

GenieBlue团队 投稿
量子位 | 公众号 QbitAI
在AI迈入多模态时代的当下,“让大模型上手机”成为产业落地的焦点。
现有MLLM在手机端部署时常面临两大难题:
1、纯语言任务性能下降:现有的端侧MLLM在纯文本的任务上表现不尽人意;
2、手机NPU不支持MoE架构:而MoE架构恰恰是多模态训练中保持语言能力的常用手段(比如CogVLM,Wings)。
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。目前已被ICCV 2025接收。

主要贡献和技术亮点
1、现有端侧LLM在支持多模态功能后,纯语言任务准确率下降超10%。GenieBlue通过冻结原始LLM参数,并引入复制的Transformer层和轻量化的LoRA模块,在多模态训练的过程中保留原始的语言能力。
2、通过大规模微调,GenieBlue达到与主流MLLM相媲美的多模态能力,并完全保留原始纯语言性能。
3、避开当前NPU不支持的MoE架构,采用不共享基座的推理策略。在搭载高通骁龙8 Elite(第四代)芯片的手机上实现流畅运行。
技术背景
1、当前的端侧MLLM无法取得令人满意的纯语言能力
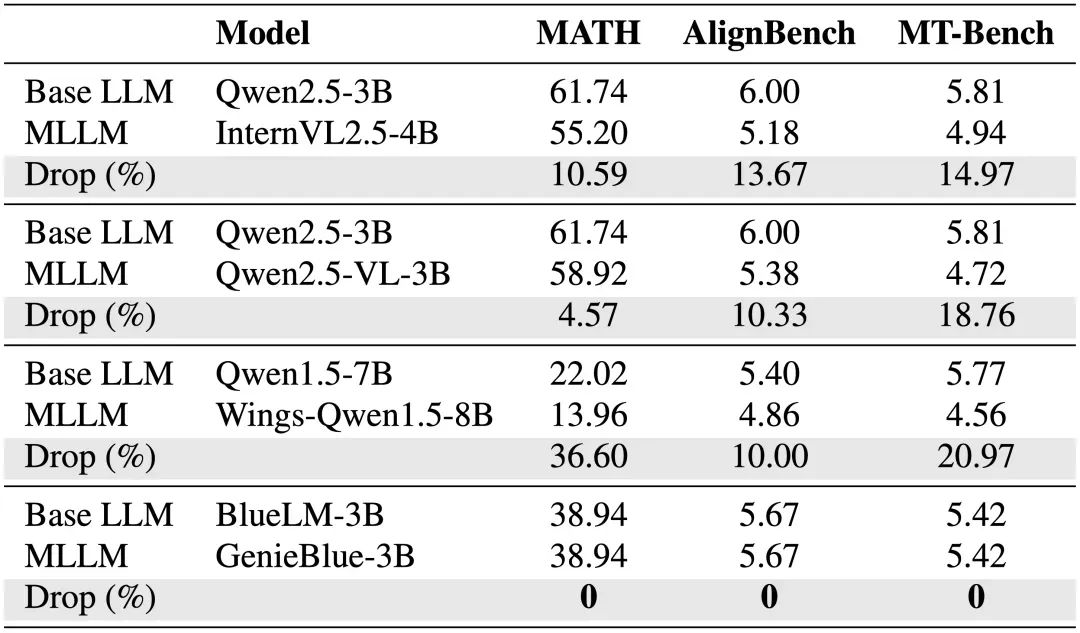
在MATH(客观难题)、AlignBench和MT-Bench(主观题)上测试主流开源MLLM的纯语言能力,并与原始LLM进行了对比。
其中,Wings是NeurIPS 2024提出的多模态训练中保持语言能力的方案。测试结果表明,当前多模态大模型虽然在图文任务上表现优异,但在纯语言任务上普遍存在显著性能下降,降幅大多超过10%。相比之下,GenieBlue在保持多模态能力的同时,未出现任何纯语言能力的损失。
2、目前主流的手机NPU平台尚不支持部署MoE结构
由于MoE架构对内存带宽和容量要求较高,主流移动端NPU平台尚未提供支持。测试显示,包括联发科天玑9400和高通骁龙8 Elite在内的旗舰SoC,其NPU均无法有效部署标准MoE模型。
基于上述两个发现,团队从训练数据和模型结构两个方面详细探讨了多模态训练过程中保持纯语言性能的方法。
语言性能维持-数据角度
在MLLM训练过程中,保持纯语言能力最直接常用的方法是在训练数据中加入纯文本数据。目前InternVL2.5和Qwen2.5-VL都采用了这种方法。但这种方法存在两个主要问题:一是难以收集大量高质量的纯文本指令微调数据,特别是针对主观性NLP任务的数据;二是在MLLM训练中加入大量纯文本数据会显著增加训练时间。
为了验证该方法的有效性,从ViT与LLM开始全量微调一个MLLM。具体地,模型基于面向手机端部署的BlueLM-V-3B架构,ViT部分使用SigLIP,LLM部分使用BlueLM-3B或Qwen2.5-3B。训练流程参考Cambrian-1,先用提供的250万对齐数据预训练,再用700万数据进行微调。为对比,在微调阶段额外加入200万纯文本数据,主要来自InternVL2.5,如下表所示。

