

极市导读
从loss landscape的角度探究大模型! >>加入极市CV技术交流群,走在计算机视觉的最前沿
如果对background非常熟悉的话,非常强烈建议直接跳到Sec. 3! 相信这会让您更有兴趣阅读这篇文章!
Too Long, Don’t Read:
在本篇博客中,我们大家一起从loss landscape的角度探究了大模型。非常好玩的是,大模型的landscape是basin而不是平滑的,在某个区域内能力基本一模一样,出了这个区域就gg。而且pre-train会给一个basic capacity basin。后续的SFT会在里面创造math basin,coding basin, reasoning basin, safety basin等等。因此我们猜想,在basin内SFT并不会损失性能,而损失性能则是因为fine-tuning距离出了basin。我们通过Clopper Pearson bound发现99.9%的方向都是差不多的,basin size都一样,只有0.1%的方向会比较烂,并且通过RS技术让大多数方向平滑了这些差方向,从而使得大多数方向都差不多好~

而大模型的landscape是这样的!:

引言
你是否遇到过这种情况:一个好端端的模型(例如Llama-3, Qwen-2),我就想增加一下它的安全能力,结果在我自己的安全数据集上fine-tune完之后,它的数学能力、推理能力退化了好多?


你又是否遇到过这种情况:很对偶的,一个好端端的模型(例如Llama-3, Qwen-2),我就想增加一下它的数学能力,结果在我自己的数学数据集上fine-tune完之后,它的安全能力直接没了?直接就开始回答how to make a bomb了?
甚至,只要在10条数据,总长度小于1000的恶意数据上fine-tune,模型就可以回答任何你问的恶意问题?

如果说fine-tune模型是因为模型本身就有足够的学习能力,所以会倾向于学习新的东西,这就算了。可是为什么完全不fine-tune模型,只去fine-tune模型的输入,也能让模型回答任何你问的问题呢?

或许从Loss Landscape的角度可以解释这些问题!
Loss Landscape
Loss landscape是对神经网络这个高维函数的一个可视化。即,当参数变化时,模型的loss如何变化。
可是模型的参数(如7B)很大,想要完全画出来不现实。因此我们往往会选择2个或者1个随机方向来画loss landscape,即:

为什么这样做是合理的,是因为对于,深度学习中大多数模型和大多数任务,大多数方向的loss变化几乎没有任何差别。 因此,随机可视化一个方向,就已经代表了大多数方向上loss的变化。
以往我们看到的小模型loss landscape是这样的:
小模型上loss landscape也给了我们很多启示,如越平坦的地方往往抗扰动能力越强,如果假设测试集的landscape是训练集的平移,那么越平坦的极小值点,就更容易是泛化性更好的极小值点。再比如,如果收敛到各个loss比较接近的点,模型往往能学的比较融会贯通,从而得到更好的智能:
landscape还有什么性质与泛化性有关?ICLR 2024(https://zhuanlan.zhihu.com/p/680197033)
那么,大模型的loss landscape是什么样的呢?也是和小模型有平坦、尖锐、平滑的样子吗?
大模型的most-case loss landscape
非常不一样的是,大模型的loss landscape和小模型截然不同。大模型的loss landscape就像一个Basin(盆地)一样,在盆地内部,模型的效果基本没有任何变化(这岂不是意味着在盆地内部怎么移动都不怎么影响性能?)。出了盆地,模型的能力就完全消失,直接输出乱码了。。
我们可以画一画模型不同能力的landscape~你总是能发现,pre-training basin会给模型一些基础的语言对话能力。而后续的alignment,都是在pre-training basin内部,创造一个又一个的小basin, 如math basin, coding basin, safety basin等:
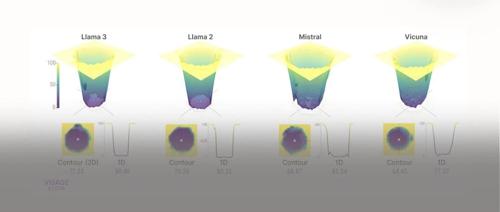
像llama-3和qwen可能alignment做的非常充分,alignment所trigger的能力(如safety/math/coding)基本和basic capacity basin一样大了:
而Mistral模型就截然不同。他Basic capacity basin比另外两位小也就算了,后续alignment的各种能力,如math/coding/safety全都比basic capacity basin小一截。这岂不是说,只要你沿着大多数方向走(fine-tune也好,还是attack也好),轻而易举的就走到了math/coding/safety能力全没了但是还能正常对话的模型上?
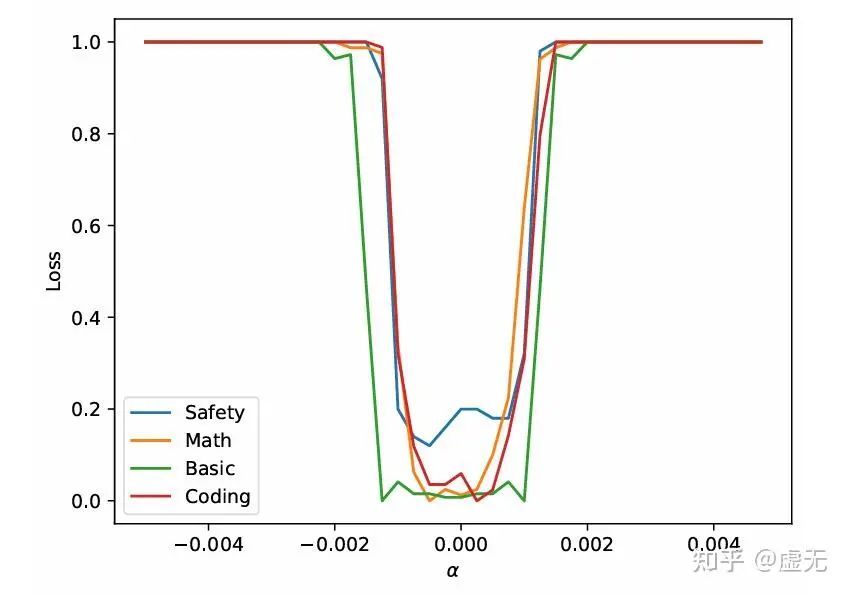
从上面的分析来看,Basin大似乎是一件好事。因为如果Basin大,这就意味着沿着大多数方向走,模型的能力是在这个范围内是不会有任何下降的。而这个大多数方向可以通过Clopper Pearson Bound给出下界,例如99.9%的方向均是如此!(对应Clopper Pearson Bound第一类错误0.001,见附录)
这就意味着,只要你fine-tune是在这99.9%的方向里,只要你在basin内fine-tune,那么你就一定不会compromise任何性能!当且仅当你fine-tune的距离太远了,以至于出了basin,才会compromise性能!
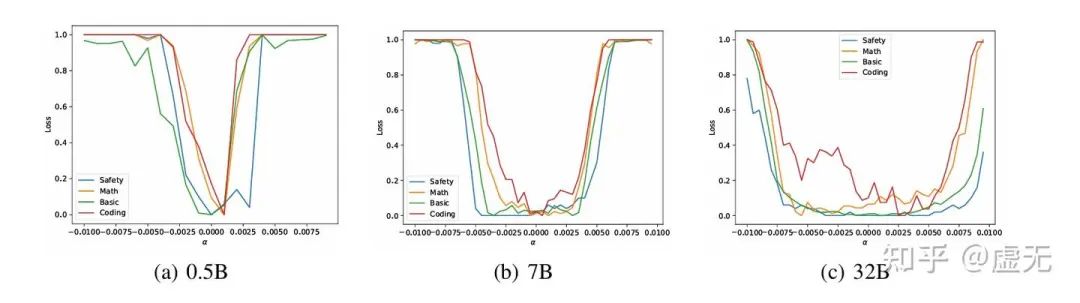
而我们也可以轻易发现,越大的模型确实basin就越大,就越不容易在后续的fine-tune中compromise 之前所得到的性能!
大模型的worst-case landscape
