


极市导读
南开大学与新加坡科技局等机构提出低分辨率自注意力(LRSA)机制及LRFormer模型,通过在固定低维空间计算全局注意力,大幅降低计算开销,同时在ADE20K、COCO-Stuff和Cityscapes等数据集上取得领先性能,为语义分割领域提供了高效新范式。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
导读
语义分割是计算机视觉的一项核心任务,Vision Transformer在该领域取得了显著进展。然而,其核心的自注意力机制在处理高分辨率特征图时,会产生高昂的计算成本,这一直是制约其应用和发展的一个关键瓶颈。那么,我们是否必须在如此高的分辨率上捕捉全局上下文信息呢?针对这一问题,南开大学与新加坡科技局等机构联合提出了一种新颖的低分辨率自注意力(Low-Resolution Self-Attention, LRSA)机制,并据此构建了一款高效的语义分割新模型——LRFormer。该方法的核心思想是将自注意力的计算固定在固定的低维空间中,从而显著降低计算开销。实验表明,LRFormer在ADE20K、COCO-Stuff和Cityscapes等主流数据集上取得了领先的性能。此外,该方法还被成功应用于视觉语言模型,展示了其良好的通用性与应用潜力。
论文标题**:** Low-Resolution Self-Attention for Semantic Segmentation
收录期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025作者:Yu-Huan Wu, Shi-Chen Zhang, Yun Liu, Le Zhang, Xin Zhan, Daquan Zhou,Jiashi Feng, Ming-Ming Cheng, and Liangli Zhen
单位:南开大学,新加坡科技研究局,电子科技大学,有鹿机器人,北京大学,字节跳动
论文链接:
https://mmcheng.net/wp-content/uploads/2025/06/25PAMI_LRFormer.pdf
代码链接 (已开源):
https://github.com/yuhuan-wu/LRFormer

Part 1. 引言
语义分割的目标是为图像中的每个像素分配一个语义标签。传统的基于CNN的方法和现代基于Transformer的方法都普遍认为,高分辨率特征图是确保分割精度的关键。虽然Vision Transformer因其强大的全局感受野能力在分割任务中表现出色,但其自注意力机制的计算复杂度与输入序列长度(即分辨率)的平方成正比,这带来了巨大的计算开销。
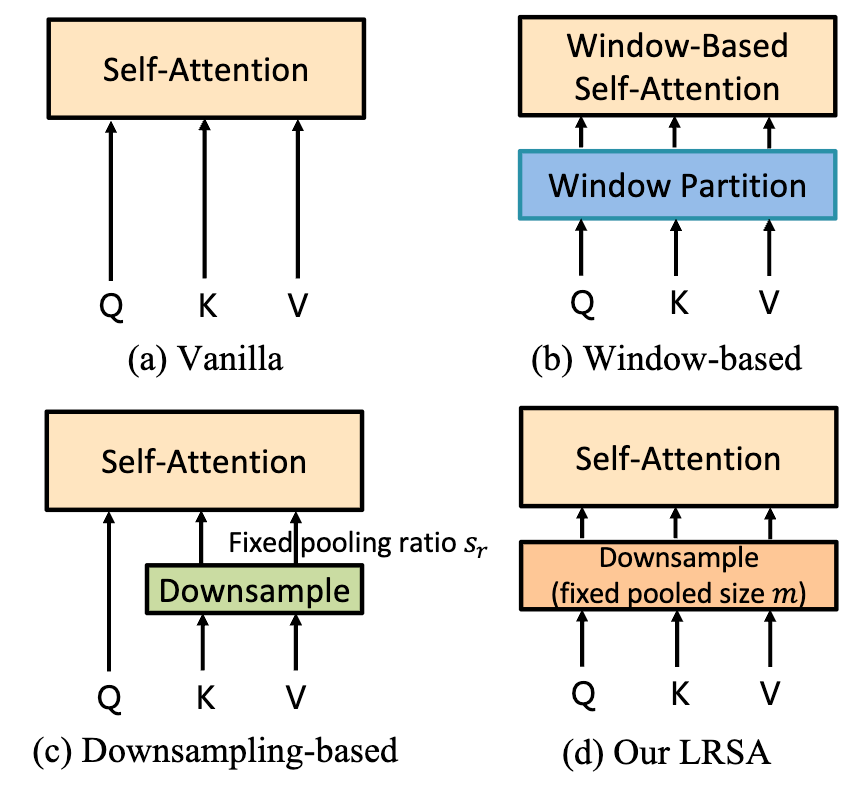
为了缓解这个问题,之前的工作主要有三种范式(如下图所示):
1. Vanilla(原始):直接在原始分辨率上计算全局注意力,计算成本极高 。
2. Window-based(基于窗口):将特征图划分为多个小窗口,在窗口内部分别计算注意力,限制了全局信息的交互 。
-
Downsampling-based(基于下采样):保持Query(查询)的分辨率不变,仅对Key(键)和Value(值)进行固定比例的下采样 。这种方法虽然降低了部分计算量,但计算开销仍然不可忽视,尤其是在处理高分辨率输入时。
我们不禁要问:为了捕获全局上下文,自注意力真的需要在高分辨率空间进行计算吗?