在7个常见LLM测评集和7个常见MLLM测评集上测试了模型的训练效果,得到两个主要结论:

1、加入纯文本数据对多模态能力影响有限
在训练中引入了包含200万样本的额外纯语言数据,发现模型的多模态能力几乎未受影响。这一现象表明,在多模态大模型训练过程中,适量加入纯文本数据对模型的多模态表现并无显著影响。
2、纯文本数据对客观类NLP任务有一定提升,但对主观类任务帮助不大
引入700万多模态数据后,原始语言模型在客观与主观语言任务上的表现均出现明显下降。为缓解这一问题,团队借鉴InternVL2.5的方法,额外加入了200万条纯文本数据进行训练。然而由于目前缺乏足够高质量的人类对齐数据,这部分纯文本仅在客观NLP任务上带来部分性能恢复,对主观任务几乎无帮助。这表明,当前通过添加纯文本来维持语言模型原有能力仍面临较大挑战。
语言性能维持-模型结构角度
上述实验表明,仅靠增加纯文本数据来维持多模态大模型的语言能力效果有限。为此,另一类方法尝试通过架构设计来增强语言表现,例如 CogVLM 和 Wings 采用 MoE结构来提升模型性能。
然而在实际部署中发现,Wings 虽然设计复杂,但纯语言任务性能平均下降超过 20%,无法满足实际应用需求;而 CogVLM 在每个 Transformer 层旁边加上视觉专家模块,并冻结原始语言模型,从而在多模态输入下保持其纯语言能力不变。
尽管这一方式在精度上更稳定,但也存在两大问题:
其一,部署时需同时加载 LLM 和视觉专家模块,显著增加内存开销;
其二,当前手机NPU尚不支持 MoE 模型运行,导致模型难以在移动端真正落地。
这些挑战说明,提升语言能力与实现高效部署之间仍需更好的权衡策略。
为完整评估CogVLM方法在多模态训练中的效果,基于BlueLM-3B和Qwen2.5-3B两种语言模型进行实验。为缓解部署中的内存压力,仅在1/4的Transformer层中加入视觉专家模块,分别尝试插入在前1/4(Pre)、后1/4(Post)和每隔1/4(Skip)的位置。同时,对其余层的注意力和前馈模块加入LoRA权重。在此基础上,将三种CogVLM策略与全量微调和全LoRA训练进行对比,并列出训练中涉及的可学习参数量(包括ViT和投影层)。
这一实验有助于理解不同多模态训练策略在性能和参数效率之间的权衡。得到两个主要结论:
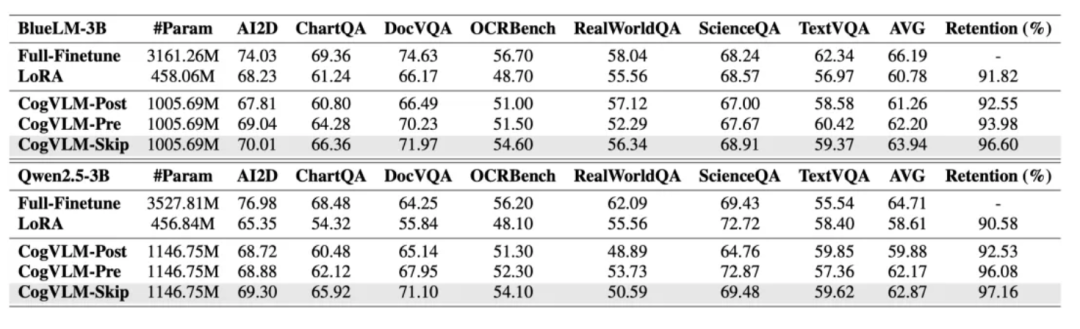
1、与全量微调相比,LoRA 和 CogVLM 方法都会不同程度地削弱多模态大模型的性能。
由于可训练参数数量受限,LoRA 和 CogVLM 的多模态性能仍略低于全量微调,但整体已可达90%以上。其中,CogVLM 在多模态表现上优于 LoRA。值得注意的是,全量微调虽然多模态能力最强,但会显著削弱纯文本任务的效果;相比之下,LoRA 和 CogVLM 采用不共享基座模型的部署策略,在提升多模态能力的同时,能够保持纯文本性能不受影响。
2、对于CogVLM,将视觉专家模块均匀插入至整个模型的1/4层位置,能够实现最佳的MLLM性能表现。
在CogVLM方法中,将视觉专家模块添加到每1/4层的位置(即每隔若干层插入一次,覆盖总层数的1/4),能使多模态大模型的性能达到全量微调的96%以上。同时,CogVLM的训练方式不会影响纯文本任务表现,基于此,团队选择以此方法为基础设计了GenieBlue。
GenieBlue的设计
1、模型结构
