



OpenAI正式发布GPT-5,这次的看点不在智力提升,而是使用体验优化。
按照OpenAI的官方说法,GPT-5是公司推出的最智能、最快、最实用的模型,内置思考功能,能让每个人都用上专家级智能。
此次发布的模型是一个“统一系统”,由三大部分构成:一是智能高效的基础模型,可处理多数问题;二是深度推理模型,用于解决复杂难题;三是实时路由决策器。

尽管GPT-5的发布令人振奋,但据The Information消息,GPT-5在开发过程中一直面临巨大挑战。虽说AI热潮由OpenAI掀起,但它能否持续带来重大技术突破,能否吸引企业用户投入巨资,始终受到质疑。
经济学家Noah Smith认为:“到目前为止,企业在人工智能上的投入相当有限,消费者的支出倒是不少,毕竟人们喜欢和ChatGPT交流,但消费者支出远远填不上巨额投入的窟窿。”
因此,对OpenAI乃至整个行业而言,GPT-5既有技术层面的考验,也有市场层面的检验。

2023年3月,OpenAI推出GPT-4,时隔两年半,跨代的GPT-5终于亮相,自然引发业界高度期待。
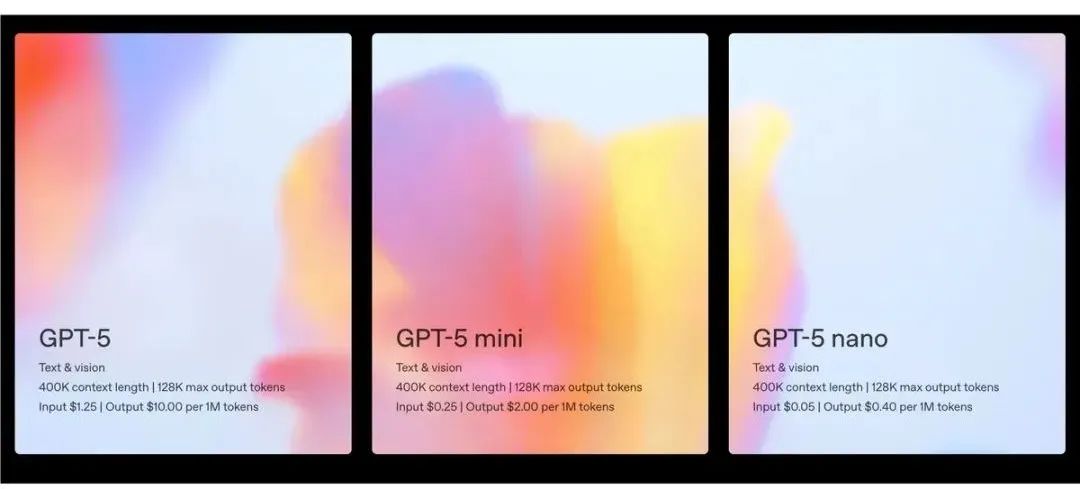
GPT-5共有四个版本,分别是GPT-5、GPT-5 Mini、GPT-5 Nano和GPT-5 Pro,它们在成本、运行速度和计算效率上各有不同,侧重点也不一样。
其中,GPT-5功能齐全,主要用于ChatGPT和API,可执行高质量通用任务。GPT-5 Pro相当于“增强版”,采用扩展推理和并行计算技术,能应用于复杂的企业和研究场景,给出的答案更详细、更可靠。
很快,GPT-5将成为ChatGPT的独家驱动模型,替代其他模型。对ChatGPT Pro订阅用户而言(月费200美元),未来60天内仍能自主选择使用旧版本。
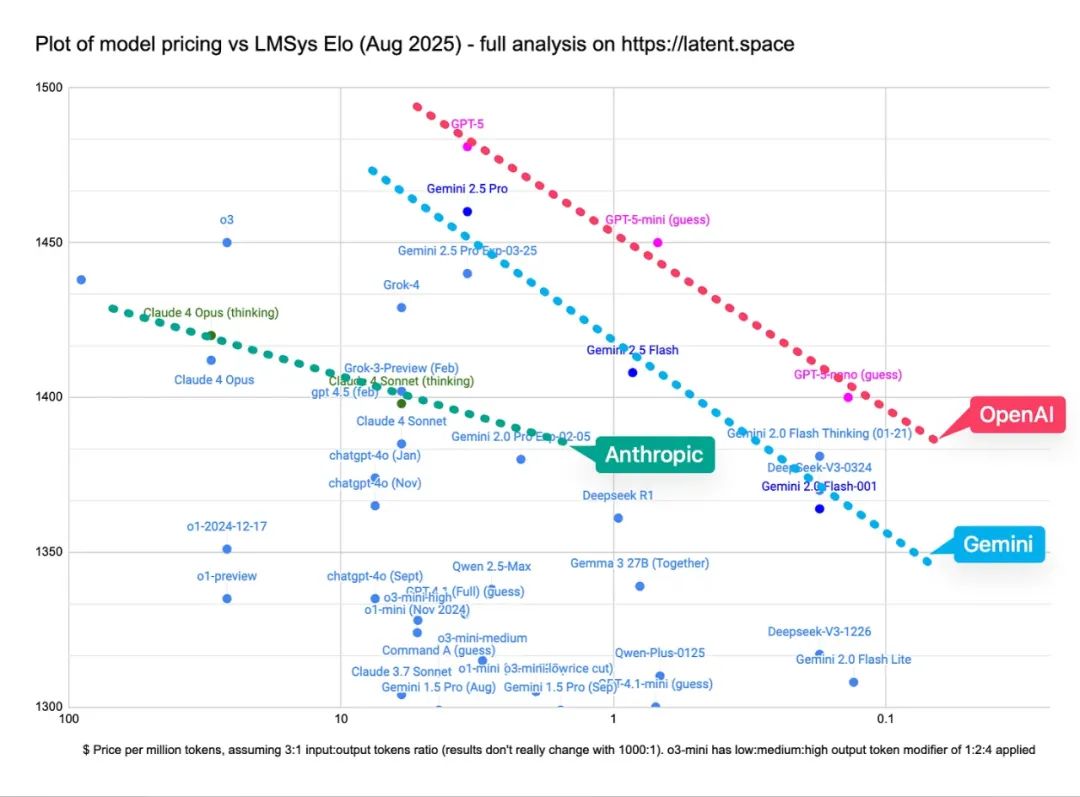
