

GSPN团队 投稿
量子位 | 公众号 QbitAI
视觉注意力机制,又有新突破,来自香港大学和英伟达。
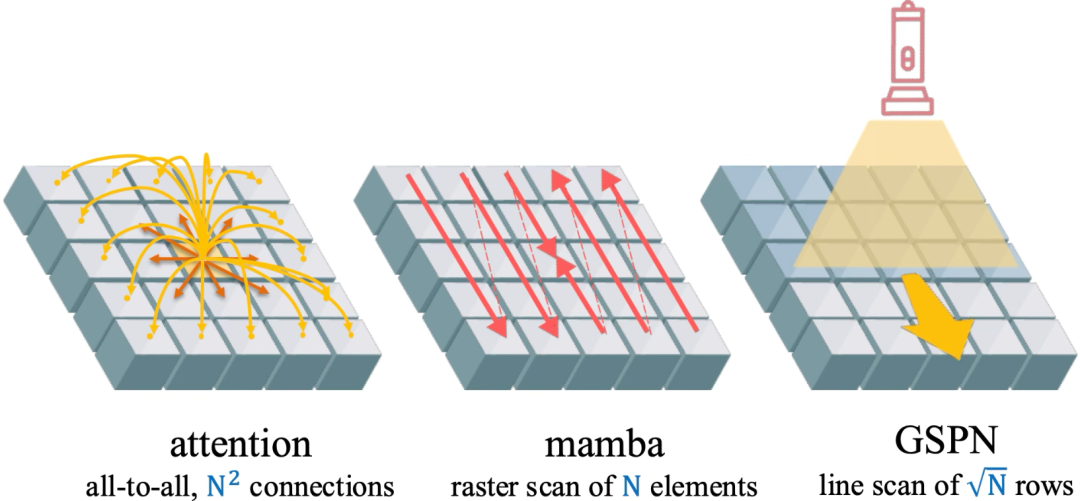
Transformer的自注意力在NLP和计算机视觉领域表现出色——它能捕捉远距离依赖,构建深度上下文。然而,面对高分辨率图像时,传统自注意力有两个大难题:
-
计算量巨大:O(N²) 的复杂度让处理长上下文变得非常耗时。 -
破坏空间结构:将二维图像拉平成一维序列,会丢失像素之间的空间关系。
虽然线性注意力和Mamba等方法能把复杂度降到O(N),但它们还是把图像当作一维序列处理,无法真正利用二维空间信息。

为此,香港大学与英伟达联合推出了广义空间传播网络(GSPN)。
GSPN采用二维线性传播,结合“稳定性–上下文条件”,将计算量从 O(N²) 或 O(N) 再降到√N级别,并完整保留图像的空间连贯性。这样,不仅大幅提升了效率,还在多个视觉任务上刷新了性能纪录。
兼具空间连贯性和计算效率
GSPN的核心技术是二维线性传播与稳定性-上下文条件,基于此,现有注意力机制与GSPN的对比如下:
-
传统Transformer:将图像视为一维序列,计算复杂度为O(N²),处理高分辨率图像效率低下,且忽略空间连贯性。 -
线性注意力和状态空间模型(如Mamba):虽将计算复杂度降至O(N),但仍抽象掉了视觉任务关键的空间结构。 -