本文的工作给出了一个创新性的答案 。我们提出将Query、Key和Value全部下采样到一个固定的、极小的尺寸进行注意力计算,同样可以提取图片的全局信息 。这种方法,我们称之为低分辨率自注意力(LRSA) 。
Part 2. LRFormer方法介绍
1.低分辨率自注意力 (Low-Resolution Self-Attention, LRSA)
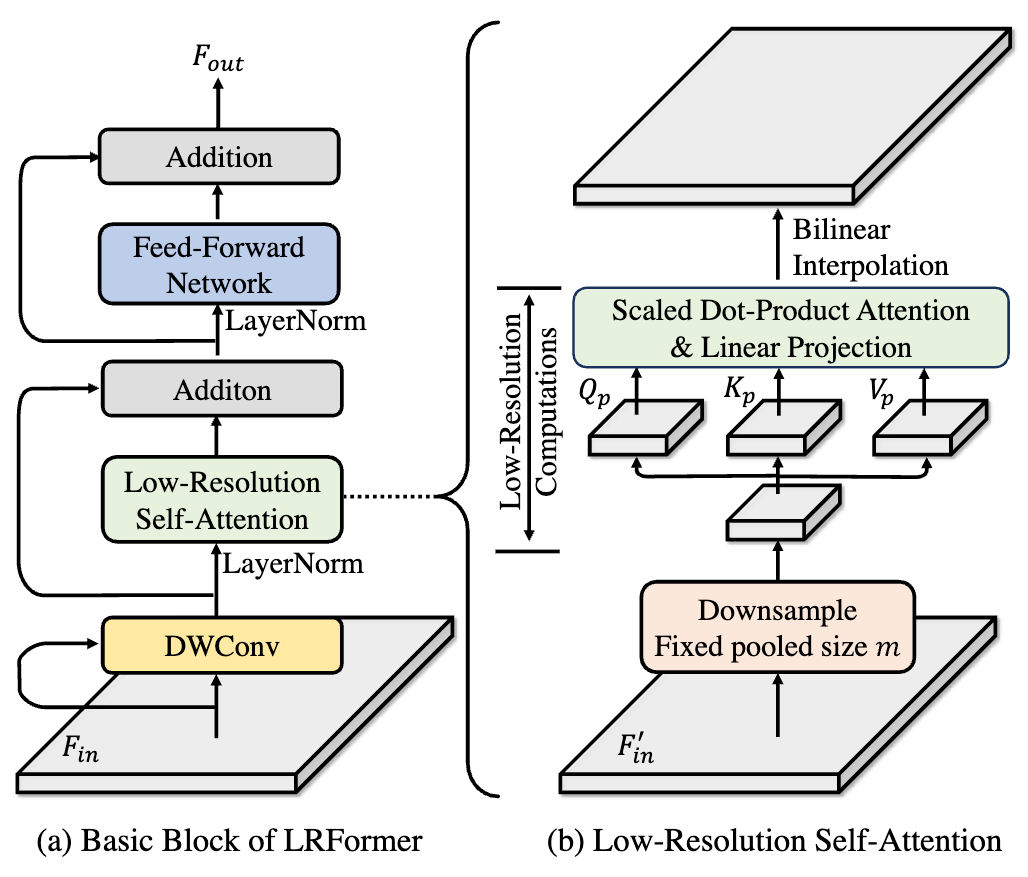
与以往的方法不同,LRSA彻底摆脱了对高分辨率特征图的依赖,其核心思想是在一个极低分辨率的空间中高效地计算全局注意力 。
标准的自注意力(Vanilla Self-Attention)计算公式如下:
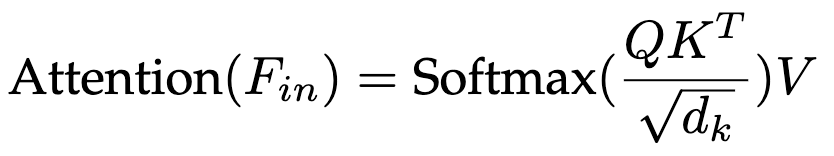
其中Q, K, V由输入特征Fin线性变换而来,计算复杂度为。
为在保持特征图高分辨率的同时降低计算成本,近年来的下采样式视觉Transformer方法(如PVT和P2T)将自注意力的计算方式修改为:
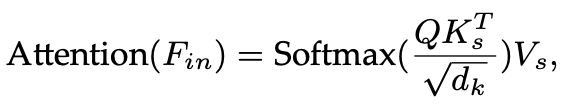
