

FOT团队 投稿
量子位 | 公众号 QbitAI
大模型越来越大,通用能力越来越强,但一遇到数学、科学、
为破解这一痛点,华为诺亚方舟实验室提出全新高阶推理框架 ——思维森林(Forest-of-Thought,FoT)。
该方法借鉴人类“多角度思考、反复验证”的认知方式,
论文将在7月份召开的ICML 2025大会上发表和开源。

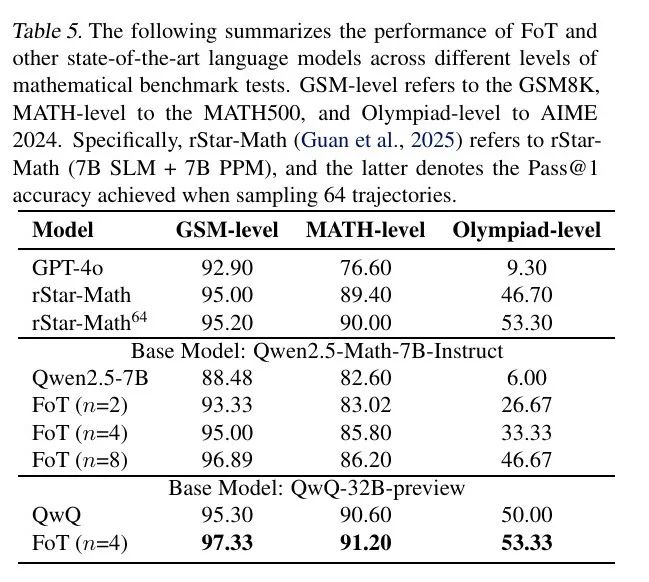
在此基础上,FoT在多个数学推理任务中表现突出,
具体而言,在GSM8K数据集上,结合FoT的QwQ-
思维森林:让大模型像人一样“思维分叉+自我反省”
尽管LLM在语言理解、问答等任务中表现出色,但在数学和逻辑等
-
常陷入“单路径”惯性,缺乏反思与尝试其他思路的能力;
-
中间步骤易出错,且错误难以自我纠正;
-
无法有效整合多种解法来做集体判断,缺乏“共识感知”。
思维森林FoT框架的核心灵感来自人类解决复杂问题的过程:头脑
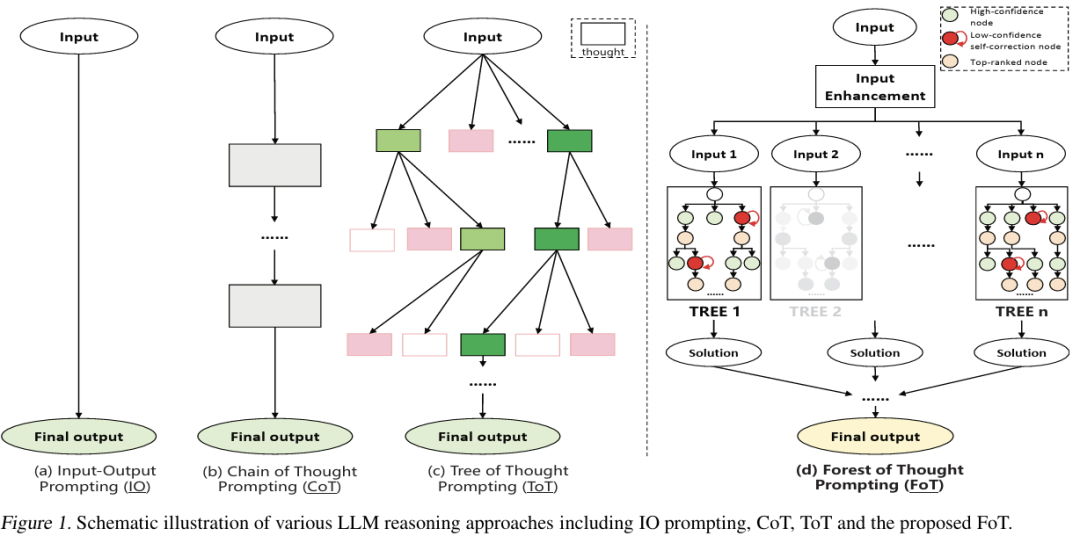
FoT模型在推理时并行构建多棵推理树,
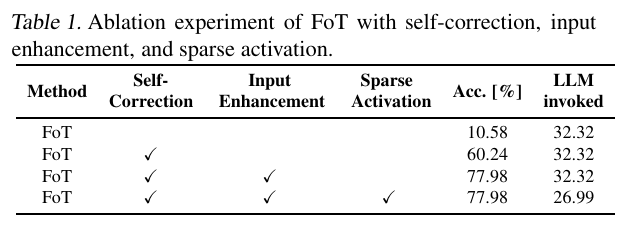
稀疏激活(Sparse Activation)
在传统的多路径推理中,虽然激活所有可能路径可以提升覆盖率,
FoT引入了稀疏激活策略,其核心思想是在每一层推理过程中,
该机制显著减少了每层的推理分支数量,
动态自校正(Dynamic Self-Correction)
FoT中每棵推理树在成长过程中,具备对自身推理状态的“反省”
该模块检测推理路径中可能出现的偏差(回答不断重复等)