GSPN:直接对二维图像进行线扫描,通过稳定性-上下文条件确保传播稳定性和长距离依赖,有效序列长度降至√N,兼具空间连贯性和计算效率。
二维线性传播:从行列并行到密集连接
作为GSPN的核心组件,二维线性传播包括两个关键点:
- 线扫描机制
对于二维图像,二维线性传播通过逐行或逐列的顺序处理进行其遵循线性循环过程,隐藏层通过前一行的隐藏状态和当前输入计算得出:
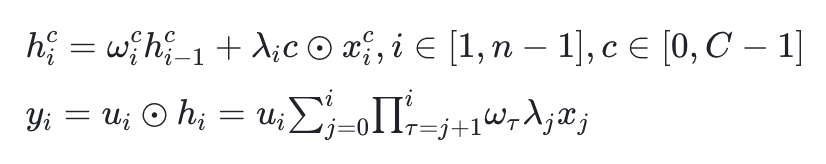
将上述公式按展开,可以得到向量化的输入与一个下三角矩阵的乘积,输出则为输入的加权和。其中与注意力机制里的大矩阵意义类似—都描述了任意两个像素之间的连接关系。
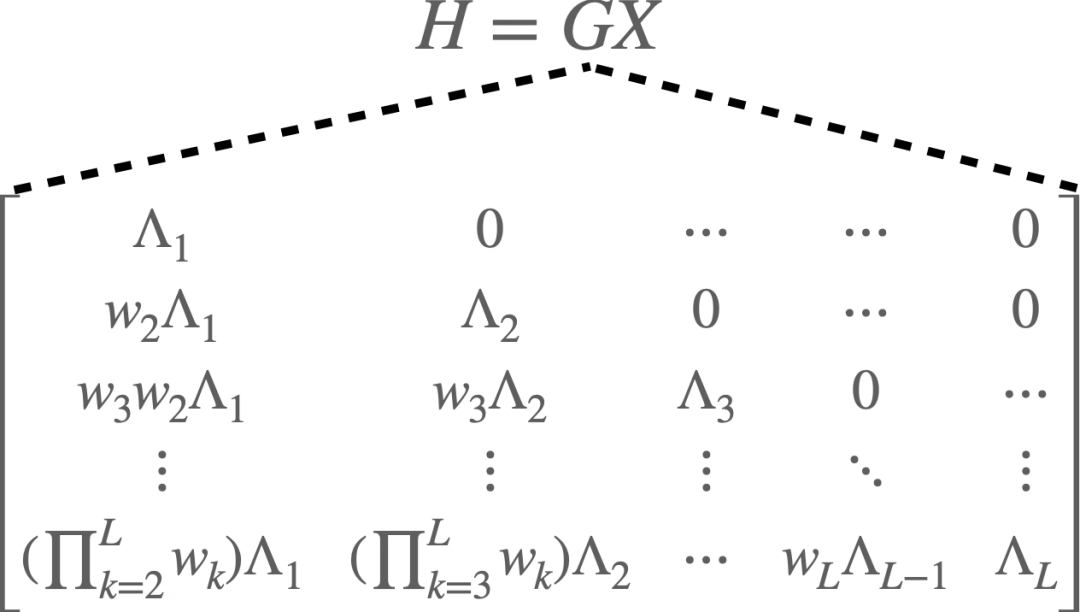
在传播过程中,研究人员并不对所有像素做全连接,而是只在前一行的左、中、右三个相邻像素之间建立三向连接。这样既能大幅减少参数量,又能保证信息像全连接那样完整传播。
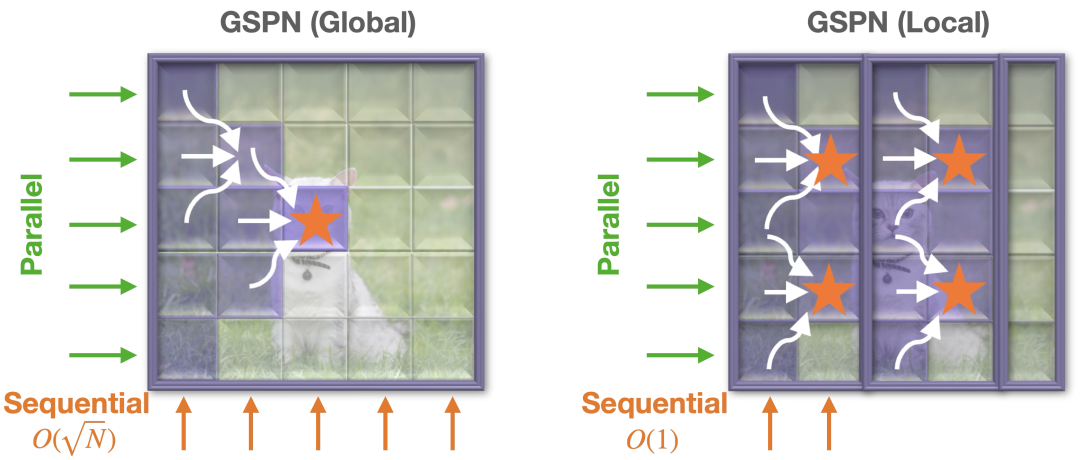
GSPN有两种变体,一种捕捉整个输入的全局上下文(下图左),另一种专注于局部区域以实现更快的传播(下图右)。这些变体使GSPN能够作为现有注意力模块的直接替代品无缝集成到现代视觉架构中。
- 元素之间的密集链接
那么上述三连接扫描方式是否能形成像注意力机制的那样的密集链接呢?
