


随着 GPT-4o 生成能力的爆火,很多人都在研究怎么让模型既能看懂图片、视频(理解任务),又能根据文字生成图片、视频(生成任务)。
自回归模型(就是那种一个接一个预测下一个“词”的模型)在这两方面都取得了很大进展,比如现在有很多厉害的文生图、文生视频模型,还有很多强大的多模态大语言模型(MLLM)能理解图文信息。
自然而然地,研究人员就想把这两种能力整合到一个模型里,搞一个“全能型”的 MLLM,让它用一套系统既能理解世界,又能创造世界。
但是,这里有个大难题:视觉信息的“翻译”方式不一样。
-
理解任务(比如看图回答问题)需要的“翻译器”(视觉 tokenizer)得能抓住图片里的高层语义信息,明白“这画的是啥意思”。像 CLIP 这种就擅长这个,但它不太关心像素级的细节,所以直接拿去做生成效果不好。
-
生成任务(比如画画)需要的“翻译器”则必须捕捉图像的精细纹理和细节,才能画出逼真的图片。像 VQVAE 这类就很适合生成,但它可能抓不住图片整体的含义,不太适合直接用于理解任务。
如何处理任务之间的差距,使用统一的框架处理不同的任务?本篇文章总结了近期多篇相关的研究工作,从视觉 Tokenizer 的优化、模型架构的创新到训练策略的改进,全面梳理了多模态理解与生成统一的最新进展。
接下来,我们将深入探讨这些技术突破如何解决“翻译”难题,并为构建真正的“全能型” MLLM 指明方向。

字节跳动—UniTok
论文标题:
UniTok: A Unified Tokenizer for Visual Generation and Understanding
论文链接:
https://arxiv.org/abs/2502.20321
代码链接:
https://github.com/FoundationVision/UniTok
