

人工智能(AI)技术发展迅速,大型语言模型(LLMs)极大地简化了许多任务。然而,它们面临一个基本限制:会话之间无法保留记忆。
如果能够拥有一个本地的、便携的 LLM “记忆层”,完全掌控您的数据,会怎样呢?
今天,我们将介绍 OpenMemory MCP,一个基于 Mem0(AI 代理的记忆层)构建的私有、本地优先的记忆层。它支持跨 MCP 兼容客户端(如 Cursor、Claude Desktop、Windsurf、Cline 等)实现持久化、上下文感知的 AI。
本指南将详细说明如何安装、配置和运行 OpenMemory MCP 服务器,同时涵盖其内部架构、流程、底层组件以及实际应用案例和示例。
让我们开始吧。
涵盖内容
简而言之,本文将详细探讨以下主题:
•什么是 OpenMemory MCP 服务器及其重要性?•逐步设置和运行 OpenMemory 的指南。•仪表板可用功能(及其背后的技术)。•安全性、访问控制和架构概述。•实际应用案例及示例。
1. 什么是 OpenMemory 及其重要性?
OpenMemory MCP 是一个为 MCP 客户端设计的私有、本地记忆层。它提供了存储、管理和跨平台利用 AI 记忆的基础设施,同时确保所有数据存储在本地系统上。
简单来说,它是一个基于向量的记忆层,适用于使用标准 MCP 协议的任何 LLM 客户端,并与 Mem0 等工具无缝协作。
核心功能:
•跨会话存储和调用任意文本片段(记忆),确保 AI 无需从零开始。•底层使用向量存储(Qdrant)进行基于相关性的检索,而非仅限于关键词匹配。•完全运行在您的基础设施上(Docker + Postgres + Qdrant),数据不会外传。•支持在应用或记忆级别暂停或撤销客户端访问权限,并为每次读写操作生成审计日志。•提供仪表板(基于 Next.js 和 Redux),展示谁在读写记忆以及状态变更历史。
🔁 工作原理(基本流程)
核心流程如下:
1.通过单一 docker-compose 命令启动 OpenMemory(API、Qdrant、Postgres)。2.API 进程托管一个使用 Mem0 的 MCP 服务器,通过 SSE(Server-Sent Events)支持标准 MCP 协议。3.LLM 客户端通过 SSE 流连接到 OpenMemory 的 /mcp/... 端点,调用 add_memories()、search_memory() 或 list_memories() 等方法。4.向量索引、审计日志和访问控制等其他功能由 OpenMemory 服务自动处理。