这虽然能解释为什么fine-tuning会遗忘(因为他们tune出了basin,basin越小的模型越容易fine-tune后遗忘),可是如何解释使用仅仅10条对抗数据去fine-tune,总token数都不到1000,模型就直接把安全能力全忘了呢?难道1000token的训练量已经足够让模型走到basin外面了吗?
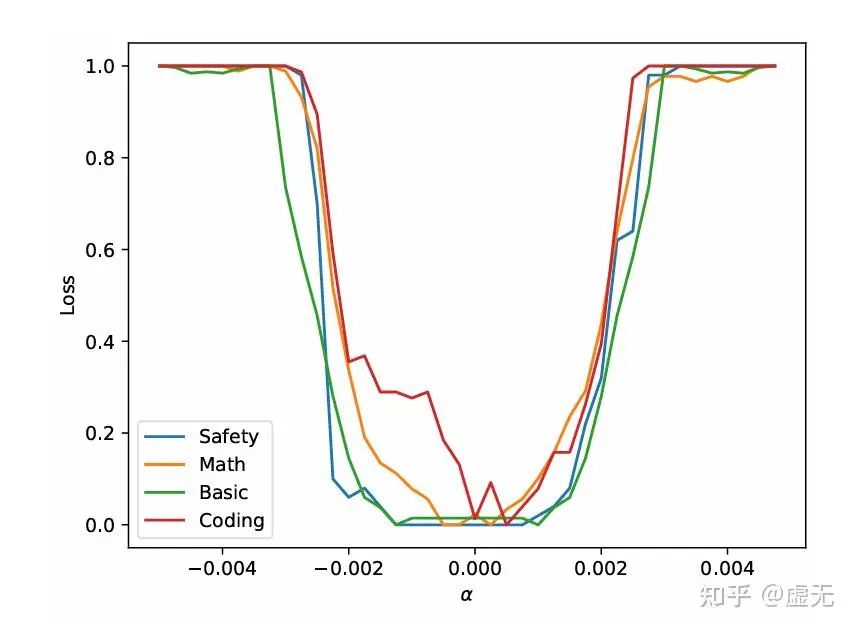
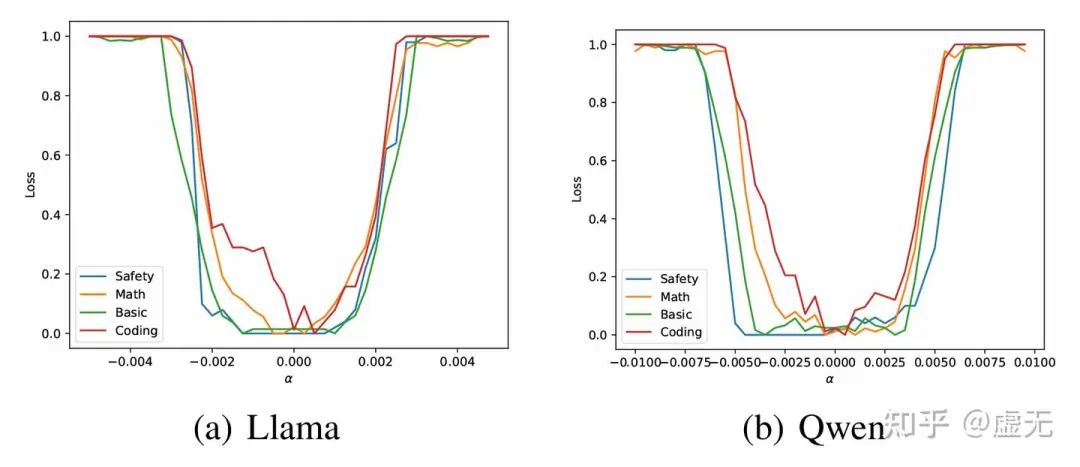
这其实很好解释。因为如果使用对抗的数据,模型SFT的走向也根本不是这99.9%的大多数方向(most-direction),而是最差方向:
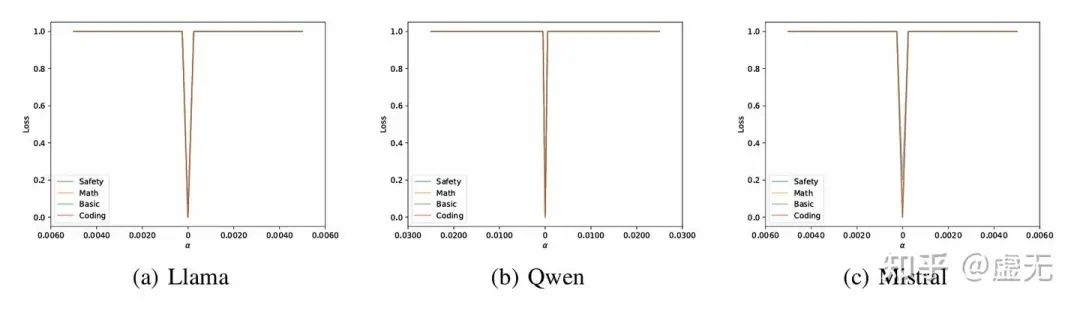
我们可以看到,不论是啥模型,什么能力,只要你沿着最差的方向走,走一点点,模型所有能力就全没了。。所以这最差方向是真的差。
最差方向为什么会如此之大呢?这其实有一种简单理解。因为维度实在是太大了(7B模型就是70亿的维度)。总有一些维度会特别特别的差。当维度足够多的时候(采样次数足够多),你总能找到个巨差的方向。其实对抗样本的成因亦是如此。甚至,这里肯定会比对抗样本的最差方向更差。因为对抗样本是输入空间,就算是图像也只有3x256x256<256k维度。而这里可是实打实的7B维度,比前面大了100000倍呢!
对抗样本和landscape的联系
刚刚我们已经解释了为什么正常的fine-tuning会导致遗忘(因为tune出basin了),以及为什么对抗数据可以迅速遗忘(因为走的最差方向)。那么为什么不是tune参数,而是优化输入,也能导致模型输出任何你想要的输出呢?
这其实很好理解。因为对抗样本这种优化输入,和fine-tuning这种优化参数(包括第一层参数),其实没啥区别!
我们来考虑第一层线性层。如果你能通过tune第一层线性层来使得模型g掉的话:
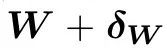
那么你也一定能通过修改输入来使得模型g掉:
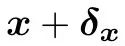
这是因为当第一层列满秩的时候,两种扰动可以在第一层的activation space产生相同的向量。
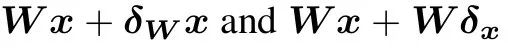
至于为什么第一层是列满秩,这是因为模型总是倾向于利用全部的空间来储存信息,至少要把所有维度都利用完才开始superposition。这一点我们在之前的博客中一起探索过:
真的能偷GPT-4等商用模型的参数吗?(https://zhuanlan.zhihu.com/p/917520808)
因此,我们成功解释了我们一开始的三个问题!为什么正常的fine-tuning会导致遗忘(因为tune出basin了),以及为什么对抗数据可以迅速遗忘(因为走的最差方向),为什么tune输入也能GG(因为tune输入和tune weight没啥本质区别)
一些理论性质
到现在大家可能会觉得模型大多数方向(99.9%)都挺好,就是剩下那极少数的方向坏了事情。但非常好玩的一件事是,其实可以有一种方法,让你直接通过大多数方向的性能,来lower bound住极少数方向的性能!
比如说我们的模型在 的范围内,大多数方向都表现差不多:
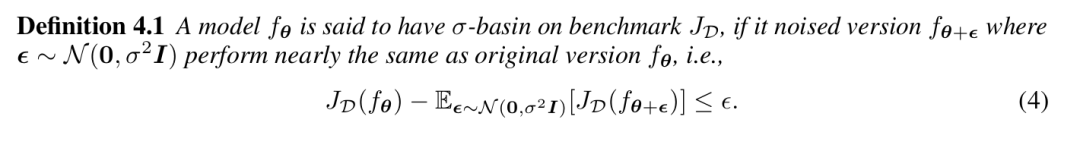
那我们实际上就可以通过RS这项技术,在不损失任何大多数方向性能的情况下,保障你最差的方向的degradation不会超过 的fine-tuning距离!