理解和生成两边好像有点“水火不容”。以前有人试过给每个任务用单独的翻译器,但这让模型变得更复杂,并没有从根本上解决问题。所以,大家迫切需要一个统一的视觉翻译器(tokenizer)或者相应的训练策略,既能搞定生成,也能搞定理解。这篇论文针对上述的挑战和疑问,做出了以下几个主要贡献:
重新审视了“目标冲突”问题:通过一系列实验分析,研究人员发现,之前统一 tokenizer 训练困难、效果不佳的主要原因,并非生成(重建)和理解(对比学习)两个目标本身的冲突。
他们发现,即使去掉重建任务,只训练一个向量量化的 CLIP 模型(也就是只关注理解),其性能也不如标准的 CLIP。
这说明问题出在向量量化(vector quantization)这个操作本身。也就是说,现有的离散视觉“词汇”太贫乏了,不足以同时承载生成所需的细节和理解所需的语义。这才是统一 tokenizer 效果上不去的根本原因。
提出了多码本量化(Multi-codebook Quantization)技术:为了解决离散 token 表达能力不足的问题,一个直观的想法是增加“字典”(codebook)的大小或者 token 的维度。但这样做容易导致很多“词汇”根本用不上(codebook utilization 低),效果提升有限,而且计算开销也大。
受到“分而治之”思想的启发,研究人员提出了多码本量化。简单来说,就是不搞一个大字典,而是把一个视觉 token 切成几块,每一块用一个独立的、小一点的子字典(sub-codebook)来进行量化。
这就像 Transformer 里的多头注意力机制一样,通过增加子字典的数量来指数级地扩大潜在的编码空间,同时又避免了单个大字典训练不稳定的问题。
本文推出了 UniTok:基于多码本量化技术,他们训练出了一个名为 UniTok 的新型统一视觉 tokenizer。
1.1 方法详解:如何打造一个全能视觉翻译器
统一的训练目标
首先,为了让这个翻译器同时具备生成和理解的能力,研究人员给它设定了两个训练目标,让它在训练时同时学习:
1. 重建细节(VQVAE-based Loss):这部分是为了保证翻译器能准确地记住图片的细节,以便能高质量地重建(画出)图片。这个损失 包含了好几个部分:
:像素级别的重建误差,看生成的图片和原图像素差多少。
:感知损失,用 LPIPS 指标衡量,更关注人眼看起来像不像。
:判别器损失,引入一个判别器来判断生成的图片够不够真实,提升保真度。
:向量量化损失,让编码器的输出尽量靠近“字典”里已有的词汇。
总的重建损失是这几项加权求和:
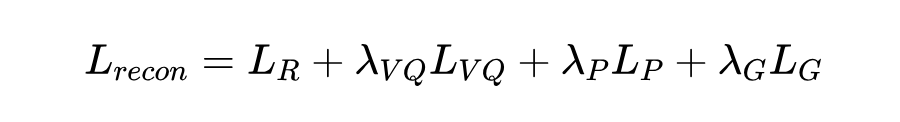
(这里的 是各项损失的权重系数)
2. 理解语义(Image-Text Contrastive Loss):这部分是为了让翻译器产生的视觉“词汇”带有丰富的语义信息,能和文本对齐,就像 CLIP 做的那样。这个损失 基本上和 CLIP 用的损失函数一样。
最终的总损失就是把这两个目标加起来:
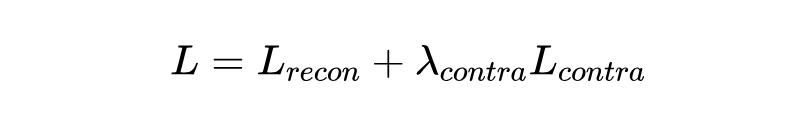
(论文里提到,他们简单地把对比损失的权重 设为了 1)
1.2 揪出性能瓶颈:量化过程是关键
研究人员发现,虽然想法很好,但光是把这两个目标加起来训练,理解能力还是比不过专门的 CLIP,效果不太行。于是他们深入分析了从 CLIP 到这种统一 tokenizer 的过程中,到底是什么影响了性能(见下图 3 的分析过程):
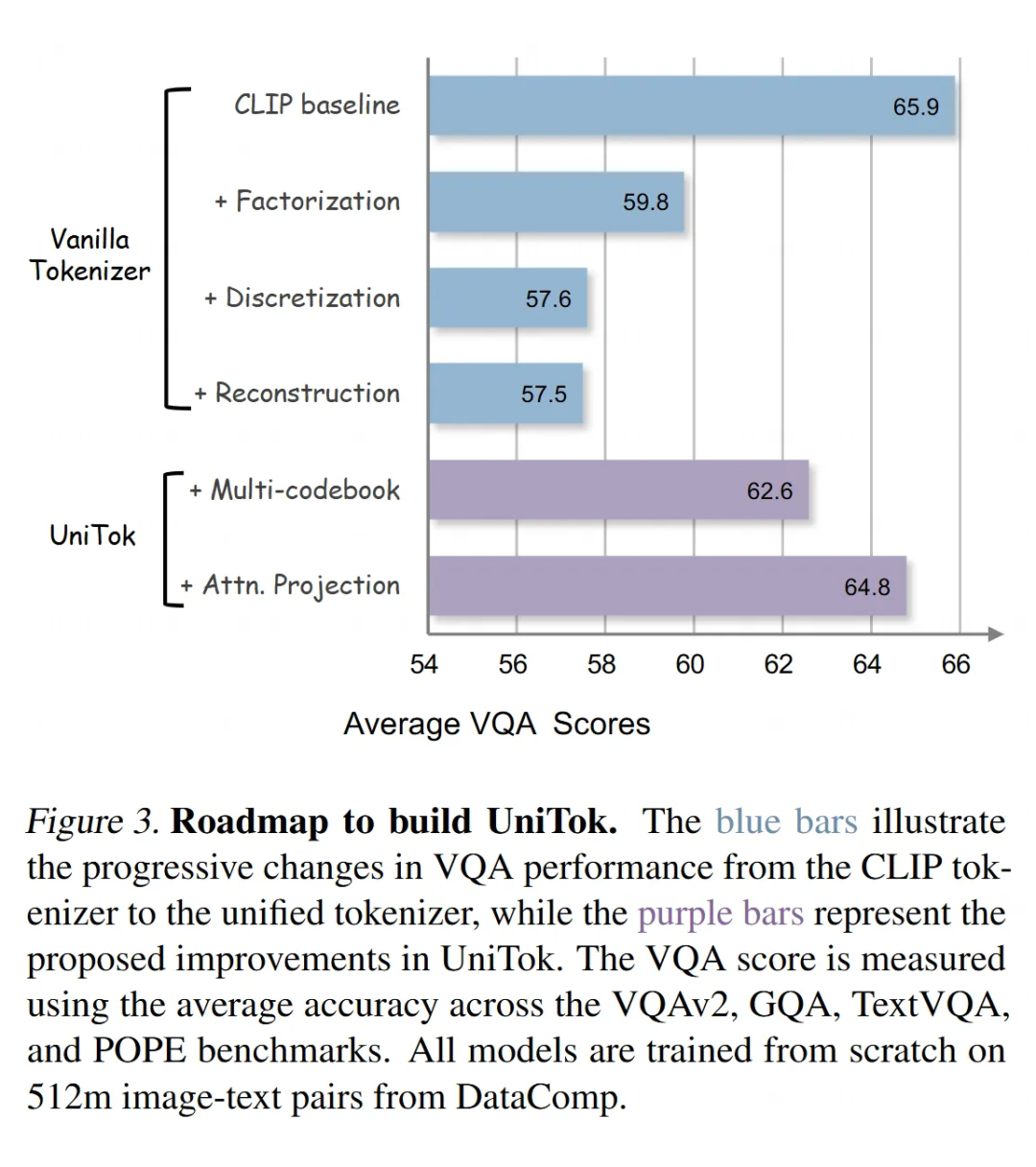
Token 分解(Factorization):现在的 VQ 类 tokenizer 通常会先把高维的视觉特征(比如 768 维)压缩到一个很低的维度(比如 16 维),再去查字典找对应的离散 token。
这个过程叫“分解”。他们发现,即使只是在 CLIP 模型里加上这个简单的线性压缩再解压的操作(还没加量化和重建),模型在下游问答任务(VQA)上的性能就会大幅下降。这说明这种简单的压缩方式损失了太多重要信息。