您可以观看官方演示并在 mem0.ai/openmemory-mcp[1] 上了解更多!
2. 逐步设置和运行 OpenMemory
本节将指导您如何在本地设置和运行 OpenMemory。
项目包含两个主要组件:
•api/ – 后端 API 和 MCP 服务器•ui/ – 前端 React 应用程序(仪表板)
步骤 1:系统要求
在开始之前,请确保您的系统已安装以下内容,并附上文档链接以便参考:
•Docker 和 Docker Compose•Python 3.9+ — 后端开发所需•Node.js — 前端开发所需•OpenAI API 密钥 — 用于 LLM 交互•GNU Make — 构建自动化工具,用于设置过程
请确保 Docker Desktop 已运行,然后继续下一步。
步骤 2:克隆仓库并设置 OpenAI API 密钥
通过以下命令克隆位于 github.com/mem0ai/mem0[2] 的仓库:
git clone https://github.com/mem0ai/mem0.gitcd openmemory
接下来,将您的 OpenAI API 密钥设置为环境变量:
export OPENAI_API_KEY=your_api_key_here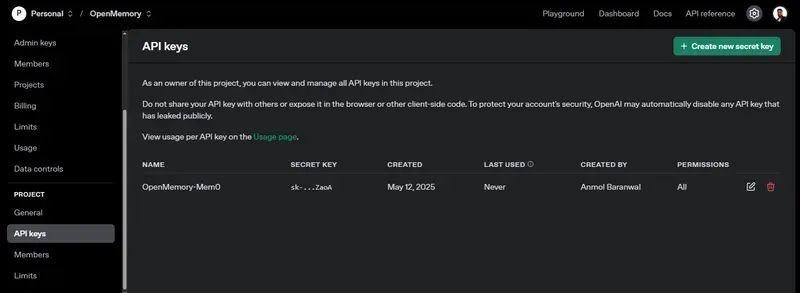
注意:此命令仅为当前终端会话设置密钥,关闭终端窗口后失效。

步骤 3:设置后端
后端运行在 Docker 容器中。在根目录运行以下命令启动后端:
# 复制环境文件并编辑以更新 OPENAI_API_KEY 和其他密钥make env# 构建所有 Docker 镜像make build# 启动 Postgres、Qdrant 和 FastAPI/MCP 服务器make up
.env.local 文件遵循以下格式:
OPENAI_API_KEY=your_api_key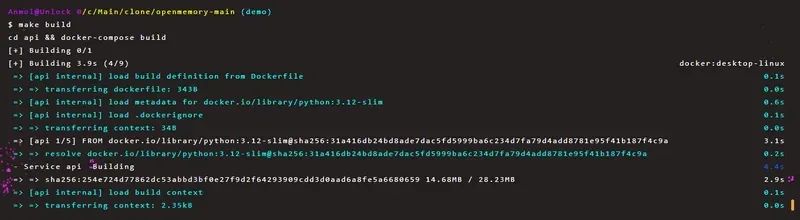

设置完成后,API 将在 http://localhost:8000 上运行。您可以在 Docker Desktop 中查看运行中的容器。
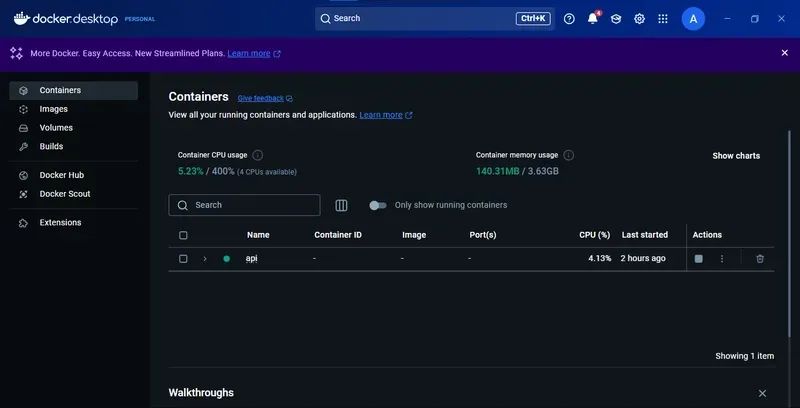
以下是一些其他有用的后端命令:
# 运行数据库迁移make migrate# 查看日志make logs# 进入 API 容器 shellmake shell# 运行测试make test# 停止服务make down
步骤 4:设置前端
