

VeBrain团队 投稿
量子位 | 公众号 QbitAI
机器人的新大脑框架来了!
上海人工智能实验室联合多家单位提出了一种全新的通用具身智能大脑框架:Visual Embodied Brain,简称VeBrain。
该模型通过同时集成视觉感知、空间推理和机器人控制能力,可实现多模态大模型(MLLM)对物理实体的直接操控,使机器人能像人类一样“看到-思考-行动”。
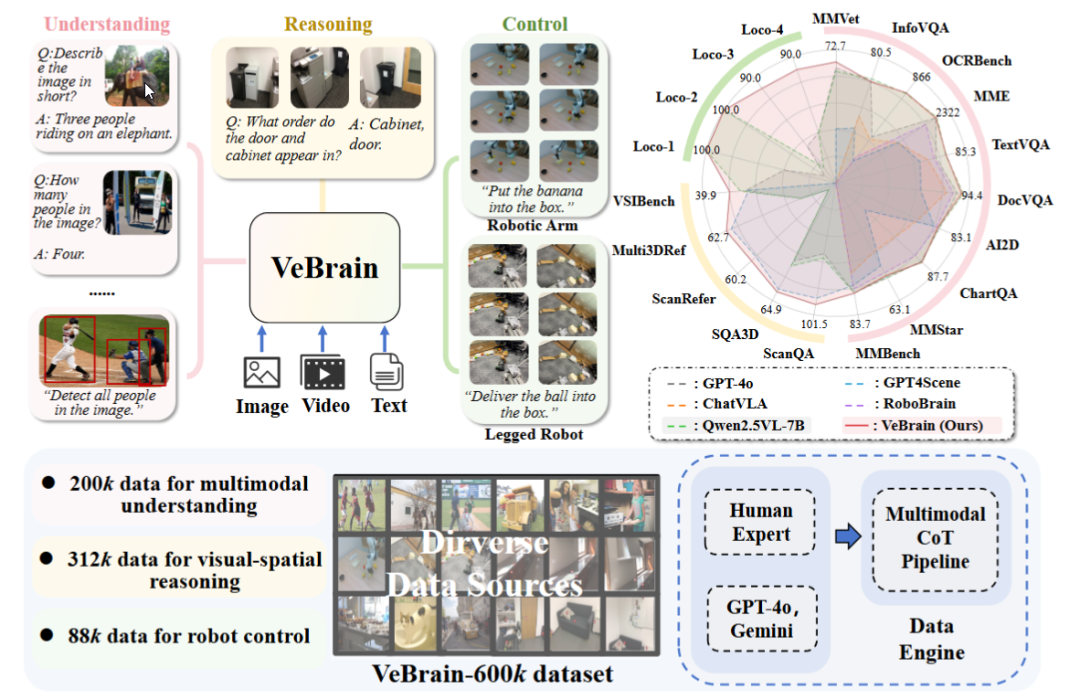
相比现有的MLLM和视觉-语言-动作(VLA)模型,VeBrain具备以下亮点:
- 统一三类任务的语言建模范式
将机器人控制转化为MLLM中常规的2D空间文本任务,通过关键点检测与具身技能识别等任务,打通感知、推理、控制三大能力的建模路径; - 提出“机器人适配器”实现闭环控制
由关键点追踪、动作控制、技能执行和动态接管模块组成,实现从文本决策到真实动作的精准映射; - 构建高质量多能力数据集VeBrain-600k
涵盖60万条指令数据,覆盖多模态理解、视觉-空间推理、机器人操作三类任务,辅以多模态链式思维(Multimodal CoT)标注,提升模型组合推理能力; - 卓越的多模态和真机性能
同时实现匹配同参数量下最强开源模型QwenVL-2.5的多模态能力,同参数量下最优的空间推理能力,以及分别在机械臂和机器狗两个实体上验证的真机控制能力。

测试结果表明,VeBrain在视觉感知、空间推理和机器人控制能力上同时取得了最先进的性能。
VeBrain架构:统一感知-推理-控制建模范式
当前MLLM在多模态感知方面表现卓越,但难以直接迁移到机器人控制等物理任务中,主要瓶颈在于任务目标空间的不一致。
而VeBrain打破这一限制,提出将机器人控制重构为两个通用MLLM子任务:
