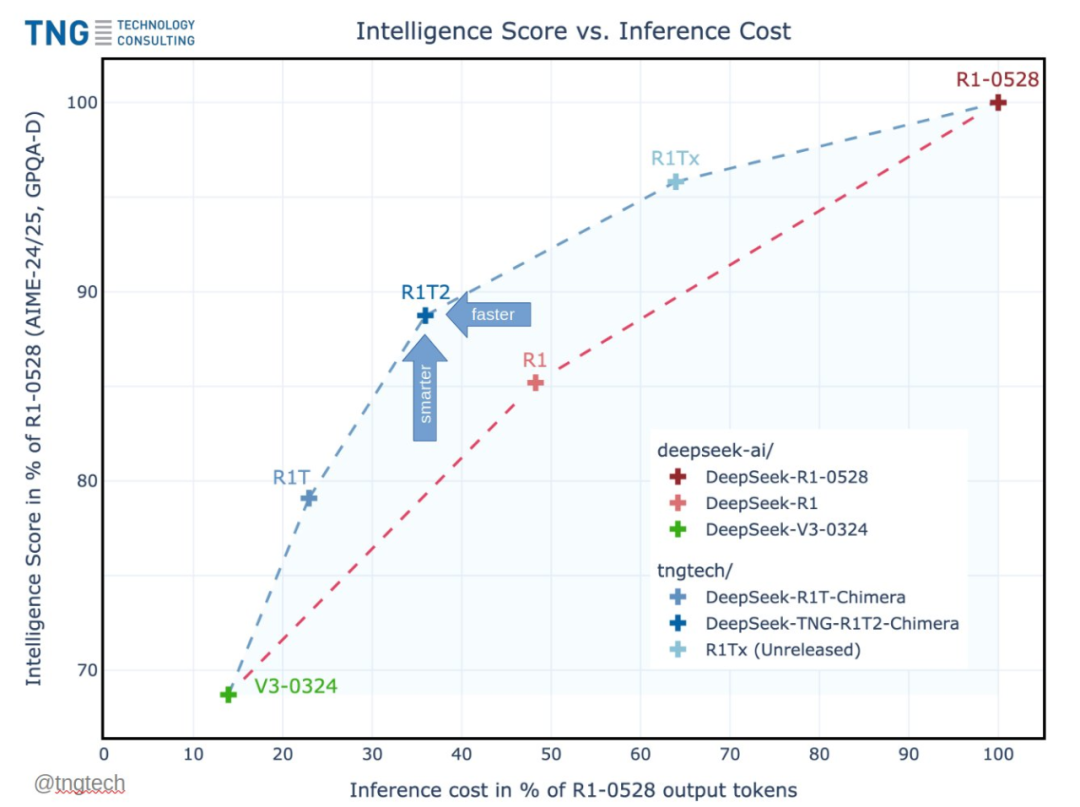
从 Hugging Face 主页来看,R1T2 是一个基于 DeepSeek R1-0528、R1 以及 V3-0324 模型构建的 AoE Chimera 模型。
该模型是一个采用 DeepSeek-MoE Transformer 架构的大语言模型,参数规模为 671B。
R1T2 是该公司 4 月 26 日发布的初代模型「R1T Chimera」的首个迭代版本。相较于利用双基模型(V3-0324 + R1)的初代架构,本次升级到了三心智(Tri-Mind)融合架构,新增基模型 R1-0528。
该模型采用 AoE 技术构建,过程中利用较高精度的直接脑区编辑(direct brain edits)实现。这种精密融合不仅带来全方位提升,更彻底解决了初代 R1T 的 <think>token 一致性缺陷。
团队表示,R1T2 对比其他模型具备如下优劣:
-
与 DeepSeek R1 对比:R1T2 有望成为 R1 的理想替代品,两者几乎可以通用,并且 R1T2 性能更佳,可直接替换。
-
与 R1-0528 对比:如果不需要达到 0528 级别的最高智能,R1T2 相比之下更加经济。
-
与 R1T 对比:通常更建议使用 R1T2,除非 R1T 的特定人格是最佳选择、思考 token 问题不重要,或者极度需求速度。
-
与 DeepSeek V3-0324 对比:V3 速度更快,如果不太关注智能可以选择 V3;但是,如果需要推理能力,R1T2 是首选。
此外,R1T2 的几点局限性表现在:
-
R1-0528 虽推理耗时更长,但在高难度基准测试中仍优于 R1T2;
-
经 SpeechMap.ai(由 xlr8harder 提供)测评,R1T2 应答克制度(reserved)显著高于 R1T,但低于 R1-0528;
-
暂不支持函数调用:受 R1 基模型影响,现阶段不推荐函数调用密集型场景(后续版本可能修复);
-
基准测试变更说明:开发版由 AIME24+MT-Bench 变更为 AIME24/25+GPQA-Diamond 测评体系,新体系下 R1 与初代 R1T 的分差较早期公布数据更大。
最后,关于 R1T2 中重要的 AoE 技术,可以参考以下论文。

-
论文标题:Assembly of Experts: Linear-time construction of the Chimera LLM variants with emergent and adaptable behaviors
-
论文地址:https://arxiv.org/pdf/2506.14794
(文:机器之心)