前端是一个 Next.js 应用程序。启动前端只需运行:
# 使用 pnpm 安装依赖并运行 Next.js 开发服务器make ui
安装成功后,访问 http://localhost:3000 查看 OpenMemory 仪表板,仪表板将指导您在 MCP 客户端中安装 MCP 服务器。
仪表板界面如下所示:
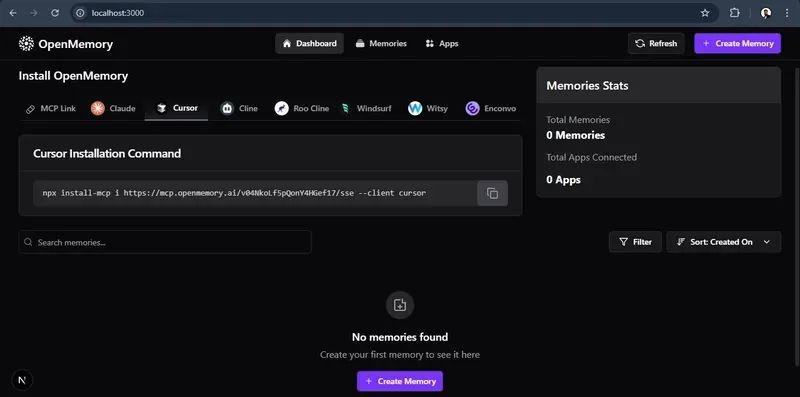
MCP 客户端通过 SSE 通道连接到 GET /mcp/{client_name}/sse/{user_id},绑定两个上下文变量(user_id 和 client_name)。
在仪表板中,您将找到基于您选择的客户端(如 Cursor、Claude、Cline、Windsurf)的一行安装命令。例如,在 Cursor 中安装的命令如下:
npx install-mcp i https://mcp.openmemory.ai/xyz_id/sse --client cursor如果尚未安装 install-mcp,系统会提示您安装,然后您只需为服务器提供一个名称。
注意:上述为示例命令,请忽略具体内容。打开 Cursor 设置,在侧边栏检查 MCP 选项以验证连接。
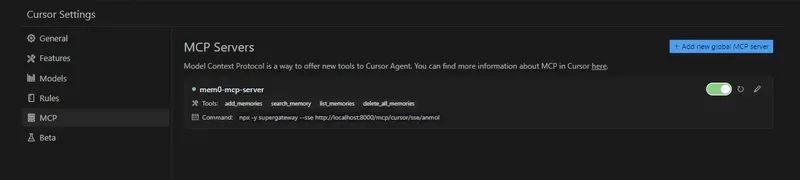
在 Cursor 中打开新聊天,输入类似“我希望它记住我的 GitHub 简介信息”的提示。这将触发 add_memories() 调用并存储记忆。刷新仪表板,进入“Memories”选项卡查看所有记忆。
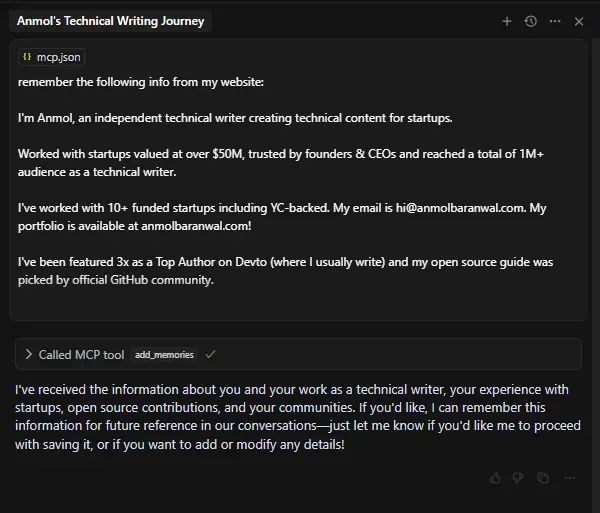
记忆会自动分类(通过 GPT-4o 分类),作为可选标签。
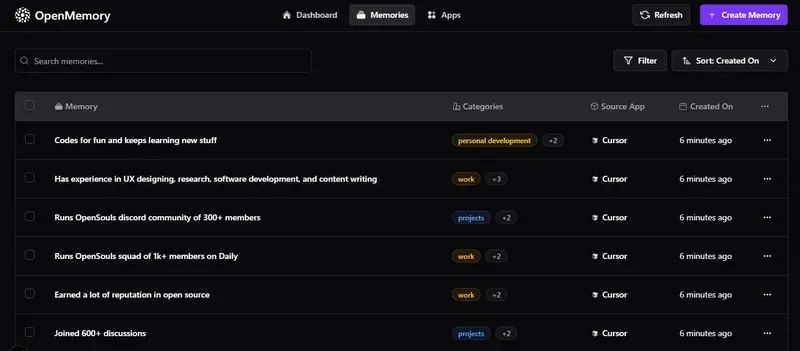
您还可以连接其他 MCP 客户端,如 Windsurf。
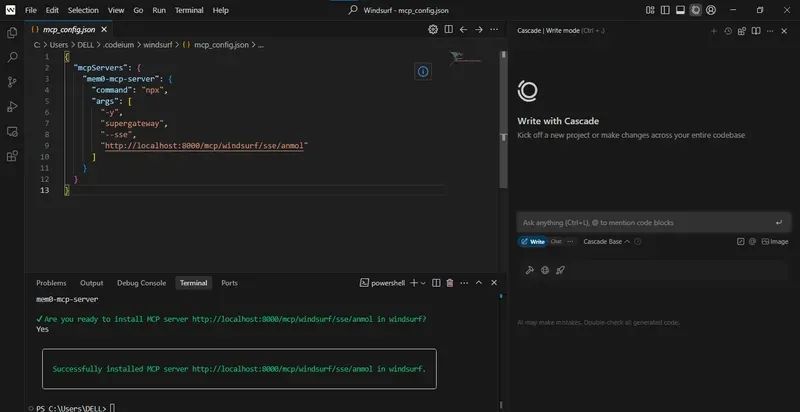
每个 MCP 客户端可调用以下四种标准记忆操作:
•add_memories(text) → 将文本存储在 Qdrant,插入/更新 Memory 行和审计条目•search_memory(query) → 嵌入查询,运行向量搜索(带可选 ACL 过滤),记录每次访问•list_memories() → 检索用户的所有存储向量(按 ACL 过滤)并记录列表操作•delete_all_memories() → 清除所有记忆