GPT-5、GPT-5 Mini和GPT-5 Nano主打推理功能,在API中对应的分别是gpt-5、gpt-5-mini和gpt-5-nano。需要注意的是,目前GPT-5 Pro暂未开放API访问权限,仅为ChatGPT Pro订阅用户提供服务。
一直以来,OpenAI都以开发AGI(通用人工智能)为目标,AGI智能可以超越人类智力。显然,GPT-5并非AGI,OpenAI离这个目标还有距离。
OpenAI在视频电话中表示:“多数人定义AGI时,总会缺少一些重要部分,而且很多都是相当关键的部分。模型部署后能持续学习就是很重要的一点,现在的GPT-5还做不到。”
OpenAI在回应媒体提问时澄清,GPT-5是迈向AGI的重要一步,在推理等方面有明显提升;由于定义不同,大家对AGI的理解也存在差异;尽管GPT-5达到了一些AGI的早期标准,但尚未完全迈过人类水平的AGI门槛,在持久记忆、自主性和任务适应性方面仍有局限。
相比过往模型,GPT-5更智能、用途更广。
整体来看,GPT-5的表现优于o3,出现幻觉的概率也低于以往模型。OpenAI官方称,GPT-5的幻觉率只有o3的六分之一。
本次升级,OpenAI特别重视写作、编程、健康三大领域的改进:
——快速生成美观的响应式网站、应用和游戏,在间距排版、字体运用和留白处理等方面有突破。
——在写作方面,GPT-5可以兼顾文学深度与韵律美感,完成日常写作任务时效率更高。
——在健康方面,与之前的模型相比,GPT-5更像一位积极的思考伙伴,能够主动提示潜在健康风险,通过提问给出更有价值的回答。
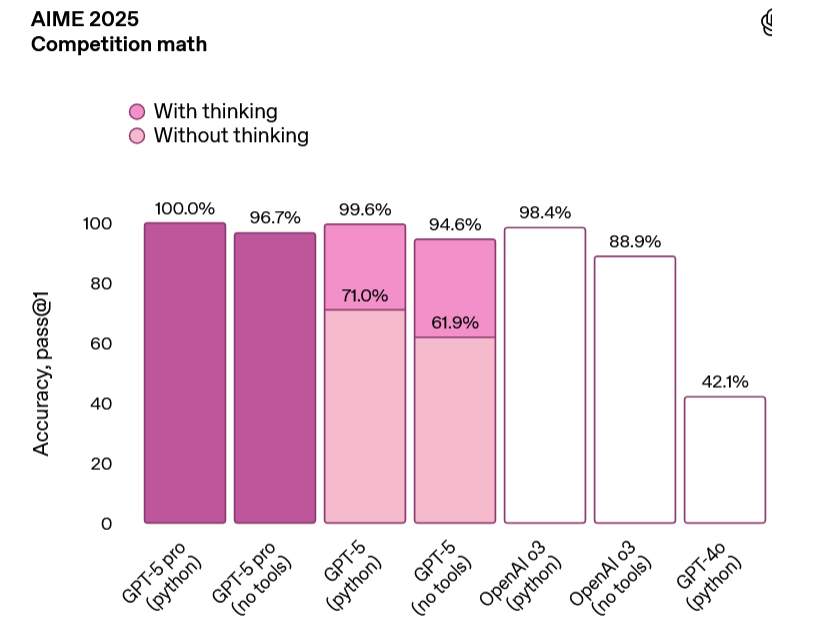
多项基准测试结果显示,GPT-5刷新了纪录。
——数学能力:在AIME 2025(无工具)测试中,得分为94.6%。
——编程能力:SWE-bench Verified(With thinking)得分为74.9%,Aider Polyglot(With thinking)得分为88%。
——多模态理解:在MMMU测试中得分84.2%。
——健康领域:在HealthBench Hard测试中得分46.2%。
上面的测试来自官方。