其中, 等特征的序列长度为原始 K 和 V 的 倍。然而,如果原始的 K 和 V 长度本身就很大,即使经过下采样,前者仍然可能是较长的序列,进而在自注意力计算中引入大量的计算开销。
我们的LRSA则从根本上改变了这一流程。
核心机制:对于输入的特征图 Fin,LRSA首先将其通过池化操作下采样到一个固定的尺寸m(例如 16×16)。随后,所有的注意力计算都在这个低维空间中完成 。其计算公式变为:
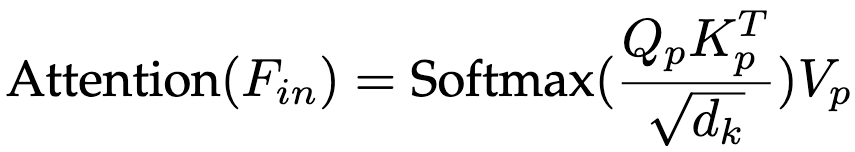
其中,Qp,Kp,Vp 是从池化后的特征图线性变换得到的,它们的序列长度始终是一个小常数m 。最后,通过双线性插值将结果上采样回原始分辨率,并与原始输入进行残差连接 。
计算复杂度:LRSA的计算复杂度仅为 。其中N是输入token数,C是通道数。由于池化后的尺寸m是一个小常数,使得注意力部分的计算开销与输入分辨率N完全解耦,远低于现有方法。
局部细节补偿:为了弥补在低分辨率空间计算可能丢失的局部细节,我们在LRSA模块前加入了一个并行的 3×3 深度可分离卷积(DWConv)分支,用于在高分辨率空间捕捉精细的局部特征 。
2. LRFormer整体架构
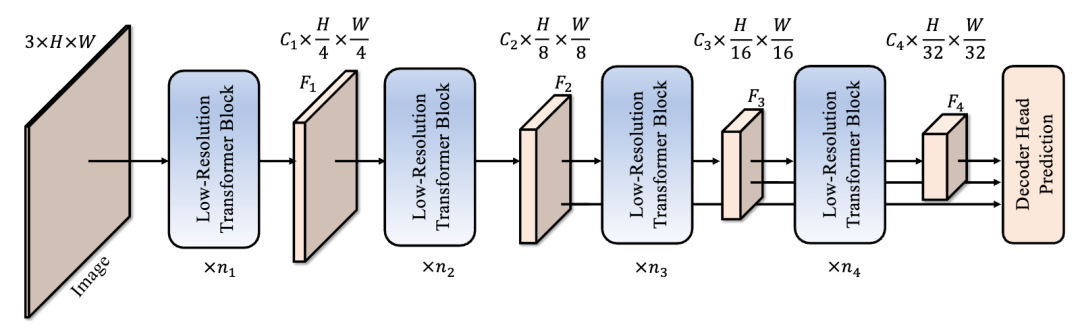