基于CogVLM结构进行改进,重点考虑了当前手机NPU对MoE架构的限制。CogVLM的核心思想是将文本和多模态信息分开处理,采用MoE架构由不同专家分别负责文本和视觉Token。而设计原则则绕开MoE,通过为LLM和多模态模型部署选择不同权重,保持原始LLM架构在多模态推理时不变。
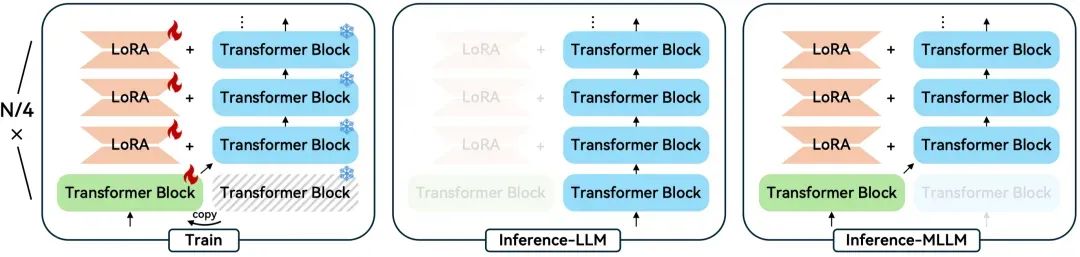
GenieBlue框架如上图所示。为节省手机端模型存储和部署内存,在LLM中每1/4的位置复制一组Transformer层,其余层加入LoRA模块。
在多模态训练阶段,冻结原始LLM,仅对ViT、投影层、复制的Transformer块和新增的LoRA参数进行训练。
推理时采用不共基座的部署策略。纯文本任务使用未修改的原始LLM计算;多模态任务则用训练好的复制Transformer块替换对应层,同时在其余层添加LoRA参数。这种不共基座策略有效避免了MoE架构,将LLM和多模态模型推理解耦。实际NPU部署时,只需替换权重并加载LoRA模块,简化了部署流程,提高了效率。
基于250万预训练数据和900万微调数据,使用BlueLM-3B和Qwen2.5-3B两种语言模型,将提出的GenieBlue与全量微调和CogVLM方法进行了对比评测。
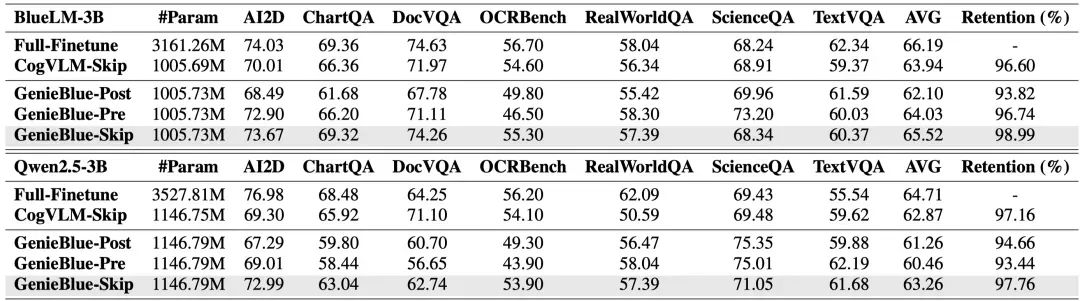
GenieBlue-Skip实现了最佳的多模态性能表现,且优于CogVLM-Skip方法。
2、不共基座部署方案
通过将LLM和MLLM的推理过程分离,采用GenieBlue的不共基座部署策略可以有效保持原始LLM的纯语言能力。
为验证该策略的重要性,在LLM基准测试中对比了共基座和不共基座两种部署方式。共基座表示将LLM和多模态模型推理流程合并,纯文本任务推理时也使用全训练的Transformer层和LoRA模块。此外还展示了BlueLM-3B和Qwen2.5-3B在全量微调和全LoRA训练下的NLP性能。
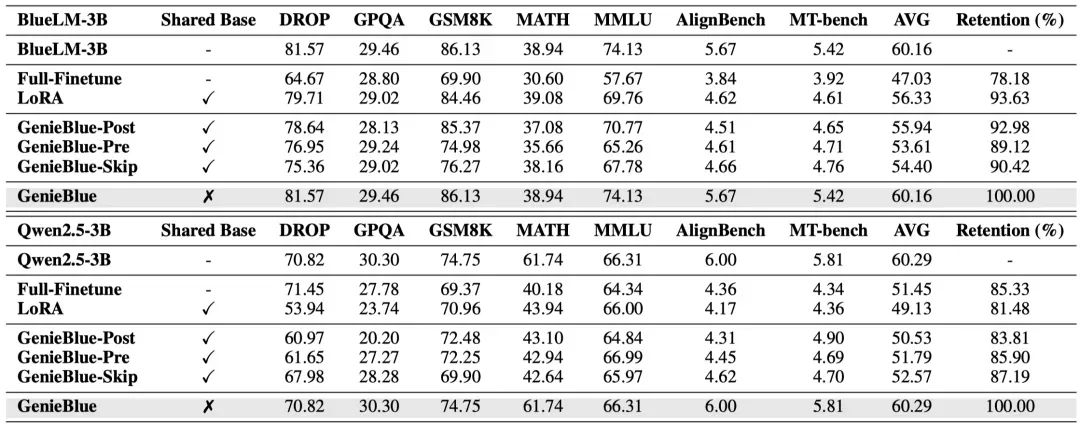
采用不共基座的部署策略,在纯文本任务上表现出显著优于共基座部署的语言能力。
训练和部署方案
基于对训练数据和模型结构的分析,最终确定了GenieBlue-Skip模型结构及不共基座部署策略。
1、训练方案
采用GenieBlue-Skip结构,严格按照BlueLM-V-3B的训练方案和数据进行训练。训练分两阶段:第一阶段使用250万预训练数据,仅训练MLP投影层,冻结ViT和LLM;第二阶段用6.45亿微调数据,微调ViT、投影层、复制的Transformer块及新增的LoRA参数,保持原始LLM冻结。训练中,ViT采用SigLIP,LLM为BlueLM-3B,LoRA秩设置为8。
2、部署方案
将GenieBlue部署在搭载高通骁龙8 Elite(第四代)SoC的iQOO 13手机NPU上,采用高通QNN SDK进行模型部署。ViT和投影层采用W8A16量化,LLM采用W4A16量化,新增的LoRA参数同样使用W8A16量化。目前支持单Patch的ViT推理。需要特别说明的是,骁龙8 Elite的NPU平台暂不支持MoE架构的部署。
GenieBlue的准确率和部署效果
团队验证了GenieBlue的多模态、纯语言准确率以及在手机NPU上的部署效率。
1、多模态准确率
GenieBlue与参数量小于40亿的其他MLLM进行了对比。GenieBlue的多模态准确率略低于Qwen2.5-VL-3B,但保留了BlueLM-V-3B约97%的性能。此外,GenieBlue在平均表现上略优于InternVL2-8B。

