

Ollama 概述
Ollama 是一个旨在快速运行大语言模型(LLM)的简便工具。通过 Ollama,用户无需复杂的环境配置,即可轻松与大语言模型进行交互。
本文将分析 Ollama 的整体架构,并详细解释用户在与 Ollama 进行对话时的处理流程。

Ollama 的整体架构

Ollama 采用经典的客户端-服务器(Client-Server, CS)架构,其中:
•客户端:通过命令行与用户交互。•服务器:可以通过以下方式之一启动:命令行、基于 Electron 框架的桌面应用程序或 Docker。无论采用哪种方式,最终都调用同一个可执行文件。•通信方式:客户端与服务器之间通过 HTTP 进行通信。
Ollama 服务器由两个核心组件组成:
•ollama-http-server:负责与客户端交互。•llama.cpp:作为 LLM 推理引擎,加载并运行大语言模型,处理推理请求并返回结果。
ollama-http-server 与 llama.cpp 之间的通信也通过 HTTP 进行。
注:
llama.cpp是一个独立的开源项目,以其跨平台和硬件友好性而闻名。它可以在没有 GPU 的情况下运行,甚至可以在树莓派等设备上运行。
Ollama 的存储结构
Ollama 默认的本地存储文件夹为 $HOME/.ollama,其文件结构如下:
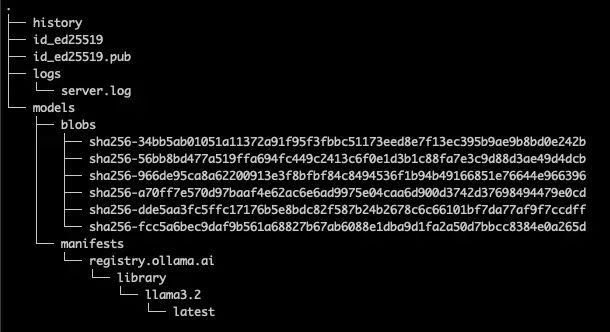
文件可分为三类:
•日志文件:包括记录用户输入的 history 文件和服务器日志文件 logs/server.log。•密钥文件:包括私钥 id_ed25519 和公钥 id_ed25519.pub。•模型文件:包括 blobs 文件夹中的原始数据文件和 manifests 文件夹中的元数据文件。
例如,元数据文件 models/manifests/registry.ollama.ai/library/llama3.2/latest 的内容如下:
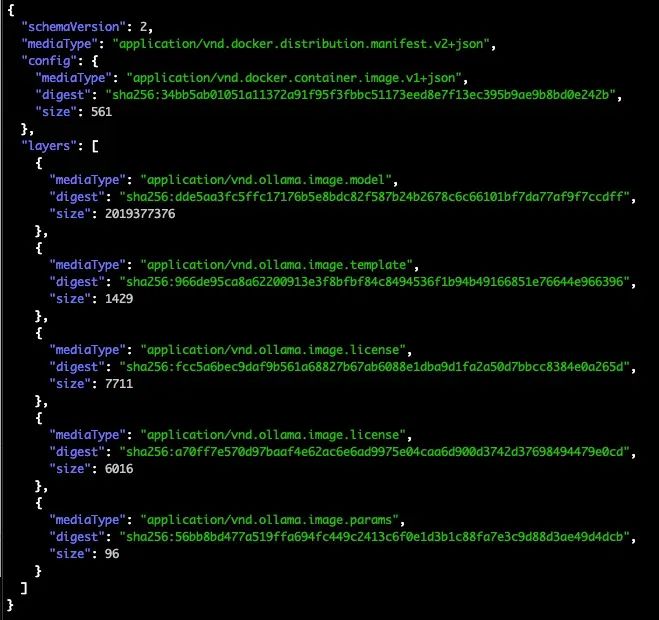
