
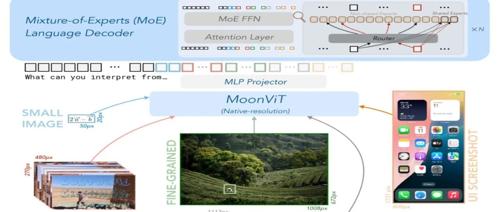

一、模型概述
Kimi-VL 是一款开源多模态大模型,基于轻量级 MoE 模型 Moonlight(16B 总参数,2.8B 激活参数)和原生分辨率的 MoonViT 视觉编码器(400M 参数)。Kimi-VL 支持单图、多图、视频和长文档等多种输入形式,在图像感知、数学、多学科题目、OCR 等任务中表现出色,尤其在长上下文(128K)和复杂推理方面具有显著优势。在多个权威基准测试中,Kimi-VL 超越了 GPT-4o、Qwen2.5-VL、DeepSeek-VL2 等模型,展现出卓越的智能水平。
此外,Kimi-VL 还推出了支持长思考的模型版本 Kimi-VL-Thinking,通过长链推理微调和强化学习,仅用 2.8B 激活参数,在较高推理难度的基准测试中,部分成绩接近甚至超过超大尺寸的前沿模型。
Kimi-VL 提供两个主要版本:
-
Kimi-VL-A3B-Instruct:专为高效推理设计,适用于多模态感知、OCR、长视频和长文档处理等任务。
-
Kimi-VL-A3B-Thinking:针对复杂推理任务优化,如数学推理和逻辑推理,通过长链推理(CoT)微调和强化学习提升推理能力
二、Kimi-VL 的技术架构
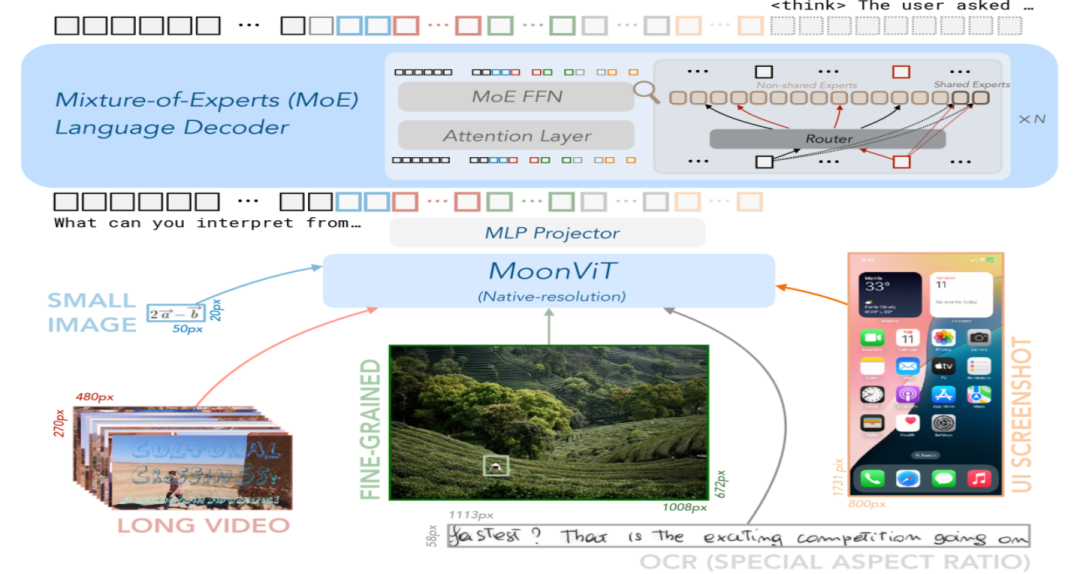
Kimi-VL 的架构由视觉编码器、MLP 投影层和 MoE 语言解码器三个部分组成,如下图所示:
(一)视觉编码器(MoonViT)
视觉编码器 MoonViT 是 Kimi-VL 的核心组件之一,基于 400M 参数的 Vision Transformer 架构,能够原生分辨率处理图像,无需对图像进行分割或拼接。MoonViT 引入了 NaViT 中的打包方法,将图像划分为图像块,展平后串联成一维序列,与语言模型共享相同的算子和优化方法。此外,MoonViT 还结合了插值绝对位置嵌入和二维旋转位置嵌入(RoPE),增强了对高分辨率图像的细节感知能力。
(二)MLP 投影层(Projector)
MLP 投影层采用双层 MLP 结构,将视觉编码器的连续输出特征通过像素重排操作进行空间维度的降采样,同时扩展通道维度。投影后的视觉特征 tokens 长度随输入图像的尺寸和处理方式动态变化,实现了视觉与语言模态间的灵活、高效融合。
(三)MoE 语言解码器(Moonlight)
MoE 语言解码器基于月之暗面自主研发的 Moonlight 模型,采用 Mixture-of-Experts 架构,仅激活 2.8B 参数,即可达到较大模型的性能水平。这种架构大大降低了推理成本,同时保持了强大的语言生成能力。Moonlight 模型从预训练阶段的中间检查点初始化,已处理过 5.2T token 的纯文本数据,激活了 8K 的上下文长度。通过混合训练方案,继续预训练 2.3T token 的多模态和纯文本数据。
三、Kimi-VL 的训练方法
Kimi-VL 的训练过程分为多个阶段,包括视觉预训练、联合预训练、联合冷却阶段、多模态联合长上下文激活阶段、多模态联合 SFT、长思维链 SFT 和强化学习等。这些阶段的设计旨在逐步提升模型的多模态理解能力、推理能力和对话能力。
(一)视觉预训练阶段
在视觉预训练阶段,MoonViT 视觉编码器使用大规模图文对数据进行训练,包括图片 alt 文本、OCR 文字、生成的描述、边界框标注等。训练目标包括 SigLIP 风格的对比损失(SigLIP loss)和图像引导下的文本生成(caption loss),提升视觉表征能力。
(二)联合预训练阶段
联合预训练阶段将已完成纯文本预训练的 MoE 语言模型(Moonlight)与视觉编码器 MoonViT 进行联合训练。使用 1.4T tokens 的混合数据(文本 + 图文),采用逐步增加图文比例的方式,确保语言能力不被弱化。
(三)联合冷却阶段