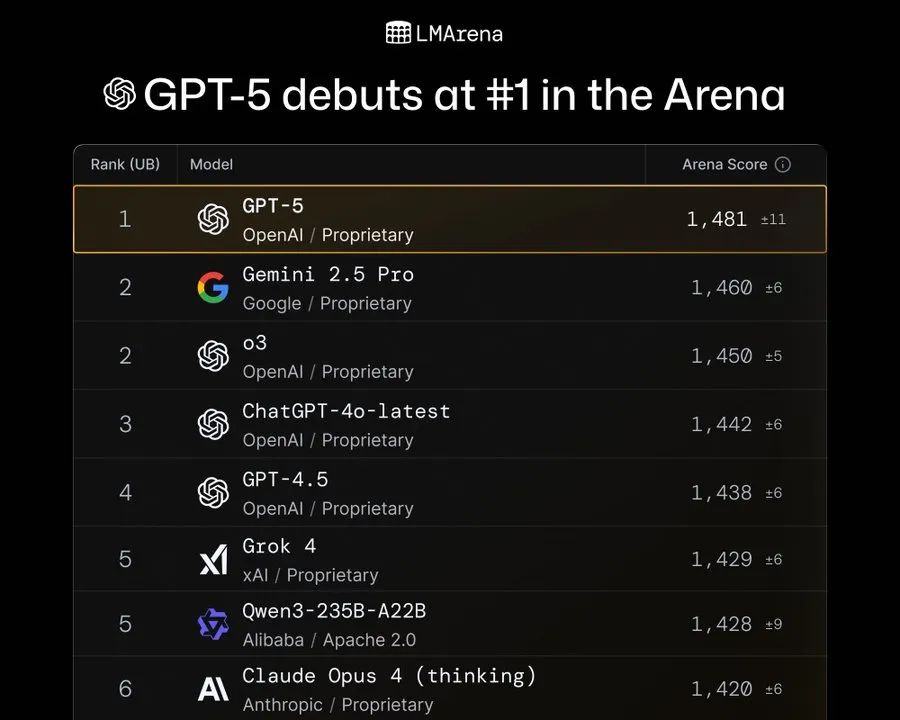
第一时间,民间爱好者也对GPT-5进行了测试。例如在Text Arena测试中,无论是硬提示、编程、数学、创意写作还是长查询,GPT-5都是第一名。
Text Arena主要用来评估模型处理复杂文本的能力,它通过动态对话和策略博弈测试模型的表现。
除此之外,GPT-5对人类的“阿谀奉承”减少,更加人性化。
对于GPT-5的性能,OpenAI给出自己的论断:“运用推理能力时,GPT-5在大约一半的案例中表现极好,与专家相当、甚至更出色,其表现也优于OpenAI o3和ChatGPT Agent。”
在GPT-5正式发布前,OpenAI创始人山姆・奥特曼通过X平台发布一张“死星”照片,未配任何文字。发布产品时,他在视频中宣称GPT-5是全领域专家,具备博士级水准,有了它,普通人能超越历史上任何个体。
尽管奥特曼的表述略带夸张,但OpenAI取得的成绩仍值得肯定。全球周活跃用户突破7亿,这无疑是一个里程碑式的数字。

面对竞争对手的步步紧逼,OpenAI承受着不小压力:既要吸引新用户,又要防止老用户流向竞品。据OpenAI内部测试,GPT-5在多项基准测试中保持领先,但这种领先并非全面碾压,在部分测试中,谷歌Gemini、Anthropic的Claude、xAI的Grok仍能与之抗衡。
在发布会材料中,OpenAI甚至犯下低级错误,出现标签错误、数据矛盾等疏漏,网友调侃“图表怕是GPT-5自己编的”。因此,面对五花八门的评测数据,我们更该关注实际体验:响应迅捷、操作直观、高度个性化,这些才是GPT-5真正的优势所在。
除最高级功能收费外,GPT-5延续了免费策略。为了对抗高速低价的Gemini,OpenAI推出同类版本竞争;当ClaudeCode席卷编程市场时,OpenAI迅速推出Codex应对。
放眼整个市场,头部大模型的能力已不相上下,基准测试成绩的重要性逐渐降低,竞争焦点正转向“体验”,尤其是整合数字生活的体验。