我们基于LRSA构建了一个强大的语义分割模型——LRFormer,它采用经典的编码器-解码器架构。
·编码器:由四个阶段组成,构建了一个金字塔形的特征层次结构 。每个阶段由多个我们设计的基础模块堆叠而成。在阶段之间,使用标准的Patch Embedding操作将特征图尺寸减半 。其计算流程可以精确地表述为 :

·解码器:我们设计了一个简洁高效的解码器头。它首先将编码器输出的多级特征(F2, F3, F4)统一到相同尺寸并进行拼接 。接着,我们再次利用一个LRSA基础模块对融合后的特征进行增强,以加强语义推理能力 。最后通过一个 1×1 卷积输出最终的分割图 。
Part 3. 实验结果
我们在三大主流语义分割基准数据集(ADE20K, COCO-Stuff, Cityscapes)和图像分类基准(ImageNet)上进行了详尽的实验,结果充分验证了LRFormer的卓越性能和效率 。
1. 与SOTA模型的比较
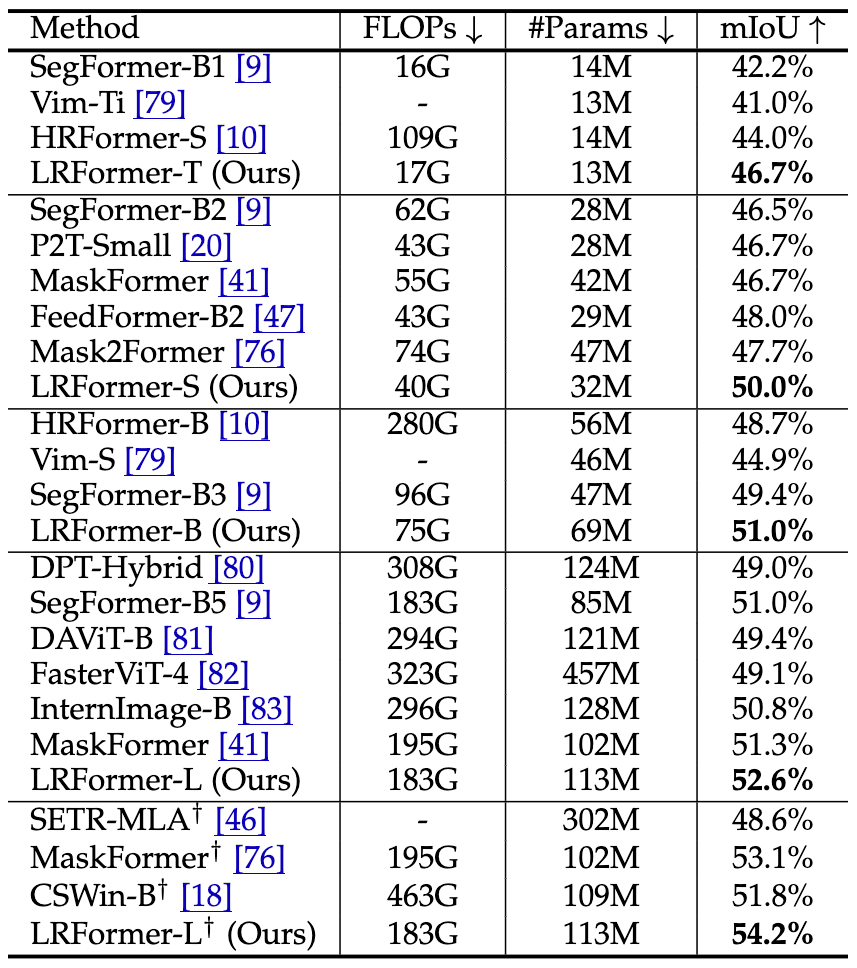
LRFormer在不同规模的模型上(T/S/B/L)均表现出强大的竞争力,实现了性能和效率的完美平衡。
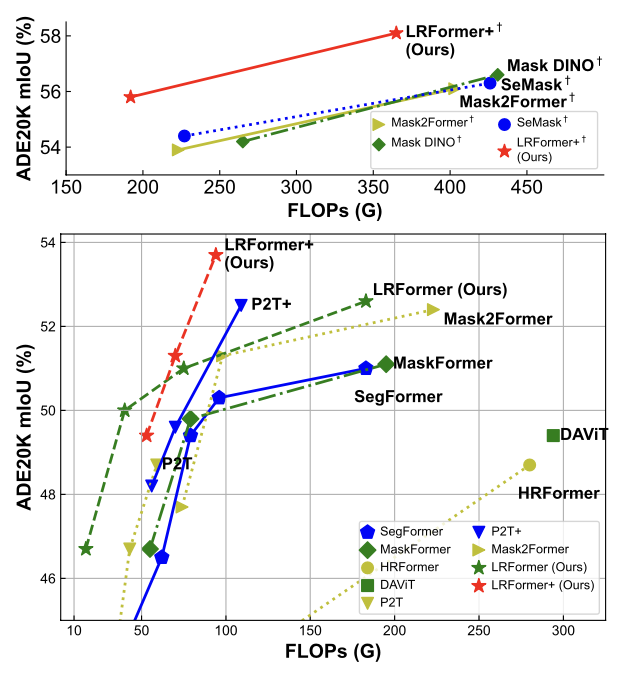