联合冷却阶段的核心目标是利用更高质量的语言与多模态数据,在不干扰模型已有能力的前提下,强化其在数学推理、代码生成、知识问答等领域的表现。通过精细化的数据调度策略,模型在保持泛化能力的同时,能够精准提升目标任务上的表现。
(四)多模态联合长上下文激活阶段
该阶段通过两轮训练将上下文长度由 8K 扩展至 128K tokens,每个子阶段都将上下文长度扩大四倍。训练数据包括长文本和多种类型的长多模态数据,使模型在纯文本和多模态输入场景中均能激活长上下文能力。
(五)多模态联合 SFT
多模态联合 SFT 阶段通过指令微调对 Kimi-VL 的基座模型进行训练,增强其指令跟随能力与对话互动能力。训练数据包含纯文本与图文混合形式的监督微调数据,采用学习率衰减策略进行优化。
(六)长思维链 SFT
长思维链 SFT 阶段使用经过筛选的 RL prompt 数据和 prompt 工程构建的长链式思维数据集,通过轻量级 SFT 训练,使模型能够生成具备“规划、评估、反思、探索”等人类类推理过程的推理链条,提升其在复杂任务中的思考深度与逻辑连贯性。
(七)强化学习
强化学习阶段采用变体的在线 Policy Mirror Descent 算法,优化策略模型 π,以提升模型问题求解的准确率。通过课程学习采样和优先级采样策略,模型能够更加集中精力学习具有教学意义的样本,最终发展出关键的元推理能力。
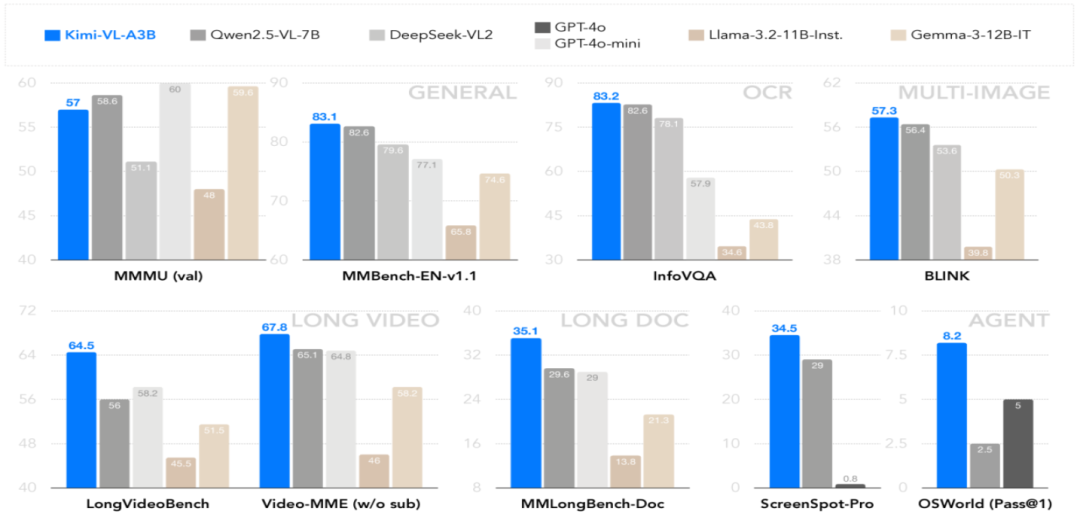
四、Kimi-VL 的性能优势
(一)高智力
Kimi-VL 在多模态推理和多步骤 Agent 任务中表现出色,文本处理能力也毫不逊色于纯文本语言模型。在 MMMU、MathVista、OSWorld 等基准测试中,Kimi-VL 无需依赖“长思考”能力,即可取得令人瞩目的成绩,展现卓越的智能水平。
(二)长上下文
Kimi-VL 拥有 128K 的超长上下文窗口,在处理长视频和长文档任务时,如 LongVideoBench 和 MMLongBench-Doc 基准测试,表现远超同级别其他模型,支持精准地检索和理解海量信息,为复杂任务提供更全面的上下文支持。
(三)更强的视觉能力
与其他开源视觉语言模型相比,Kimi-VL 在视觉感知、视觉世界知识、OCR 及高分辨率屏幕快照解析等多个视觉场景中,均展现出全面且显著的竞争优势。对复杂图像的细节捕捉和对视觉信息的深度理解,Kimi-VL 都能精准高效地完成任务。
五、Kimi-VL 的应用场景
(一)智能客服
在智能客服领域,Kimi-VL 可以提供高效、精准的多轮对话服务。它能够理解客户的复杂问题,并通过分析历史对话记录,给出连贯且准确的解答。Kimi-VL 支持图文结合的交互方式,可以处理客户发送的图片、视频等多媒体内容,从而更全面地理解客户需求。
(二)教育辅导
在教育辅导方面,Kimi-VL 是一位出色的智能助手。它能够为学生提供图文并茂的解答和教学材料,帮助学生更好地理解复杂知识点。无论是数理化的公式推导,还是语文英语的文本分析,Kimi-VL 都能通过详细的推理过程和直观的图表展示,让学生轻松掌握。
(三)内容创作
对于内容创作者来说,Kimi-VL 是一个强大的辅助工具。它能够生成高质量的图文、视频内容,为创作者提供灵感和创意支持。
(四)医疗辅助
在医疗领域,Kimi-VL 具有巨大的应用潜力。它可以分析医学影像,如 X 光、CT、MRI 等,帮助医生快速准确地发现病变和异常。通过对大量医学影像数据的学习,Kimi-VL 能够识别各种疾病的特征,并提供初步诊断建议。
(五)企业办公
在企业办公环境中,Kimi-VL 能够高效处理长文档,提取关键信息,为决策提供支持。它可以快速阅读和分析大量的文本资料,如报告、合同、邮件等,提炼出核心内容和关键点。
六、快速使用
(一)安装依赖