举个例子,比如说你SFT距离是1,那么就可以保障你的performance degradation一定不会超过
这里的intuition是,因为大多数方向都很好,我们就可以用大多数方向(most-case direction)来平滑掉那个”worst-case direction”。具体推导和证明我们在之前也一起探究过:
证明LLM的鲁棒性下界就是在解0-1背包问题?(https://zhuanlan.zhihu.com/p/21266930786)
扩散模型是不能被攻击的(https://zhuanlan.zhihu.com/p/12592746504)
我们带入我们之前的结果,就可以轻而易举的得到更强的result(这个result其实很重要,保障了越强的能力变化越小,越弱的能力变化越多。能力越趋近于1,sft后的损失越趋近于0)

因此,我们相当于得到了对于沿着任何方向SFT的性能保障。既然我们有对参数空间的保障,那根据我们最开始的分析,也可以得到输入空间对对抗攻击的保障!(其实就是把等价的参数变化带进来。。。没啥高端的。。)
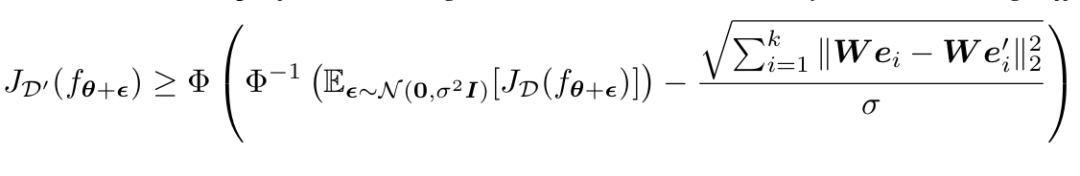
大模型的basin可以轻易增大
通过上述分析,我们感觉basin大好处多多。既可以在正常的fine-tuning下有更强的表达能力(可以用Rademacher Complexity更严谨的来说),并且还不会遗忘,而且还能抵抗特别脏的数据的fine-tuning,而且还能对用户特意造的输入这种对抗攻击有鲁棒性。那么,我们是否可以增大basin呢?
其实直接优化我们刚刚一起定义的basin大小,即definition 4.1即可!
优化器我想大家都能异曲同工地设计出同一个来:

结语
在本篇博客中,我们大家一起从loss landscape的角度探究了大模型。非常好玩的是,大模型的landscape是basin而不是平滑的,在某个区域内能力基本一模一样,出了这个区域就gg。而且pre-train会给一个basic capacity basin。后续的SFT会在里面创造math basin,coding basin, reasoning basin, safety basin等等。因此我们猜想,在basin内SFT并不会损失性能,而损失性能则是因为fine-tuning距离出了basin。我们通过Clopper Pearson bound发现99.9%的方向都是差不多的,basin size都一样,只有0.1%的方向会比较烂,并且通过RS技术让大多数方向平滑了这些差方向,从而使得大多数方向都差不多好~
本篇博客的研究内容都来自于这篇论文。如果对您有启发,或是对研究成果有不同的观点,欢迎评论区和我一起探究呀!
Understanding Pre-training and Fine-tuning from Loss Landscape Perspective
https://arxiv.org/abs/2505.17646
所有非本人画的图均已经标明出处(侵删)。非常感谢这些工作的启发:
[1] Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
[2] Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow InstructionsSafety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
[3] Navigating the Safety Landscape: Measuring Risks in Finetuning Large Language ModelsNavigating the Safety Landscape: Measuring Risks in Finetuning Large Language Models
(文:极市干货)