下面的示意图给出了肯定答案。通过左→右、右→左、上→下、下→上四个方向的扫描,所有的像素都会和其他任意像素产生连接。
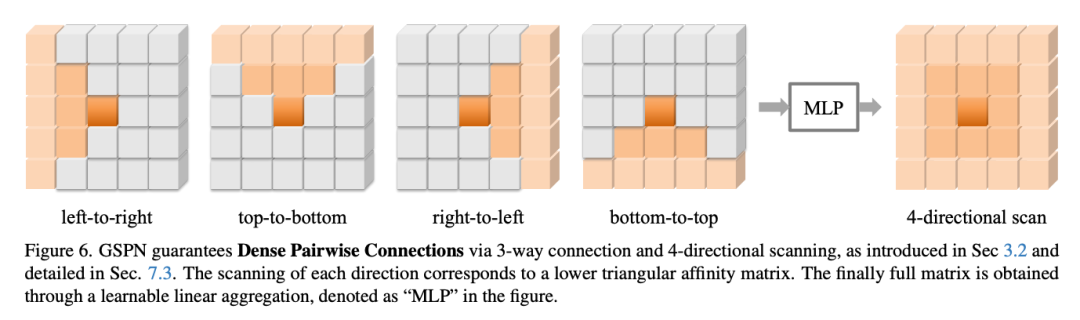
此外,GSPN引入了一个可学习的合并器,用于聚合来自所有扫描方向的空间信息,增强了模型动态适应视觉数据二维结构的能力。
研究人员发现GSPN天然对位置信息敏感,无需位置嵌入,避免了常见的混叠问题。
稳定性-上下文条件:确保长距离传播的可靠性
众所周知,线性系统容易出现不稳定。
为了让 GSPN在长距离传播时既稳定又高效,研究人员提出了定理1和定理 2(统称“稳定性–上下文条件”)。推导结果表明(过程见GSPN附录),只要把传播矩阵做成行随机矩阵(元素非负、每行之和为1),就能在保证信息不丢失、信号不过度放大或衰减的前提下,维持系统稳定。
更简单的是,只需在CUDA内核外加个Sigmoid激活,再对每行做归一化,就能轻松实现这一点。
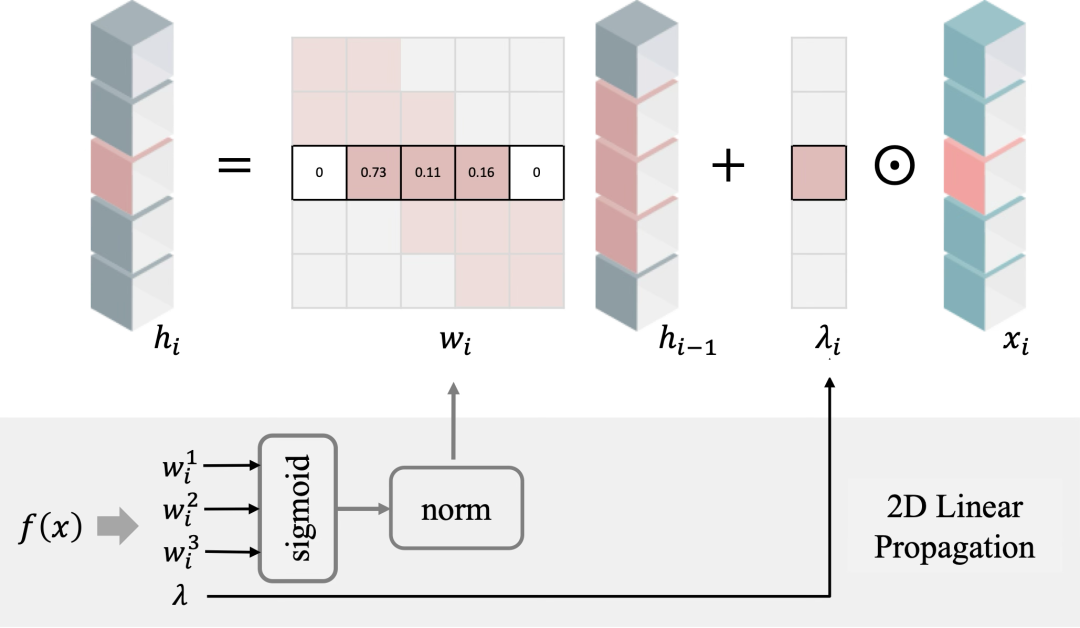
GSPN引入了一个根据线性传播构建的序列长度为的全新内核。无需依赖ViT的大规模矩阵乘法,也不同于Mamba的并行方案。该核能在批量样本、所有通道以及与传播方向垂直的行/列上一次性并行执行,极大地减少循环开销,实现了快速且可扩展的线性传播。
模块化设计
与ViT和Mamba类似,研究人员推荐了以下GSPN模块化设计。
- GSPN模块