·ADE20K:如图4所示,LRFormer的性能-FLOPs曲线全面优于所有对比方法 。例如,LRFormer-L在和SegFormer-B5 FLOPs相同的情况下,mIoU高出1.6% 。即便是与基于ImageNet-22K预训练的更强的模型(如MaskFormer, CSwin)相比,LRFormer-L依然能以更低的计算量取得1.1%至2.4%的性能优势 。
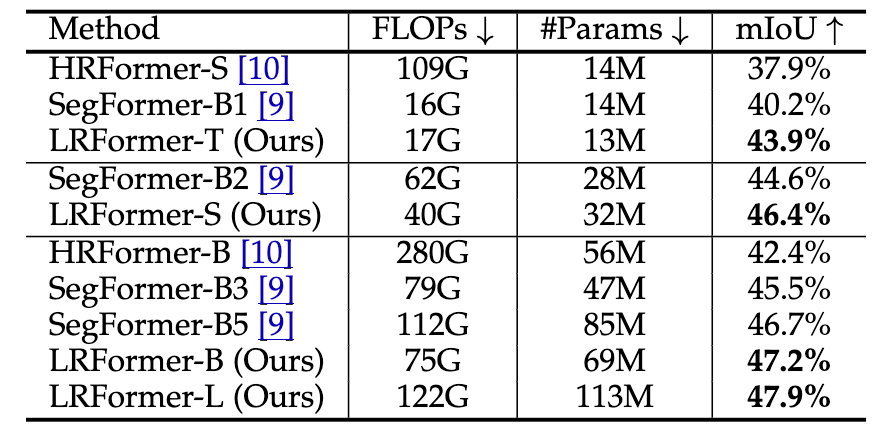
·COCO-Stuff:LRFormer在所有模型规模上都取得了最高的mIoU,全面超越了SegFormer和HRFormer 。
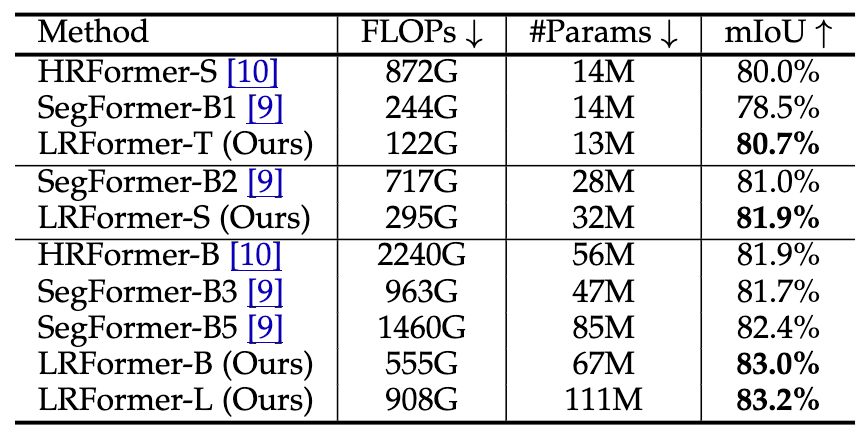
·Cityscapes:该数据集输入分辨率高,更能体现LRFormer的效率优势 。例如,SegFormer-B2需要717G FLOPs,而我们的LRFormer-S仅需其41%的计算量(295G FLOPs),mIoU还高出0.9% 。
2. 可视化分析
从下图的分割结果可以看出,相比于强有力的基线模型SegFormer,LRFormer能够生成更完整、更精确的分割图,尤其是在物体边界和细节区域(红框所示)。

