




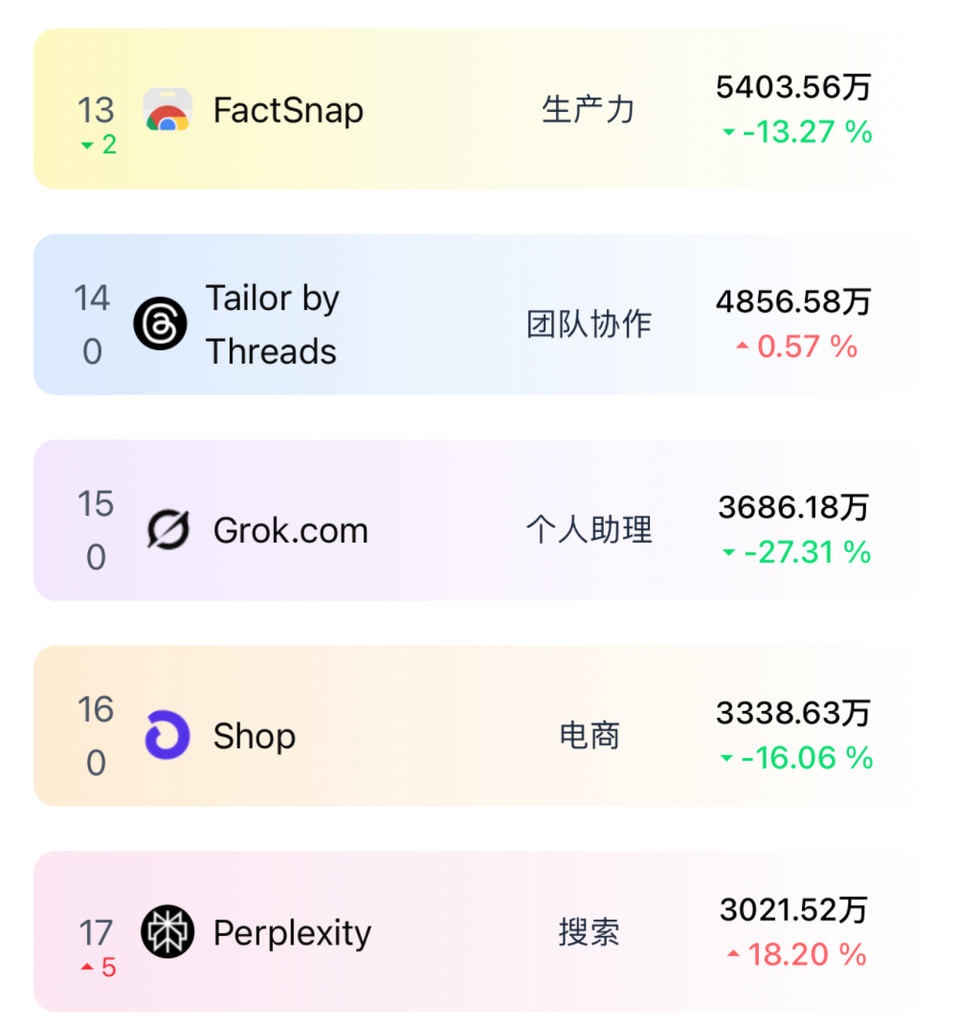
01.
-
初步分析:插件通过Groq平台调用LLaMA 3.3模型,对用户高亮的语句生成快速初判结果,通常在1秒内完成。
-
资料检索:同步调用exa.sh搜索引擎,查找与该主张(claim)相关的网络资料。相关链接不会立即呈现,而是作为下一步判断的输入。
-
详细验证:FactSnap利用GPT-4o-mini对claim与找到的文献或网页内容进行比对分析,生成“Explanation”部分的详细文本,并附上引用来源,作为补充解释。
02.