所有响应通过同一 SSE 连接流式传输。仪表板显示所有活动连接、访问记忆的应用程序以及读写详情。
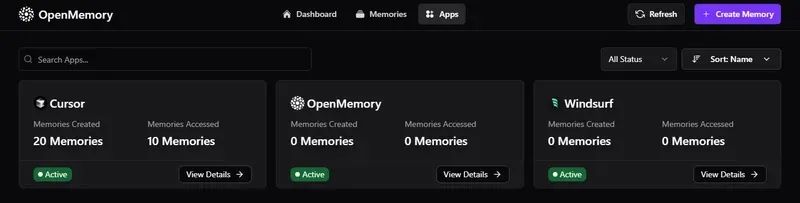
3. 仪表板功能(及其背后的技术)
OpenMemory 仪表板包含三个主要路由:
•/ – 仪表板首页•/memories – 查看和管理存储的记忆•/apps – 查看连接的应用程序
以下是仪表板提供的主要功能概览:
1) 安装 OpenMemory 客户端
•获取您的唯一 SSE 端点或使用一行安装命令。•在 MCP Link 和不同客户端选项卡(Claude、Cursor、Cline 等)之间切换。
2) 查看记忆和应用统计
•查看存储的记忆数量。•查看连接的应用程序数量。•输入任意文本以实时搜索所有记忆(去抖动处理)。•相关代码位于 ui/components/dashboard/Stats.tsx,功能包括:•从 Redux 读取(profile.totalMemories、profile.totalApps、profile.apps[])。•在挂载时调用 useStats().fetchStats() 填充存储。•渲染“总记忆数”和“连接的应用总数”,显示最多 4 个应用图标。

3) 刷新或手动创建记忆
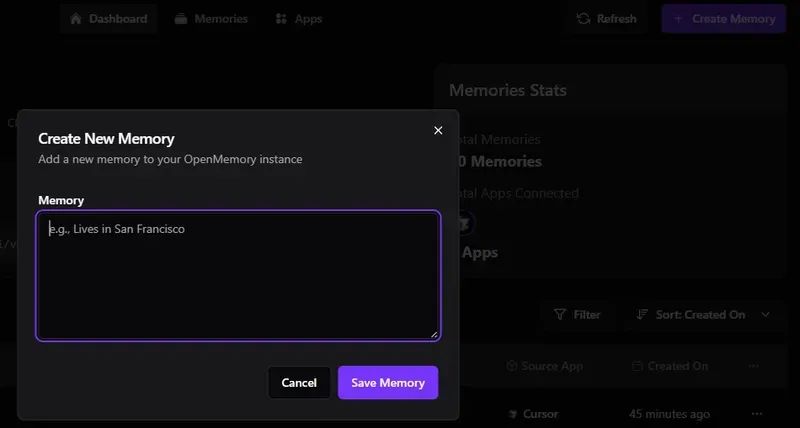
•刷新按钮:重新调用当前路由的相应获取器。•创建记忆按钮:打开 CreateMemoryDialog 模态框。
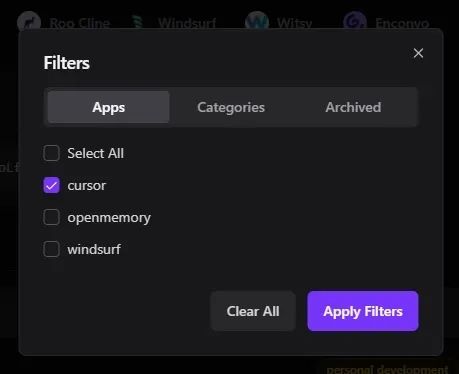
4) 过滤面板
•可选择:•包含哪些应用•包含哪些类别•是否显示归档项目•按哪列排序(记忆、应用名称、创建时间)•一键清除所有过滤器。
5) 检查和管理单个记忆
•点击任意记忆可:
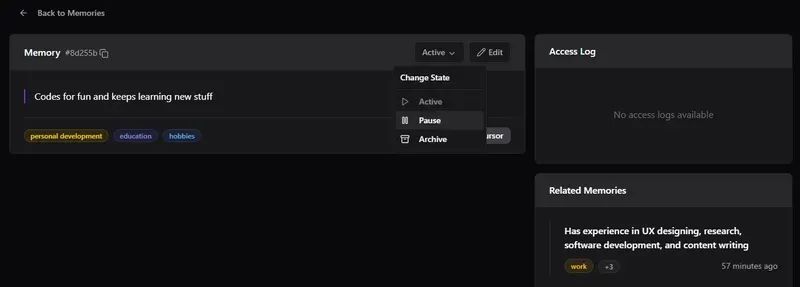
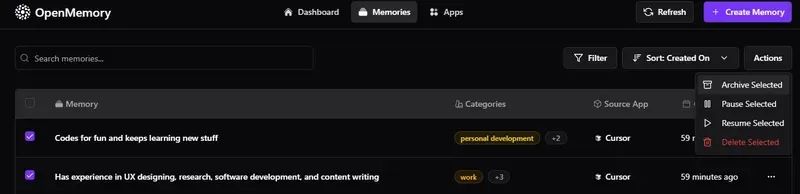
•归档、暂停、恢复或删除记忆•查看访问日志和相关记忆•支持选择多个记忆并执行批量操作。
🖥️ 背后技术:关键组件
以下是涉及的主要前端组件:
•ui/app/memories/components/MemoryFilters.tsx:处理搜索输入、过滤对话框触发器、批量操作(如归档/暂停/删除),并管理行选择状态。•ui/app/memories/components/MemoriesSection.tsx:加载、分页和显示记忆列表的主容器。•ui/app/memories/components/MemoryTable.tsx:渲染记忆表格(ID、内容、客户端、标签、创建日期、状态)。每行通过 MemoryActions 提供操作(编辑、删除、复制链接)。•状态管理和 API 调用使用以下钩子:•useStats.ts:加载高级统计数据,如总记忆数和应用数。•useMemoriesApi.ts:处理记忆的获取、删除和更新。•useAppsApi.ts:检索应用信息和每个应用的记忆详情。•useFiltersApi.ts:支持获取类别和更新过滤器状态。
这些组件共同打造了一个响应式、实时的仪表板,让您完全掌控 AI 记忆层。
4. 安全性、访问控制和架构概述
在处理 MCP 协议或任何 AI 代理系统时,安全性至关重要。以下是简要讨论。
🎯 安全性
OpenMemory 遵循隐私优先原则,所有记忆数据存储在您的本地基础设施中,使用 Docker 化的组件(FastAPI、Postgres、Qdrant)。
敏感输入通过 SQLAlchemy 的参数绑定安全处理,防止注入攻击。每次记忆交互(添加、检索、状态变更)都会通过 MemoryStatusHistory 和 MemoryAccessLog 表记录以确保可追溯性。
虽然未内置认证,但所有端点需要 user_id,并可通过外部认证网关(如 OAuth 或 JWT)保护。
FastAPI 的 CORS 在本地/开发环境中为开放状态(allow_origins=["*"]),但在生产环境中,您应收紧此设置以限制仅信任客户端访问。
🎯 访问控制
OpenMemory 注重细粒度访问控制。access_controls 表定义了应用与特定记忆之间的允许/拒绝规则。
这些规则通过 check_memory_access_permissions 函数强制执行,考虑记忆状态(活动、暂停等)、应用活动状态(is_active)和 ACL 规则。
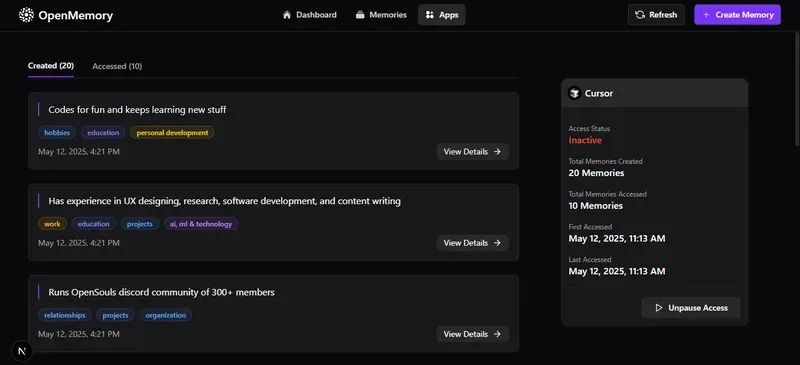
在实践中,您可以暂停整个应用(禁用写入)、归档或暂停单个记忆,或按类别或用户应用过滤器。暂停或非活动条目对工具访问和搜索不可见。这种分层访问模型确保您可以自信地控制记忆访问。
🎯 架构
以下是系统架构的简要概述,更多详情可参考代码库:
1.后端(FastAPI + FastMCP over SSE):•提供 REST 接口(/api/v1/memories、/api/v1/apps、/api/v1/stats)和 MCP “工具”接口(/mcp/messages、/mcp/sse/<client>/<user>),代理通过 SSE 调用 add_memories、search_memory、list_memories。•连接 Postgres 存储关系元数据,连接 Qdrant 进行向量搜索。2.向量存储(通过 mem0 客户端的 Qdrant):•所有记忆在 Qdrant 中进行语义索引,查询时应用用户和应用特定过滤器。3.关系元数据(SQLAlchemy + Alembic):•跟踪用户、应用、记忆条目、访问日志、类别和访问控制。•Alembic 管理架构迁移。•默认数据库为 SQLite(openmemory.db),但可通过 DATABASE_URL 指向 Postgres。4.前端仪表板(Next.js):•Redux 提供实时可观察性界面。•Hooks + Redux Toolkit 管理状态,Axios 与 FastAPI 端点通信。•使用 Recharts 实现实时图表、轮播和 React Hook Form 处理表单。5.基础设施与开发工作流:•docker-compose.yml(api/docker-compose.yml)包含 Qdrant 服务和 API 服务。•Makefile 提供迁移、测试、热重载的快捷方式。•测试与后端逻辑共存(通过 pytest)。
这些组件共同打造了一个自托管的 LLM 记忆平台:
•⚡ 在关系数据库和向量索引中存储和版本化聊天记忆•⚡ 通过每个应用的 ACL 和状态转换(活动/暂停/归档)保护数据•⚡ 通过 Qdrant 进行语义搜索•⚡ 通过丰富的 Next.js UI 观察和控制
5. 实际应用案例及示例
熟悉 OpenMemory 后,您会发现它可用于任何需要 AI 跨交互记忆的场景,从而实现高度个性化。
以下是一些高级和创造性的使用方式:
✅ 多代理研究助手与记忆层
想象构建一个工具,其中不同 LLM 代理专注于不同研究领域(例如,一个处理学术论文,一个处理 GitHub 仓库,另一个处理新闻)。每个代理通过 add_memories(text) 存储其发现,主代理随后通过 search_memory(query) 检索所有先前结果。
技术流程:
•每个子代理为 MCP 客户端:•将检索数据的摘要添加到 OpenMemory。•使用 GPT 自动分类为记忆添加标签。•主代理打开 SSE 通道,使用 search_memory("最新扩散模型论文") 提取相关上下文。•仪表板显示每个代理存储的内容,您可通过 ACL 限制代理间的记忆访问。