如上所示,manifests 文件采用 JSON 格式。其结构借鉴了云原生和容器领域中使用的 OCI(Open Container Initiative) 规范。manifests 文件中的 digest 字段对应于 blobs 文件夹中的实际模型数据。
Ollama 的对话处理流程
用户与 Ollama 之间的对话过程可分为以下几个步骤:
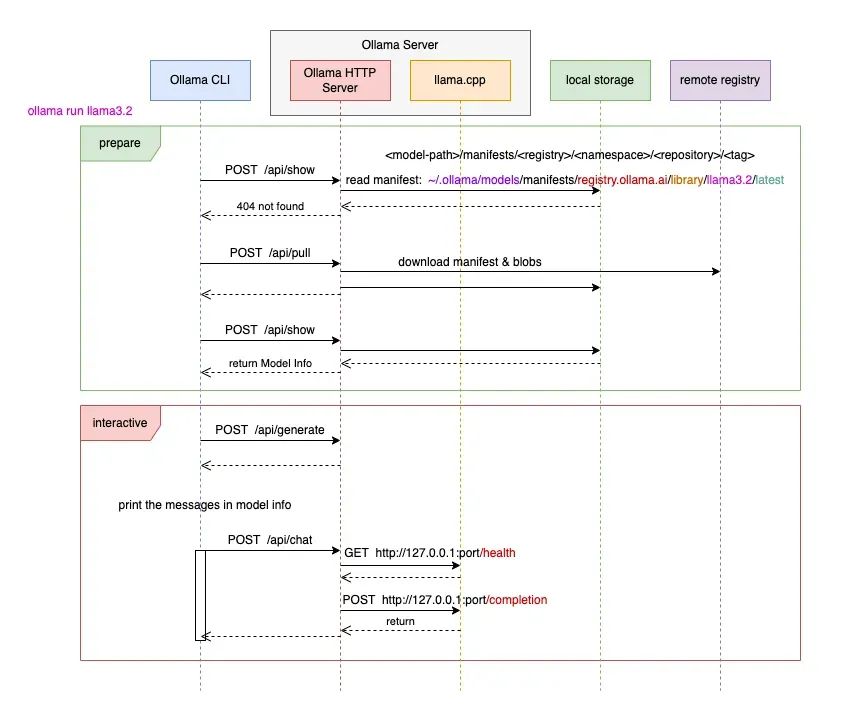
1. 启动命令
用户通过执行 CLI 命令:
ollama run llama3.2其中llama3.2 是一个开源的大语言模型(当然也可以使用其他 LLM)来启动对话。
2. 准备阶段
•CLI 客户端向 ollama-http-server 发送 HTTP 请求以获取模型信息。服务器尝试读取本地的 manifests 元数据文件;如果该文件不存在,则返回 404 not found 错误。•如果未找到模型,CLI 客户端会向服务器发送请求拉取模型,服务器从远程存储库下载模型到本地。•CLI 客户端再次请求获取模型信息。
3. 交互式对话阶段
•CLI 向 ollama-http-server 的 /api/generate 端点发送一个空消息,服务器进行一些内部通道处理(Go 语言中的 channel)。•如果模型信息中包含初始消息,则打印出来。用户可以基于当前模型和会话历史创建一个新模型,对话历史将被保存为 messages。•正式对话开始:CLI 向 /api/chat 端点发送请求。
此时,ollama-http-server:
1.向 llama.cpp 的 /health 端点发送请求以确认其健康状态;2.然后向 /completion 发送请求以获得对话响应;3.最后将响应返回给 CLI 并显示在终端上。
通过这些步骤,Ollama 实现了用户与大语言模型之间的高效交互。
结论
通过集成 llama.cpp 推理引擎,Ollama 简化了 LLM 技术的复杂性,使其变得易于访问和用户友好。它为开发人员和技术专业人员提供了一个高效且灵活的大语言模型推理和交互工具,在各种应用场景中大有裨益。
参考资料
https://github.com/ollama/ollama
https://github.com/ggerganov/llama.cpp
(文:PyTorch研习社)