
AK之前提出“氛围编程”(vibe coding)现在大火特火,今天AK又造新词了,这次是“上下文工程”(Context Engineering)
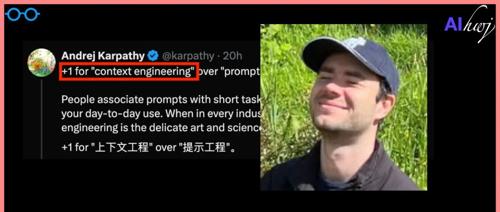
Andrej Karpathy 力挺用“上下文工程”(Context Engineering)来取代日益流行的“提示词工程”(Prompt Engineering)一词。他认为,“提示词工程”已无法准确描述构建强大AI应用所需的复杂工作,而“上下文工程”则更深刻地揭示了本质

“提示词”过于简单,“上下文”才是工业级应用的关键
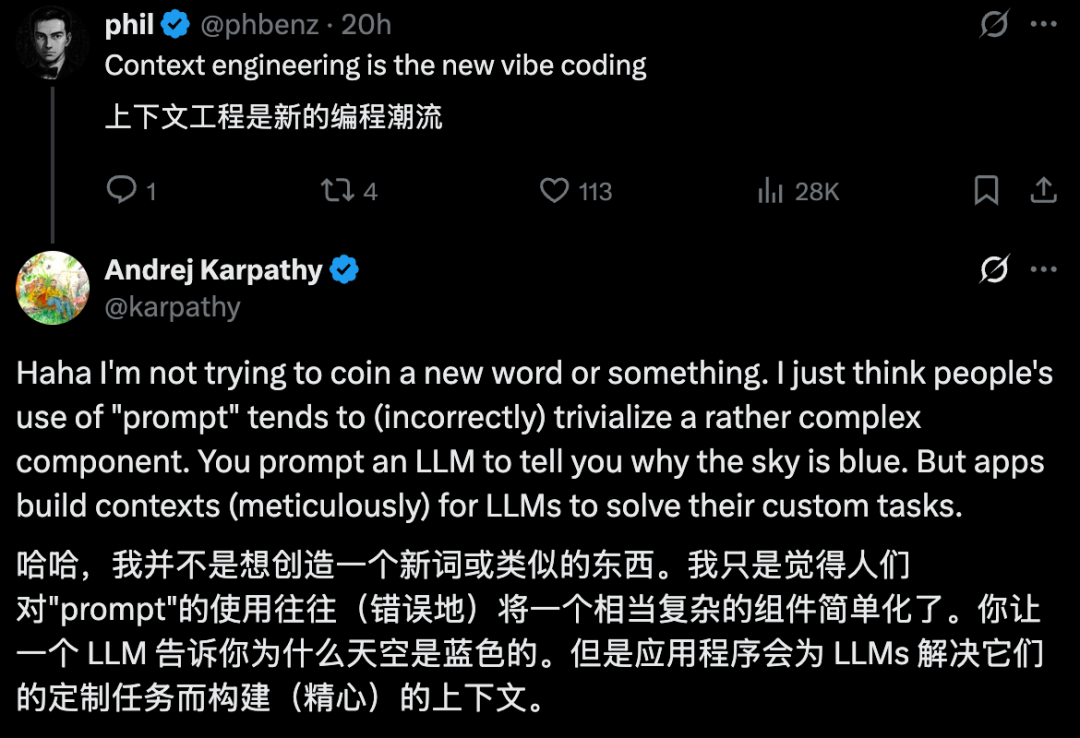
Karpathy 指出,人们通常将“提示词”(Prompt)与日常使用中发给大语言模型(LLM)的简短任务描述联系在一起。然而,在任何一个“工业级”的大模型应用中,核心工作远非如此简单。其真正的核心是一种被称为“上下文工程”的、融合了精妙艺术与严谨科学的实践
它的目标是:在模型进行下一步推理前,用恰到好处的信息填满其“上下文窗口”
这其中,“科学”的一面体现在其系统性和复杂性上。为了让模型达到最佳性能,工程师需要精心组合多种元素,包括:
-
• 任务描述与解释:清晰地告诉模型要做什么。 -
• 少样本示例(Few-shot examples):提供几个具体的范例供模型参考。 -
• 检索增强生成(RAG):从外部知识库中检索相关信息并注入上下文。 -
• 相关数据:引入其他(可能是多模态的)数据来丰富背景。 -
• 工具(Tools):赋予模型调用外部API或函数的能力。 -
• 状态与历史记录(State and history):让模型了解对话或任务的进展。 -
• 信息压缩(Compacting):在有限的窗口内高效地组织信息。
这个过程需要精准的平衡:上下文信息太少或形式错误,模型将缺乏足够依据,性能大打折扣;信息太多或无关内容泛滥,则会导致成本飙升,甚至因“噪音”干扰而降低性能。
而“艺术”的一面,则源于一种对大模型“心理”的直观理解和把握。优秀的工程师需要凭直觉洞察如何组织信息才能更好地引导模型的思维,这是一种难以量化的宝贵能力
“上下文工程”也只是冰山一角
Karpathy 进一步强调,即便如此复杂的“上下文工程”,也仅仅是构建一个完整大模型应用的其中一环。一个成熟的AI应用还需要处理更多工程挑战:
-
1. 问题分解与流程控制:将复杂问题拆解成合理的步骤和控制流。 -
2. 上下文窗口打包:高效、智能地填充和管理上下文窗口。 -
3. 模型调度:根据任务的复杂度和需求,调用不同能力和成本的模型。 -
4. “生成-验证”的用户体验:设计流畅的人机交互流程,让用户可以验证和修正模型生成的结果。 -
5. 其他关键模块:包括安全护栏(Guardrails)、系统安全、效果评估(Evals)、并行处理、数据预取(Prefetching)等等。
结论:“ChatGPT套壳”的说法大错特错
因此,“上下文工程”本身只是一个正在兴起的、且不容忽视的软件层中的一小部分。这个复杂的软件层负责协调每一次独立的模型调用,并将其整合进一个功能完备的应用中。
将如今先进的AI应用笼统地称为“ChatGPT套壳”(ChatGPT wrapper),这种说法不仅过时,而且大错特错。它完全忽视了背后庞大而精密的工程体系,也低估了构建真正有价值的大模型应用所需的智慧与努力
⭐
(文:AI寒武纪)