
大模型到底会不会真的思考?这一疑问一直萦绕在人们心中。
作为LLM的反对派Yann LeCun又拿出了新证据。他参与的最新研究《From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning》(从词元到思想:大模型与人类在压缩与意义之间的权衡)用信息论的全新视角,揭示了大语言模型(LLM)与人类在“理解世界”这件事上的本质差异。

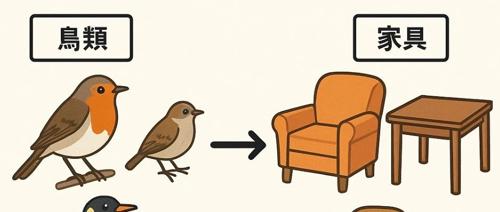
人类大脑在处理信息时,善于将纷繁复杂的感知和经验,压缩成简洁而有意义的“概念”。比如,“知更鸟”和“蓝松鸦”都被归为“鸟类”,而且我们还能分辨出“知更鸟”比“企鹅”更“像鸟”。这种能力让我们在面对海量信息时,既能高效归纳,又不失对细节和语境的敏感。
而LLM的“理解”机制则大不相同。它们通过对海量文本的统计学习,形成了复杂的词嵌入空间。论文作者提出疑问:这些AI模型内部的“概念结构”,是否也能像人类一样,在压缩信息的同时保留丰富的语义?还是说,它们只是“聪明的压缩机”,本质上与人类的认知有着天壤之别?
信息论新框架:用“速率-失真”理论量化AI与人类的差距
为了解答这一问题,研究团队创新性地引入了信息论中的“速率-失真理论”(Rate-Distortion Theory)和“信息瓶颈原理”(Information Bottleneck),建立了一套全新的量化框架。简单来说,这一框架可以精确衡量一个系统在“压缩信息”(减少冗余)和“保留语义”(避免失真)之间的权衡。
研究者选用了认知心理学领域的经典数据集(如Rosch的“鸟类”“家具”典型性实验),这些数据集由专家精心设计,能真实反映人类的概念形成和“典型性”判断。与此同时,团队分析了BERT、Llama、Gemma、Qwen、Phi、Mistral等多种主流大模型的词嵌入结构,涵盖了从几亿到七百多亿参数的不同规模。
三大核心发现:AI与人类的“理解鸿沟”
-
AI能学会“分门别类”,但难以“举一反三”
研究发现,LLM在大类划分上表现优异,能将“鸟类”“家具”等分得八九不离十,甚至有些小模型(如BERT)在这方面比大模型还强。这说明,AI在宏观上能“看懂”哪些东西属于同一类。但在更细致的“典型性”判断上,AI就力不从心了。比如,AI很难像人类一样认为“知更鸟”比“企鹅”更像鸟。这种“细粒度”语义区分的缺失,意味着AI的“理解”还停留在表层。这种细腻的语义区分,是人类认知的独特优势。

-
AI和人类的“优化目标”完全不同
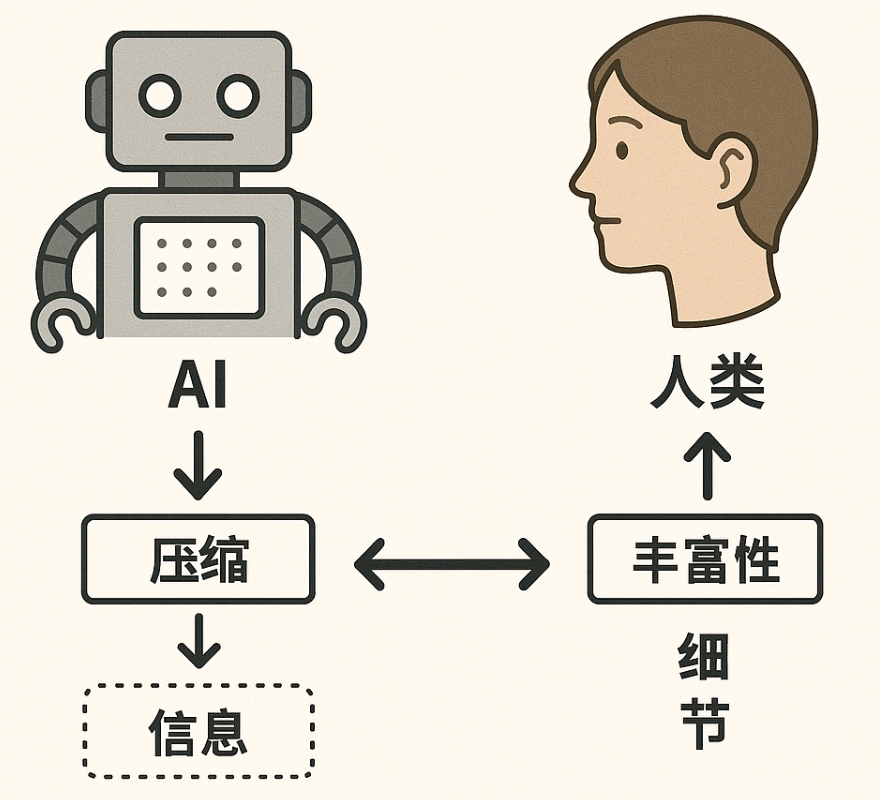
论文的最大亮点在于揭示了AI和人类在“压缩-意义”权衡上的本质分歧。LLM在内部表示上极度追求“压缩”——用最少的信息表达最多内容,最大限度减少冗余。这种“压缩至上”的策略,使得AI在信息论意义上极为高效,但也牺牲了对语义细节和上下文的敏感。而人类的概念系统则更注重“适应性丰富性”,即保留更多细节和语境,即使这会降低压缩效率,多花点“存储空间”。这种根本性的差异,决定了两者在“理解世界”时的表现截然不同。
3.模型越大≠越像人类,结构和目标更关键
研究还发现,模型规模的扩大并不能让大模型更接近人类的思维方式。反而是模型的结构和训练目标,才是影响“类人化”表现的关键。例如,BERT等编码器模型在某些任务上甚至优于更大的生成式模型。这一发现对当前AI“堆参数”的发展趋势提出了挑战。
小结
技术的进步不只是“更大”或“更快”,更重要的是“更合适”。如果想让机器更好地服务于人类,或许我们需要重新思考,什么才是真正有价值的“智能”。我们不必苛求机器像人一样思考,也许正是这些差异,让人类和技术的结合变得更加有趣和充满可能。
论文:https://arxiv.org/pdf/2505.17117
公众号回复“进群”入群讨论。
(文:AI工程化)