

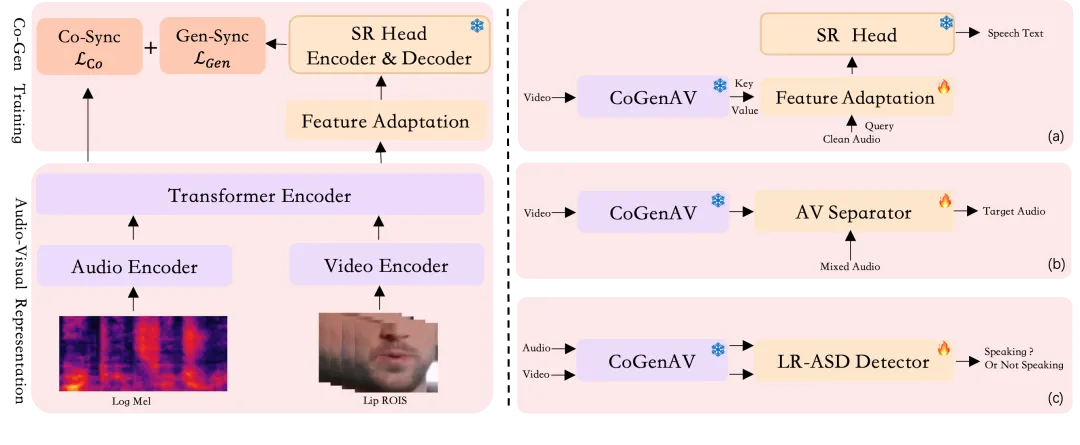
CoGenAV 的核心框架由两个关键部分组成:音视频特征表示和对比生成同步训练机制。
在特征提取阶段,模型采用 ResNet 3D CNN 来分析视频中说话人的唇部动作,捕捉声音与口型之间的动态关联;同时用 Transformer 编码器提取音频中的语音信息。这些音视频特征会被精确对齐,确保“听到的声音”和“看到的嘴型”在时间上完全匹配。
对比生成同步训练通过两种方式提升模型的理解能力:
-
对比同步,采用 Seq2Seq Contrastive Learning 方法,增强音频与视频特征之间的对应关系,帮助模型更准确地识别声音与口型的匹配。同时引入 ReLU 激活函数,过滤掉不相关的干扰帧,提升模型在复杂环境下的稳定性。
-
生成同步,借助一个预训练 ASR 模型(如 Whisper)作为“老师”,将 CoGenAV 提取的音视频特征与其声学-文本表示对齐。为了弥补不同模态之间的差异,模型设计了一个轻量级适配模块(Delta Upsampler + GatedFFN MHA),有效提升了跨模态融合效率。
这套“双轮驱动”的训练策略,使 CoGenAV 在多个语音任务中都表现出色,真正实现了“听清 + 看懂”的多模态理解。
参考文献:
[1] GitHub:https://github.com/HumanMLLM/CoGenAV
[2] arivx:https://arxiv.org/pdf/2505.03186
[3] HuggingFace:https://huggingface.co/detao/CoGenAV
[4] ModelScope:https://modelscope.cn/models/iic/cogenav
[5] CoGenAV 音画同步来破局:https://mp.weixin.qq.com/s/6TqqYJSNStY6YM6Q-6vbVw
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)