提示:可添加 LangGraph 编排层,每个代理作为一个节点,跟踪记忆的写入/读取,可视化每个研究线程的知识流和来源。
✅ 具有跨会话持久记忆的智能会议助手
可构建一个会议记录工具(支持 Zoom、Google Meet 等),功能包括:
•通过 LLM 提取摘要。•跨会议记忆行动项。•在未来会议中自动检索相关上下文。
技术流程:
•每次会议后通过 add_memories(text) 存储会议记录和行动项。•下次会议前运行 search_memory("Project X 的未完成项")。•相关记忆(按适当类别标记)显示在 UI 中,审计日志跟踪记忆的读取时间和内容。
提示:与 Google Drive、Notion、GitHub 等工具集成,存储的行动项可链接到实时文档和任务。
✅ 随使用进化的代理编码助手
您的 CLI 编码助手可通过存储使用模式、常见问题、编码偏好和项目特定提示来学习您的工作方式。
技术流程:
•当您询问“为什么我的 SQLAlchemy 查询失败?”,助手通过 add_memories 存储错误和修复。•下次您输入“再次遇到 SQLAlchemy 连接问题”,助手自动运行 search_memory("sqlalchemy join issue") 检索先前修复。•通过 /memories 仪表板检查所有存储记忆,暂停过时或错误的记忆。
提示:可连接到 codemod 工具(如 jscodeshift),根据存储的偏好自动重构代码,随代码库发展而演进。
在上述案例中,OpenMemory 的向量搜索(用于语义召回)、关系元数据(用于审计/日志记录)和实时仪表板(用于可观察性和即时访问控制)让您能够构建上下文感知的应用程序,感觉就像它们拥有记忆。
现在,您的 MCP 客户端拥有真正的记忆能力。
您可以跟踪每次访问、暂停所需内容并在一个仪表板中审计所有操作。最棒的是,所有内容都存储在您的本地系统上。
如有任何问题或反馈,请告诉我。
祝您愉快!下次见 🙂
如果您喜欢本文内容,请点赞 🙂
继续学习。
References
[1] mem0.ai/openmemory-mcp: https://mem0.ai/openmemory-mcp[2] github.com/mem0ai/mem0: https://github.com/mem0ai/mem0
(文:PyTorch研习社)