通过共享1×1卷积进行降维,再通过三个独立的1×1卷积生成依赖于输入的参数,用于二维线性传播,这些投影和传播封装在模块化的GSPN单元中。 - 图像分类架构
采用Swin-Transformer的四级分层架构,通过堆叠设计良好的GSPN块,在相邻层级间进行下采样操作,平衡计算效率和表示能力。 - 类条件图像生成架构
重新设计生成架构,通过向量嵌入加法集成时间步和条件信息,包含跳跃连接和线性投影,去除位置嵌入并引入FFN进行通道混合。 - 文本到图像生成架构
将GSPN模块直接集成到Stable Diffusion架构中,替换所有自注意力层,利用预训练权重初始化参数,加速训练。
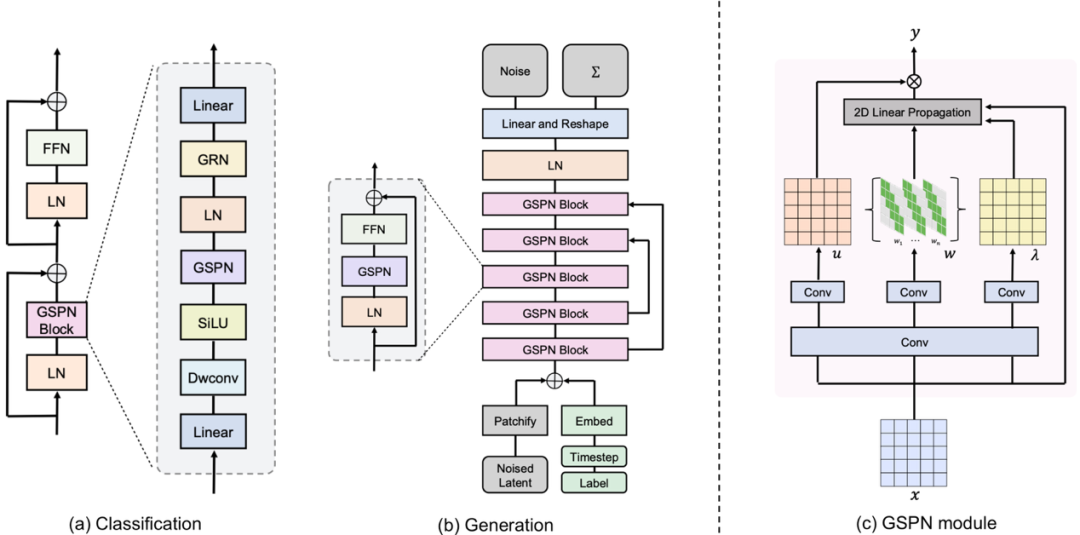
需要注意的是,GSPN本身是一个独立的注意力机制层,可以非常灵活的用在任何视觉网络中。比如在Stable Diffusion中,研究人员就保留了大部分网络结构甚至训练参数,直接将注意力层替换为GSPN,仍然取得了非常好的效果。
实验:从理解到高分辨率生成的全面领先
具体来看实验结果。
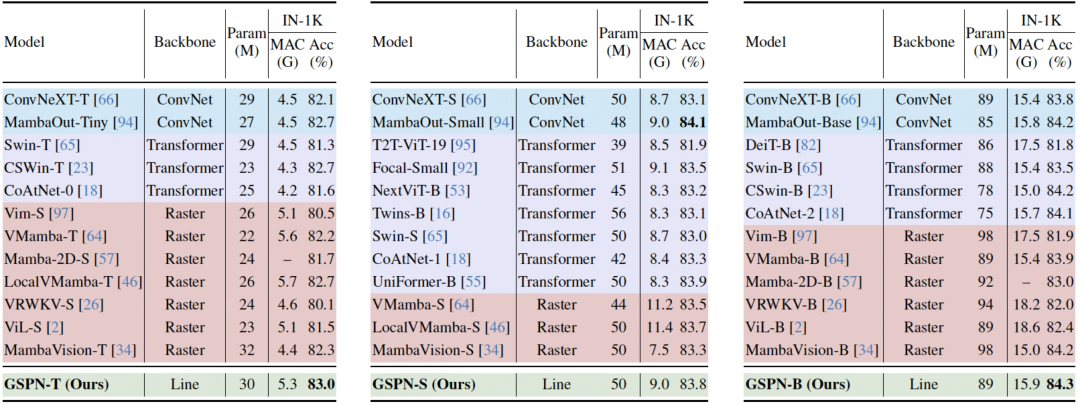
在图像分类领域,GSPN实现了效率与精度双优。
在ImageNet中,GSPN-T在5.3 GFLOPs计算量下,Top-1准确率达82.2%,超越LocalVMamba-T(81.9%)和ViT类模型,参数效率提升显著。