- 关键点检测(Keypoint Detection)
以图像为输入,预测二维目标位置,作为运动锚点; - 技能识别(Skill Recognition)
基于上下文生成语义动作,如“前进”、“夹取”、“转身”等。
通过此类语言化的建模方式,VeBrain控制任务得以与理解和推理任务共享统一的输入输出空间,能够有效对抗多任务冲突与灾难性遗忘。
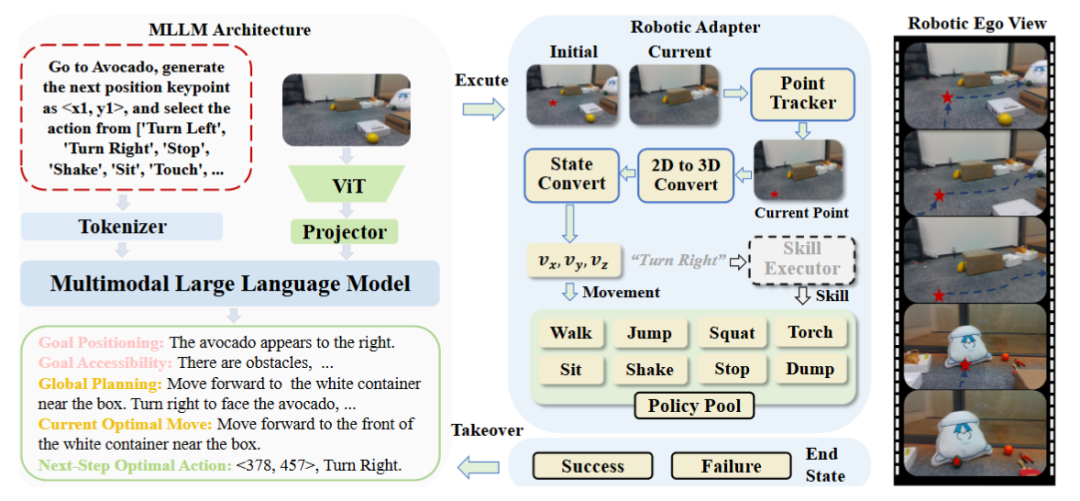
VeBrain的另一个核心创新是机器人适配器模块,其组成包括:
- 点追踪器(Point Tracker)
实时更新四足机器人在运动过程中的视角下关键点; - 运动控制器(Movement Controller)
结合RGBD相机获取深度信息,将2D坐标转换为3D控制指令; - 策略执行器(Skill Executor)
调用预训练的低层控制策略(如行走、夹取)完成任务执行; - 动态接管(Dynamic Takeover)
在出现目标丢失或策略失败时,自动回调语言模型进行重规划。
该模块实现了MLLM与机器人之间的闭环通信,提升了机器人在动态环境中的稳定性与鲁棒性。
VeBrain-600k:统一训练多能力模型的高质量数据集
为支撑模型的统一训练,VeBrain团队还配套了VeBrain-600k数据集,包含:
-
20万条多模态理解数据:整合图像、视频与文本,来源于ShareGPT4V、MMInstruct等; -
31.2万条空间推理数据:结合ScanNet点云数据,生成涉及计数、距离、尺寸等空间理解任务; -
8.8万条机器人控制数据:由人工采集、标注的真实机器人操作数据,覆盖四足机器人与机械臂两类平台;
此外,大量任务引入链式思维(Chain-of-Thought,CoT)结构,由GPT-4o与Gemini自动生成推理过程并经专家复核,极大提升了数据质量与任务复杂度。