这句内容在视觉震撼视频下迅速传播,有用户调侃火箭“刷地”飞过了南加州多个地标城市,引发大量转发与围观。
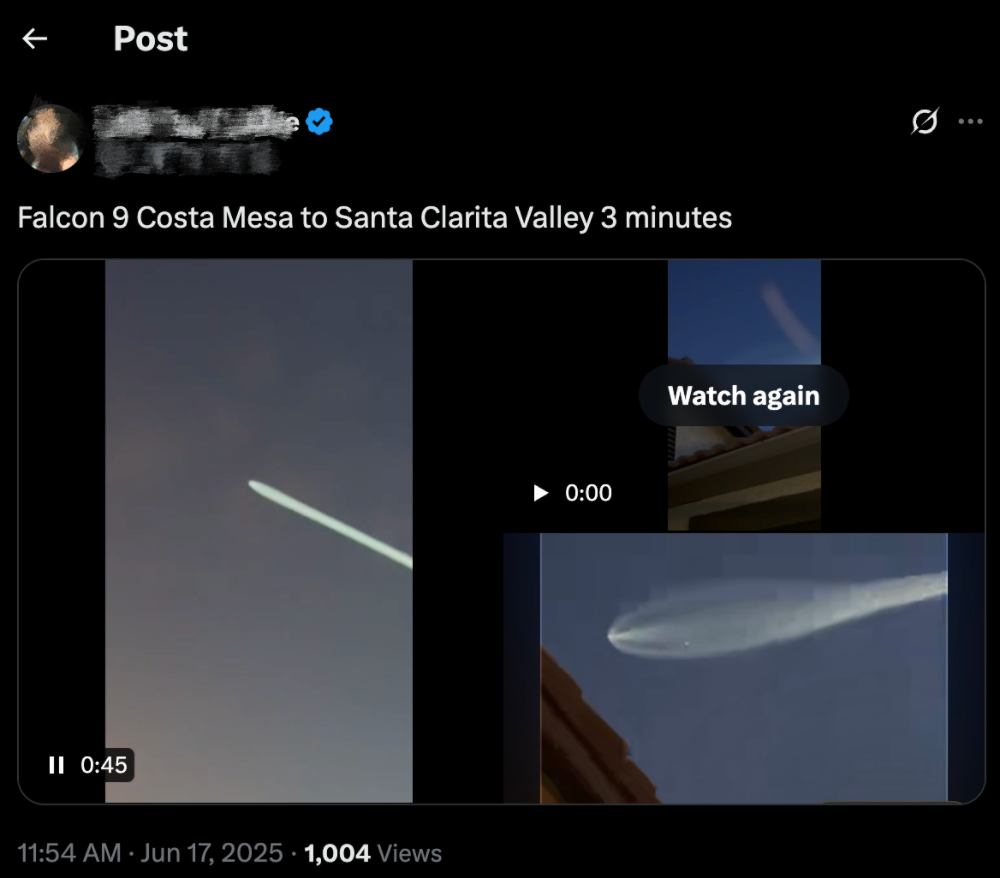
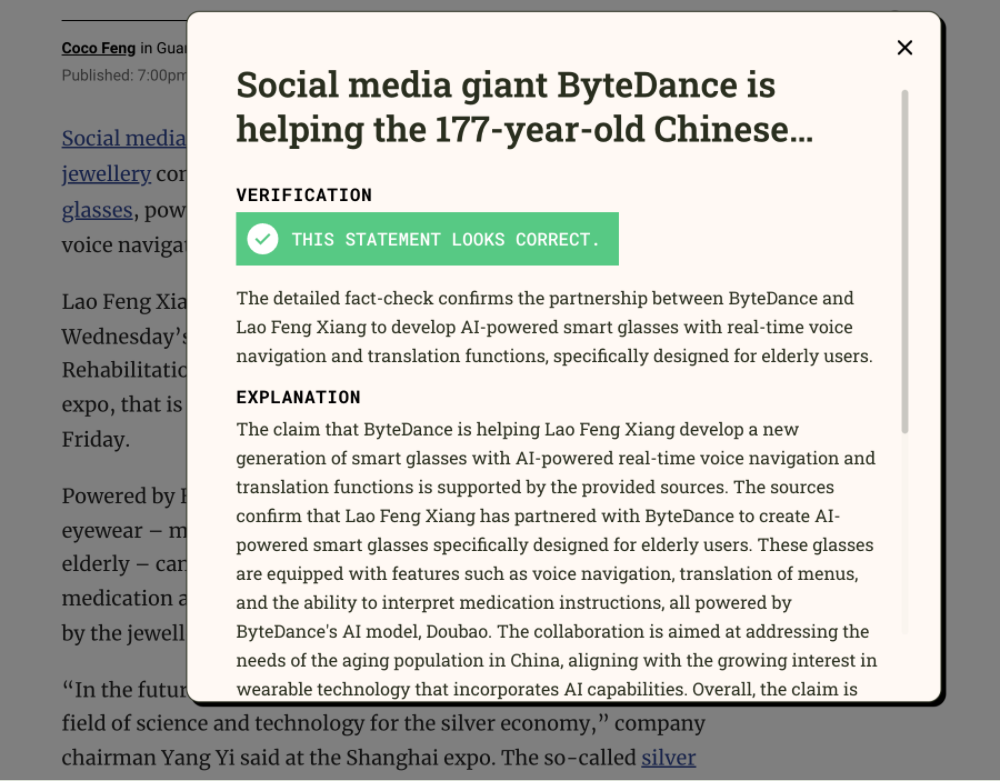
FactSnap判定该语句为错误,并给出理由:SpaceX的Falcon 9是轨道级发射火箭,飞行轨迹为垂直升空加曲线加速,不可能用于地面两点间的运输。
它还补充了火箭发射现场、视觉可见性的相关新闻链接。
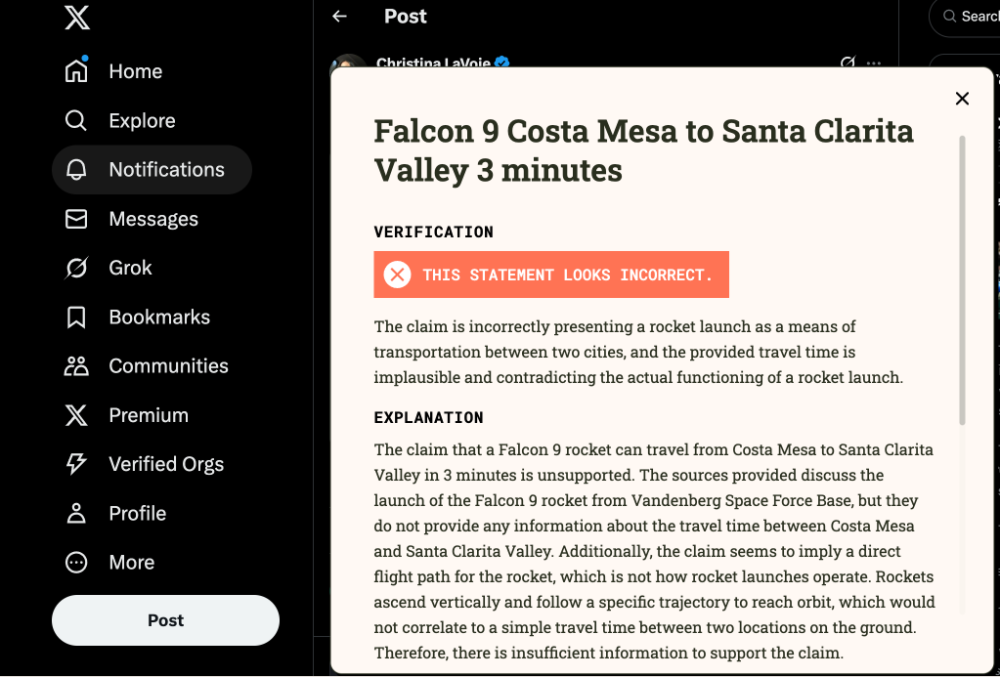
但值得注意的是,FactSnap对这条语句的处理仅采取了“字面解读”,可能忽视了发帖人在社交语境下的非字面意图。
此类表达常见于网络调侃,这也暴露了FactSnap在识别非结构化语言和隐喻方面的短板。

03.
从实际体验,FactSnap提供了一种轻便的信息查证方式,在页面中提供额外的信息和线索,帮助用户自己判断。
它通过多模型“联动”,在快速响应与内容解释之间做了合理分工,适合在用户浏览网页时“信不过一句话”时快速查验。
当然,它仍存在一些重要局限:如对社交语境、非字面语言、非英文内容的理解偏弱。未来若能补齐语境建模、多语言支持与跨浏览器兼容等能力,FactSnap有望成为一个重要的“AI辅助判断工具”。
(文:智东西)