3. 消融实验
我们通过一系列详尽的消融研究,验证了LRFormer设计的合理性 。
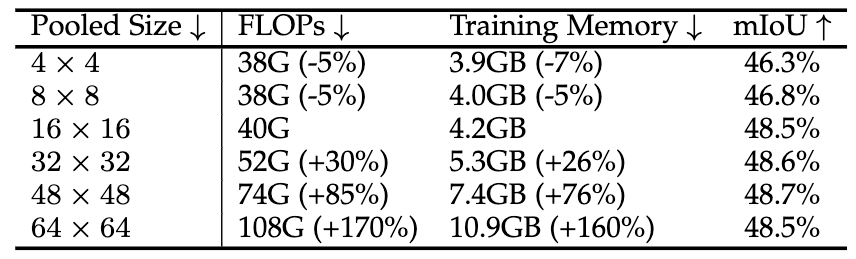
·固定的池化大小:实验表明,当池化尺寸大于等于 16×16 时,性能趋于饱和 。继续增大尺寸只会带来巨大的计算和内存开销,但性能提升甚微甚至下降 。因此,我们默认采用 16×16 作为固定池化尺寸。
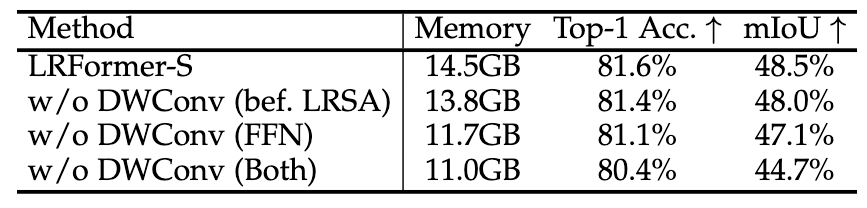
·局部性信息的捕获:DWConv对于捕捉局部细节至关重要。实验证明,在LRSA前和FFN中加入DWConv分别带来了0.5%和1.4%的mIoU提升 。若同时移除,性能会大幅下降3.8% 。
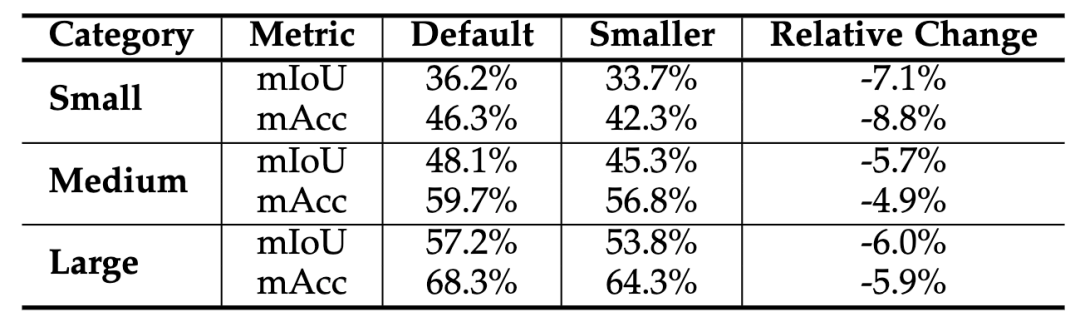
·小物体上的性能:我们将物体按尺寸分为小、中、大三类进行分析 。结果显示,如果将池化尺寸减小到 4×4 ,所有类别的性能都会下降,其中小物体受影响最大 。这证明我们默认的 16×16 设置能够在不牺牲小物体细节的前提下高效工作。
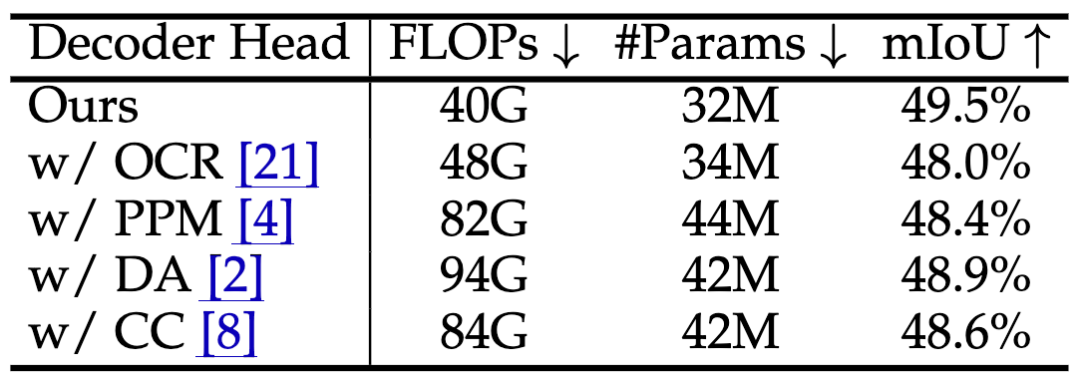