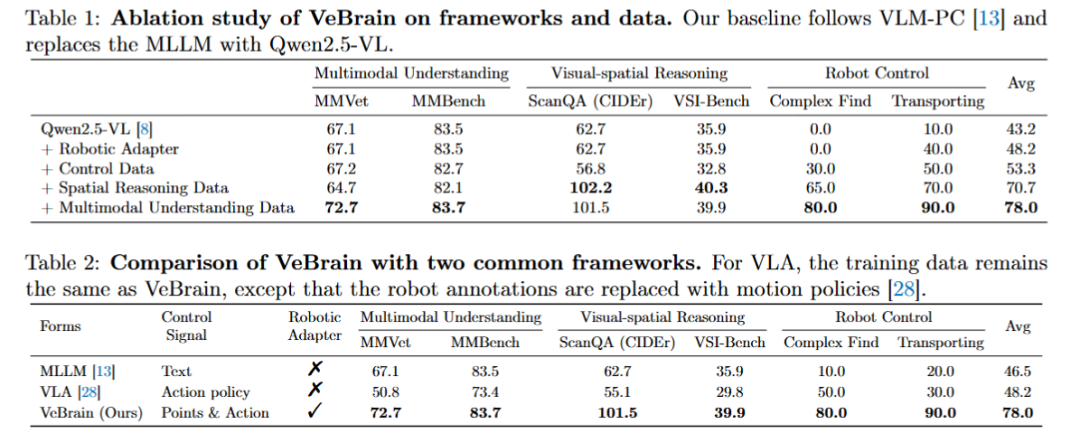
通过消融实验,VeBrain团队验证了VeBrain-600k数据集的丰富性和必要性。
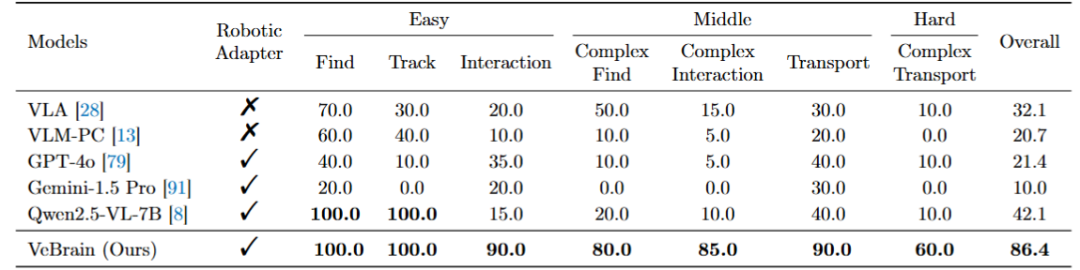
从表格中可以看到,尽管在多模态理解方面表现良好,现有的MLLM在视觉空间推理和机器人控制方面往往表现不足,“复杂寻找”任务的成功率仅为0%。而在为模型配备我们的机器人适配器后,Qwen2.5-VL在两个机器人控制任务上的成功率明显提高。
将VeBrain与两个常用框架,即MLLM和VLA进行比较,发现MLLM由于控制能力较弱,在两项任务中难以直接控制机器人;而VLA虽然在机器人控制任务中表现良好,但大大牺牲了多模态能力。与这些框架相比,VeBrain在所有任务中实现了最佳权衡性能,相较于其他框架平均提升了31.5%。
性能测试结果:多模态理解+空间智能+机器人控制三位一体
VeBrain团队在13个多模态benchmark和5个空间推理benchmark上测试了VeBrain的性能。结果表明,VeBrain实现了比肩当前最强开源模型Qwen2.5-VL的多模态能力,以及同参数量下最优的视觉空间推理能力。
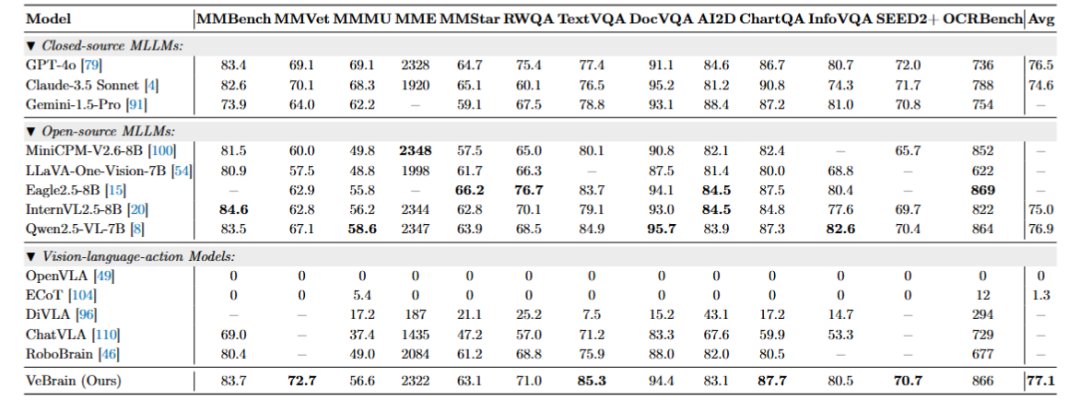
可以看到,VeBrain在MMVet(+5.6%)、DocVQA(94.4分)等13个基准上超越GPT-4o和Qwen2.5-VL,并取得了77.1的最佳归一化平均性能,这表明其具有更强的多模态能力。
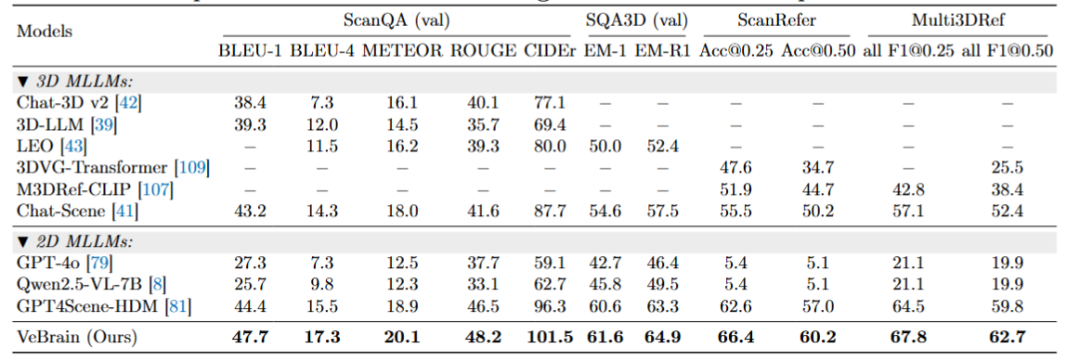
模型需要强大的3D空间感知和推理能力来回答不同类型的问题,大多数先前方法采用了基于3D的MLLM结构,并在四个基准测试上取得了有希望的结果。