最终使用GPT-5时,我们或许不会因它的“智力”而惊叹,反而会被流畅的体验深深打动。ChatGPT负责人尼克・特利(Nick Turley)表示:“GPT-5模型用起来感觉特别好,我相信普通用户也会有同样感受,尤其是那些平时没花时间研究模型的人。”
最后让我们来听听几位行业专家们的观点。
Box是一家专为企业管理计算机文件的公司,近几周一直在测试GPT-5。公司CEO Aaron Levie表示,在多项高级测试中,以往模型表现欠佳,原因是它们难以理解长文档中的复杂数学内容或逻辑内容,而GPT-5在这些方面实现了彻底突破。
Aaron Levie认为:“GPT-5能够保留更多观察到的信息,并运用更高层次的推理和逻辑来做决策。”
康奈尔大学计算机科学助理教授John Thickstun从技术层面进行分析,他认为,依据GPT-5基准测试结果,它确有进步,但幅度适中;同时,GPT-5与GPT-4存在明显差异,GPT-5相当于重置了OpenAI的技术体系,为未来发展奠定了基础。
John Thickstun称:“相关工作尚未终结,人工智能无法自动解决人类所有问题,但我依然认为,AI技术还有很大提升空间,该领域的其他研究者也有望继续改进技术。”
在GPT-5中,OpenAI采取了诸多措施减少“幻觉”问题,内部评估显示,GPT-5的正确率高于GPT-4。

加州大学伯克利分校计算机科学教授Dawn Song认为:“‘幻觉’可能会引发真正的安全问题。”例如,智能体如果产生幻觉,可能会将恶意代码下载到设备中。
尽管GPT-5在多项基准测试中达到顶尖水平,但HuggingFace公司的AI研究员Clémentine Fourrier认为,基准测试已接近饱和,也就是说,当前模型的表现都很出色。
Clémentine Fourrier打比方说:“所谓基准测试,就像是让高中生解决中等难度的问题。如果失败,能说明一些问题;如果成功,其实说明不了太多。”她举例道,在SWE-Bench测试中,若得分能达到80%或85%,她会感到惊讶,而GPT-5的实际得分只有74.9%。
-END-

(文:头部科技)