·解码器头对比:我们将LRFormer的解码器与其他流行的解码器头(如PPM, DA, CC, OCR)进行了公平对比 。结果显示,我们的解码器在FLOPs远低于对手的情况下,取得了更好或相当的性能 。
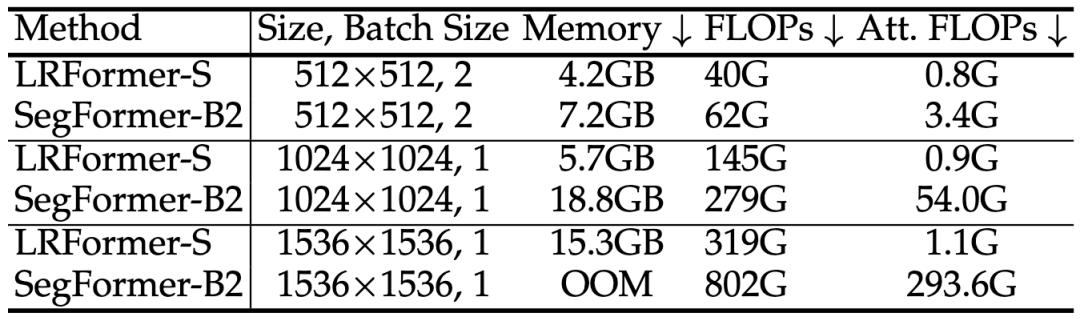
·内存与FLOPs分析:我们详细分析了LRFormer和SegFormer在不同输入分辨率下的资源消耗 。如下表所示,随着输入尺寸从 512 增加到 1536 ,SegFormer的注意力计算FLOPs从3.4G飙升至293.6G,而LRFormer始终保持在1.1G左右,展现了巨大的效率优势 。
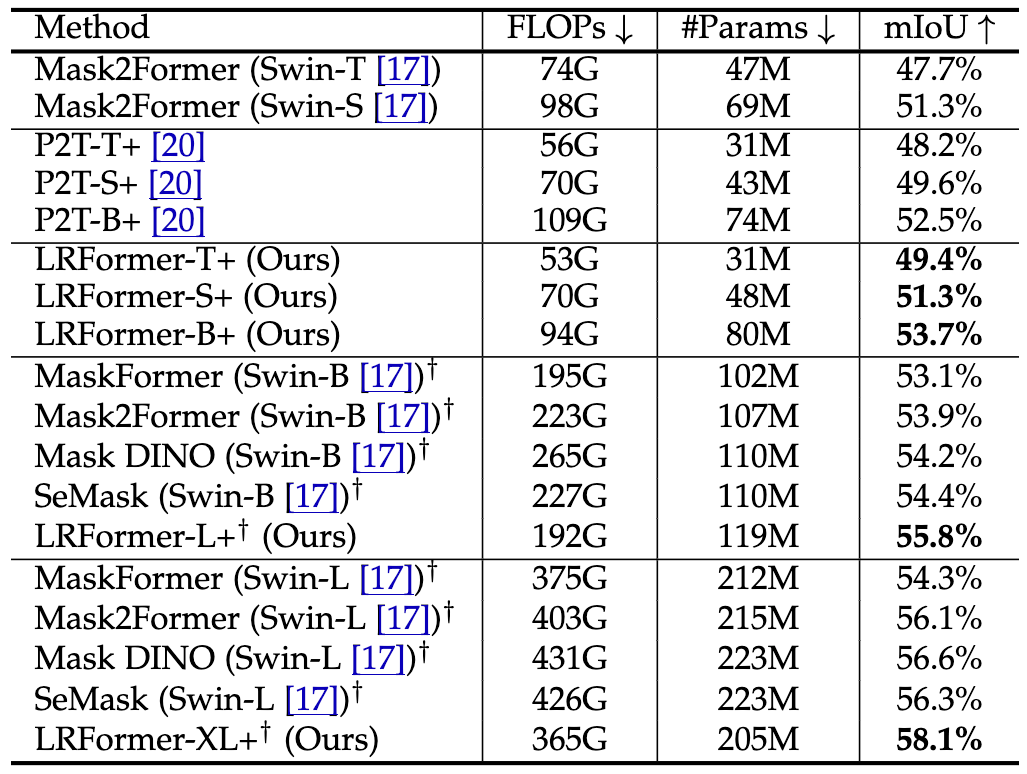
·更先进的LRFormer+:为了探索LRFormer编码器的潜力,我们将其与强大的查询式解码器Mask2Former结合,构建了LRFormer+ 。在ADE20K上,LRFormer+全面超越了Mask2Former、Mask DINO等SOTA模型,再次证明了我们编码器设计的优越性 。例如,LRFormer-B+比强大的P2T-L+版本还要高出1.2% mIoU 。