共识引导决策(Consensus-Guided Evaluation and Decision)
FoT的最终输出不仅依赖于某一条推理路径,
每棵推理树在独立推理后都会生成一个候选答案。
CGED首先尝试从中识别出多数一致性结果(
若不存在明显的一致性(如每棵树的结论差异较大),
该评分模型可基于答案的逻辑连贯性、对问题的契合度、
这一机制有效结合了“集体智慧”与“专家审阅”,
实验亮点:比思维树更强、更稳、更聪明
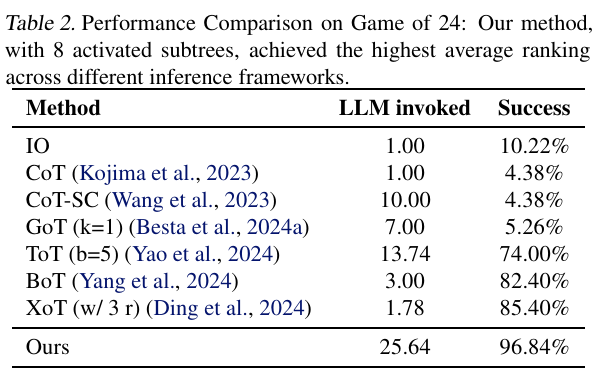
在GSM8K、MATH等经典推理任务中,FoT显示出超越ToT的表现:
在24点游戏任务中,FoT增加树数即可提升14%准确率,明显优于ToT通过叶子节点数量扩展的方式。
在GSM8K数学问答上,FoT与LLaMA3、Mistral、GLM等多个主流开源模型兼容,树数越多,性能提升越明显,呈现全新的推理scaling law曲线。
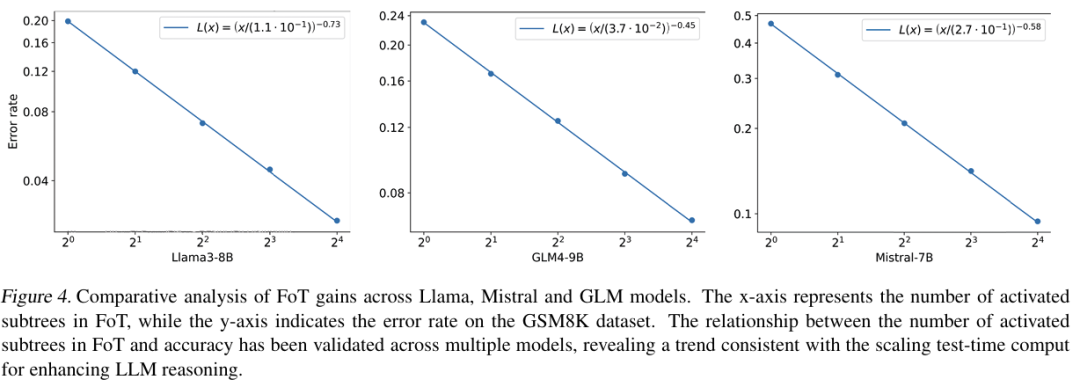
在MATH数据集全等级上,FoT推理准确率稳定提升,即使面对最复杂的问题也能保持优势。
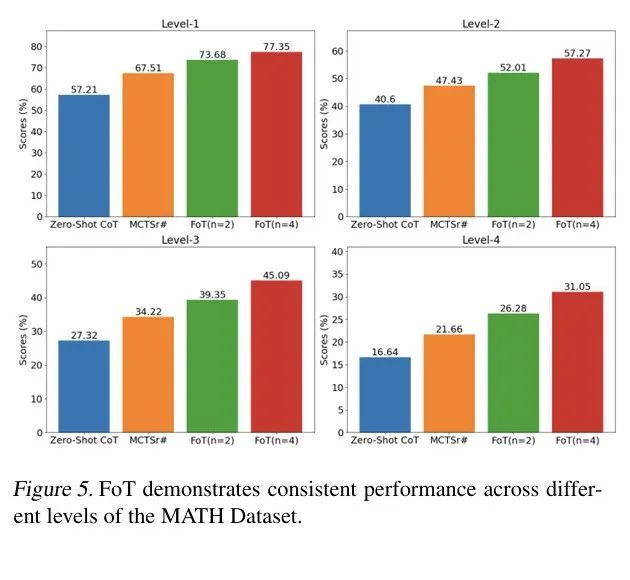
总结:从更聪明,到更可信
FOT是一种面向大语言模型的推理增强框架,
不仅如此,该方法旨在缓解传统大模型在高阶推理场景中的局限,
论文链接:https://arxiv.org/abs/
项目地址:https://github.com/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)