离散化(Discretization):在分解的基础上,再把压缩后的低维特征强制映射到“字典”(codebook)里最接近的那个离散 token 上,这就是离散化。视觉 tokenizer 的字典通常比语言模型小得多(比如只有 4k 到 16k 个词)。
研究发现,把连续特征硬塞进这么小的离散空间,又会造成明显的信息损失,导致 VQA 性能再次下降。
结论:研究人员因此认为,所谓的“损失冲突”只是表面现象,真正限制统一 tokenizer 性能的根本原因,是离散 token 本身的表达能力太有限了,装不下那么多信息。
1.3 核心技术:提升 Token 表达力
为了打破这个瓶颈,研究人员提出了两个关键技术:
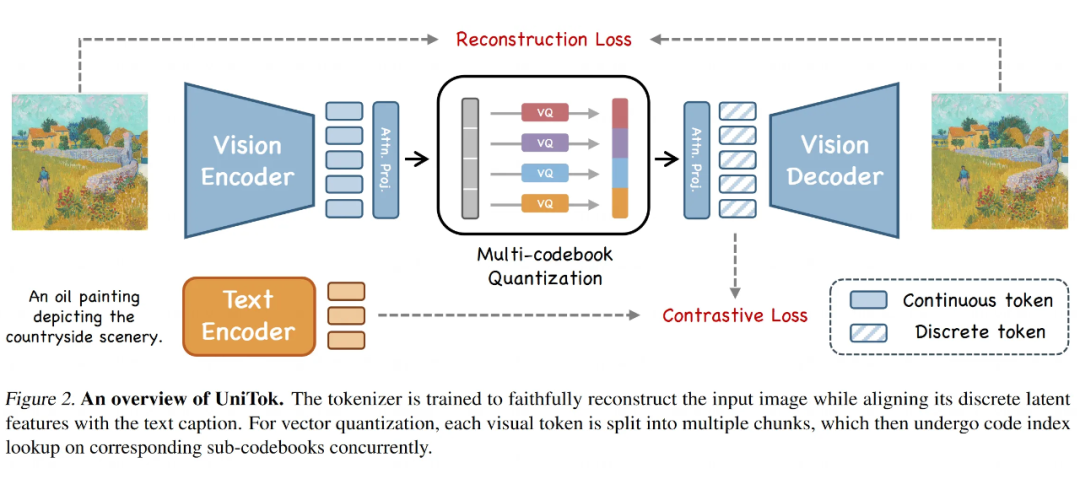
多码本量化(Multi-codebook Quantization, MCQ):
想法:既然一个字典不够用,那就用多个小字典!具体来说,他们把一个低维的视觉特征向量 (比如 64 维)切成 小块 (比如切成 8 块,每块 8 维)。
操作:然后,每一小块 都用一个独立的子字典 去进行量化(查字典找最近的词),得到量化后的块 。
合并:最后把所有量化后的子块拼起来,得到最终的离散表示 。
公式表示为:
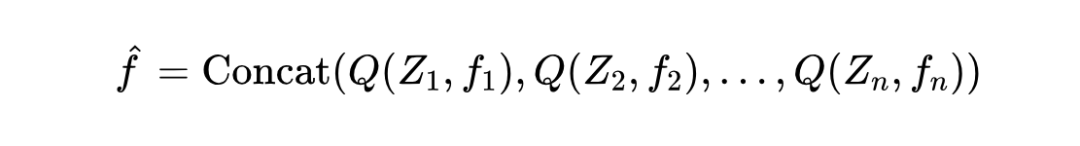
好处:这样做的好处是,虽然每个子字典 可能不大(比如 4096 个词),但组合起来能表达的可能性就指数级增长了(比如 8 个 4k 的子字典,理论词汇量达到 ,远超单个大字典)。
这极大地提升了离散 token 的表达空间,同时因为每个子字典规模可控,又避免了训练单个超大字典的优化难题。而且,潜在的编码维度也随着子字典数量增加了(比如 8 个 8 维子块,总维度 64 维)。
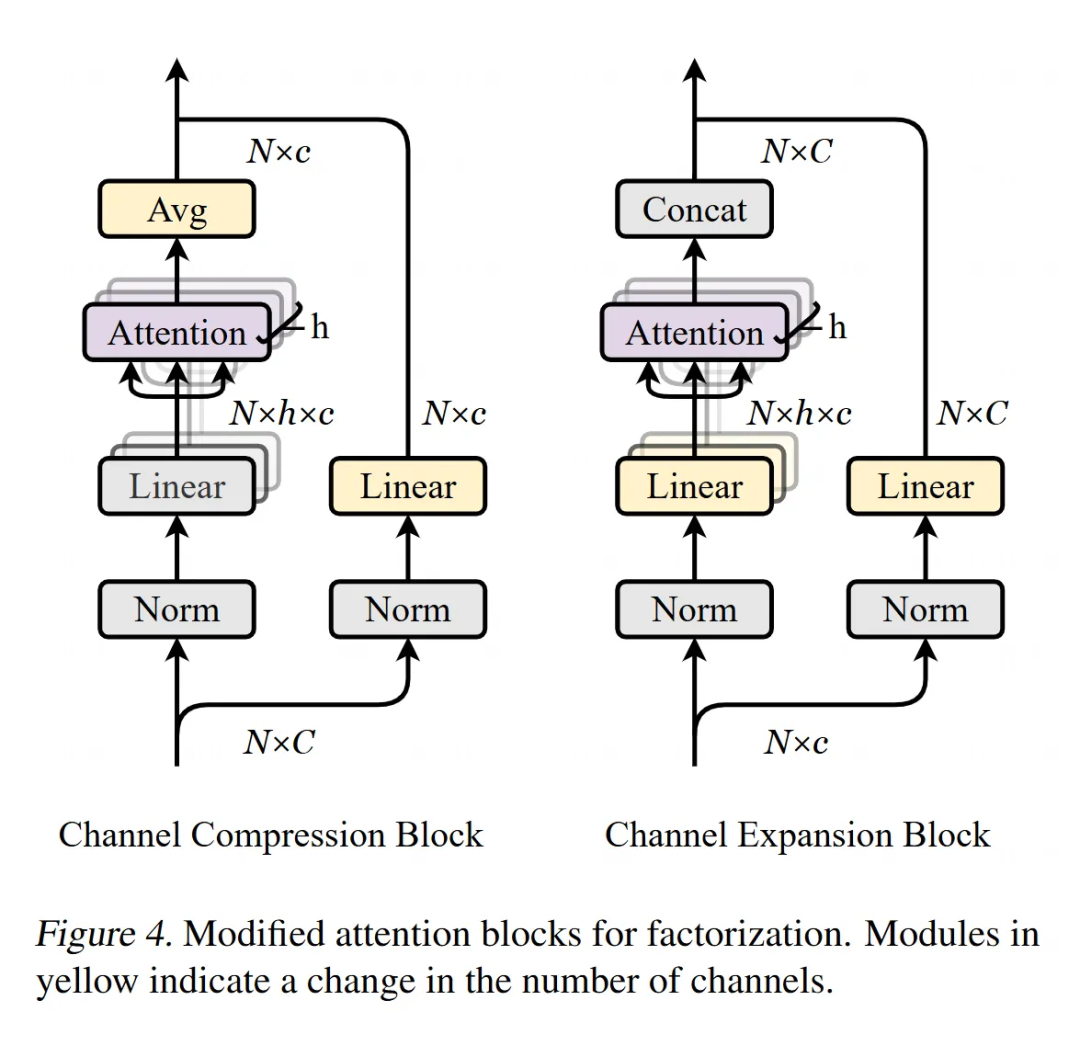