2、纯语言准确率
GenieBlue最大特点是采用不共基座部署策略,能够保持原始语言模型性能不受影响。在多个代表性基准测试上对其语言能力进行了评测。作为对比,选择了通过加入纯文本数据保持语言性能的Qwen2.5VL-3B。GenieBlue在语言能力上无任何下降,而Qwen2.5VL-3B尤其在主观任务中存在一定程度的性能退化。这表明,与单纯增加纯文本数据相比,目前探索模型结构设计更有助于维持语言模型的纯文本能力。

3、部署效率
在搭载高通骁龙8 Elite(第四代)SoC的设备上,采用不共基座部署策略实现了GenieBlue,支持单Patch的ViT推理,并展示了BlueLM-V-3B与GenieBlue的部署效率对比。由于增加了LoRA参数,GenieBlue的模型加载时间稍长,存储和内存需求略增,输出速度略有下降,但30token/s的速度完全满足移动设备的日常使用需求。

总结
本文从移动设备实际部署出发,聚焦如何保持纯语言能力,深入分析了训练数据和模型结构两方面的影响,探索有效策略。基于这些分析提出GenieBlue——专为移动端打造的高效且硬件友好的多模态大模型,能够融合语言理解与多模态能力。GenieBlue在训练时冻结原始语言模型参数,利用复制的Transformer层和轻量的LoRA模块获得多模态能力,既保持了语言性能,又实现了有竞争力的多模态表现。在智能手机NPU上的部署验证了其实际可行性和高效性,是移动端边缘计算的有力解决方案。团队期待此项工作为该领域未来研究带来有益启示。
论文地址:
https://arxiv.org/pdf/2503.06019
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)