相比之下,直接将2DMLLM迁移到这些任务会导致性能差,例如Qwen2.5-VL-7B的-50.1Acc@0.25,这表明它们在3D空间理解和推理方面的不足。与这些方法相比,GPT4Scene-HDM通过基于视频的2DMLLM和对象标记取得了更好的结果,但作为一个专业模型,GPT4Scene-HDM难以应用于常见的2D多模态任务。
而VeBrain作为一个通才MLLM,在3D场景问答(ScanQA CIDEr 101.5)和物体定位(ScanRefer Acc@0.25 66.4%)上刷新了纪录,甚至在所有任务上都能超越GPT4Scene-HDM。
进一步诊断现有MLLM和VeBrain的视觉空间推理能力。可以看出,VeBrain在VSI基准测试中的平均得分优于所有现有的MLLM,例如,比Qwen2.5-VL-7B高出+4.0%。与GPT-4o等更大的MLLM相比,VeBrain也能表现更出色。


为了证明VeBrain的泛化性和通用性,选择四足机器人和机械臂作为真机验证的两个实体。可以看到,在四足机器人尤其是复杂的长程任务上,VeBrain相比于现有的VLA模型和MLLM模型取得了+50%成功率的提升。
在机械臂尤其是长程任务上,VeBrain相比于π0模型也取得了显著的提升。
论文链接:https://huggingface.co/papers/2506.00123/
项目主页:https://internvl.github.io/blog/2025-05-26-VeBrain/
推理代码&模型链接:https://internvl.github.io/blog/2025-05-26-VeBrain/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)