# 创建环境conda create -n kimi-vl python=3.10 -yconda activate kimi-vl# 克隆代码git clone https://github.com/MoonshotAI/Kimi-VL.gitcd Kimi-VL# 安装依赖pip install -r requirements.txt
(二)模型推理
import torchfrom PIL import Imagefrom transformers import AutoModelForCausalLM, AutoProcessormodel_path = "moonshotai/Kimi-VL-A3B-Instruct"model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype="auto",device_map="auto",trust_remote_code=True,)# If flash-attn has been installed, it is recommended to set torch_dtype=torch.bfloat16 and attn_implementation="flash_attention_2"# to save memory and speed up inference# model = AutoModelForCausalLM.from_pretrained(# model_path,# torch_dtype=torch.bfloat16,# device_map="auto",# trust_remote_code=True,# attn_implementation="flash_attention_2"# )processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)image_path = "./figures/demo.png"image = Image.open(image_path)messages = [{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": "What is the dome building in the picture? Think step by step."}]}]text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")inputs = processor(images=image, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)generated_ids = model.generate(**inputs, max_new_tokens=512)generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]response = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]print(response)
七、总结
Kimi-VL 作为一款开源多模态大模型,凭借其独特的架构和高效的训练方法,在多模态任务中展现出了强大的性能。通过本文的介绍,大家可以快速了解 Kimi-VL 的技术细节,同时文中给出了推理示例,可以进一步探索其在实际场景中的应用潜力。未来,随着技术的不断发展,Kimi-VL 有望在更多领域发挥重要作用,为人工智能的发展注入新的动力。
八、项目资料
开源仓库:https://github.com/MoonshotAI/Kimi-VL
模型文件:https://huggingface.co/collections/moonshotai/kimi-vl
技术论文:https://github.com/MoonshotAI/Kimi-VL/blob/main/Kimi-VL.pdf
(文:小兵的AI视界)