4. 应用到视觉语言模型
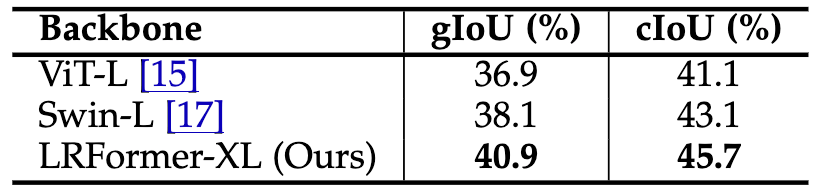
为了验证LRFormer的通用性,我们将其应用于新兴的推理分割任务中 。我们将LISA模型的视觉骨干网络分别替换为ViT-L、Swin-L和我们的LRFormer-XL 。
如下表所示,使用LRFormer-XL作为骨干网络,在gIoU和cIoU指标上分别比Swin-L高出2.8%和2.6%,比ViT-L高出4.0%和4.6% 。这一结果有力地证明了LRFormer不仅在传统的语义分割任务上表现卓越,其强大的特征提取能力同样能够赋能更复杂的视觉语言模型,具有广泛的应用潜力 。
Part 4. 结论
本文提出了一种新颖高效的低分辨率自注意力(LRSA)机制,并基于此构建了LRFormer模型 。我们挑战并证实了“在注意力计算中保持高分辨率并非捕获全局上下文的必要条件”。通过在一个固定的低分辨率空间进行注意力计算,LRFormer在大幅降低计算成本的同时,在多个主流语义分割基准上取得了SOTA性能 。这项工作不仅为设计高效的视觉Transformer提供了新的思路,也为未来在更多视觉任务中的应用打开了想象空间。
(文:极市干货)