图像生成方面,在类条件生成任务中,GSPN-XL/2在ImageNet 256×256任务中以65.6%参数实现FID 3.2,优于DiT-XL/2(FID 3.5),生成速度提升1.5倍。
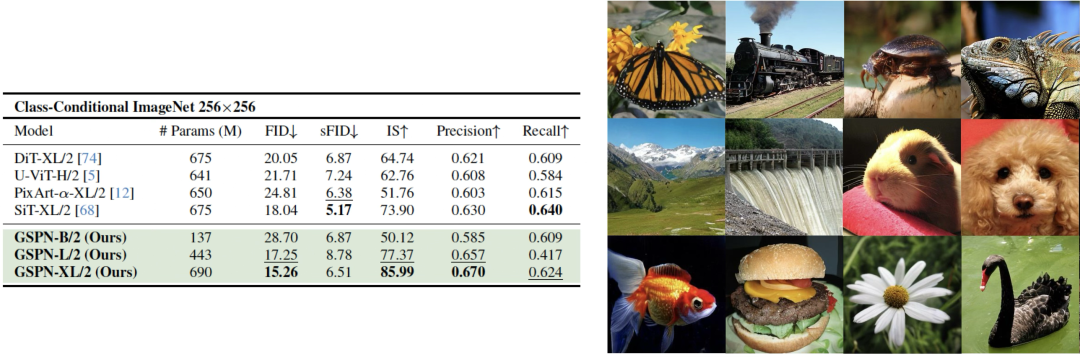
文本到图像生成任务上,在SD-XL模型中,生成16K×8K图像的推理时间加速超84倍,且在未见分辨率外推的场景下FID分数(30.86)优于基线(32.71)。
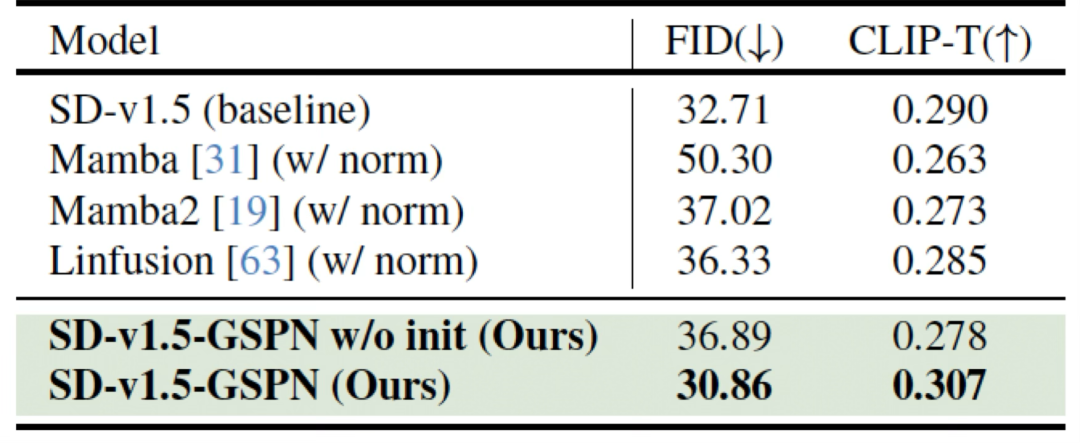
值得一提的是,GSPN具备两个优势:
-
任意尺寸兼容:基于稳定性-上下文条件的归一化权重,GSPN可直接处理2K至16K分辨率图像,无需像Mamba那样依赖额外归一化层。 -
实时生成场景:单卡支持16K分辨率生成,适用于电影特效、虚拟场景搭建等对高分辨率和速度敏感的领域。
这使其具备了从学术到工业的落地潜力。
总结来说,GSPN通过二维结构感知和线性复杂度设计,重新定义了视觉注意力机制的范式。
其在保持空间连贯性的同时实现计算效率跃升,尤其在高分辨率生成任务中的突破,为多模态模型和实时视觉应用提供了新方向。
论文: https://arxiv.org/abs/2501.12381
项目主页: https://whj363636.github.io/GSPN/
代码:https://github.com/NVlabs/GSPN
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)