注意力分解(Attention Factorization):
-
问题:前面提到,用简单的线性层做 token 分解(高维压缩到低维)会损失很多信息。
-
改进:研究人员建议使用多头注意力(Multi-Head Attention)模块来替代简单的线性层进行分解(具体结构见图 4,包含一个通道压缩块和一个通道扩展块)。
-
效果:尽管这个改动很简单,但实验发现它能有效地保留原始 token 中的语义信息,提升分解后特征的表达能力。特别地,为了能用于自回归生成任务,这里的注意力模块使用的是因果注意力(causal attention)。
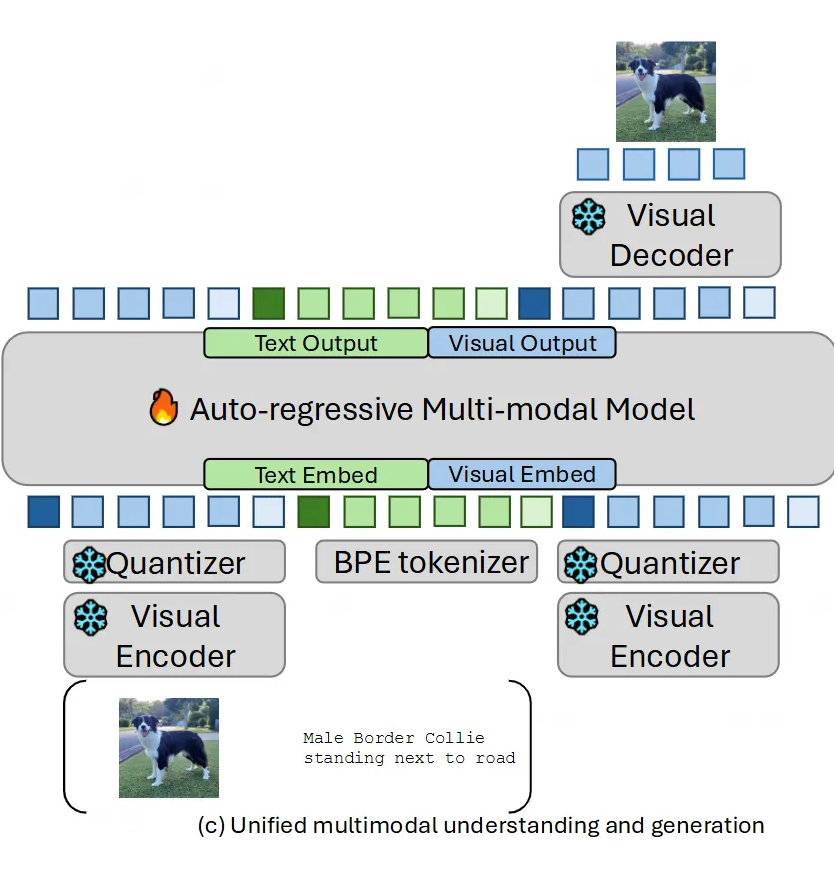
1.4 将 UniTok 融入统一 MLLM
最后,研究人员展示了如何将训练好的 UniTok 应用到一个统一的多模态大语言模型(MLLM)中。
-
他们采用了类似 Liquid 的框架,用一个通用的“预测下一个 token” 的目标来处理视觉和文本序列。
-
关键点:他们没有让 MLLM 从头学习视觉码本,而是重用了 UniTok 训练好的码本 embedding,通过一个 MLP 投影层将其映射到 MLLM 的 token 空间。
-
处理多码本输出:UniTok 会把一张图编码成 个 code( 是子码本数量)。为了简化 MLLM 的输入,他们把每 个连续的 code 合并成一个单一的视觉 token 输入 MLLM。
-
预测多码本输出:在 MLLM 需要预测视觉 token 时,模型会自回归地一次性预测出下一个位置对应的 个 code。这里借鉴了 RQ-Transformer 和 VILA-U 的做法,使用了一个深度 Transformer 头(depth transformer head)来实现。
通过这些方法,UniTok 成功地作为一个强大的、统一的视觉接口,被集成到 MLLM 中,兼顾了生成和理解的需求。
1.5 实验结论
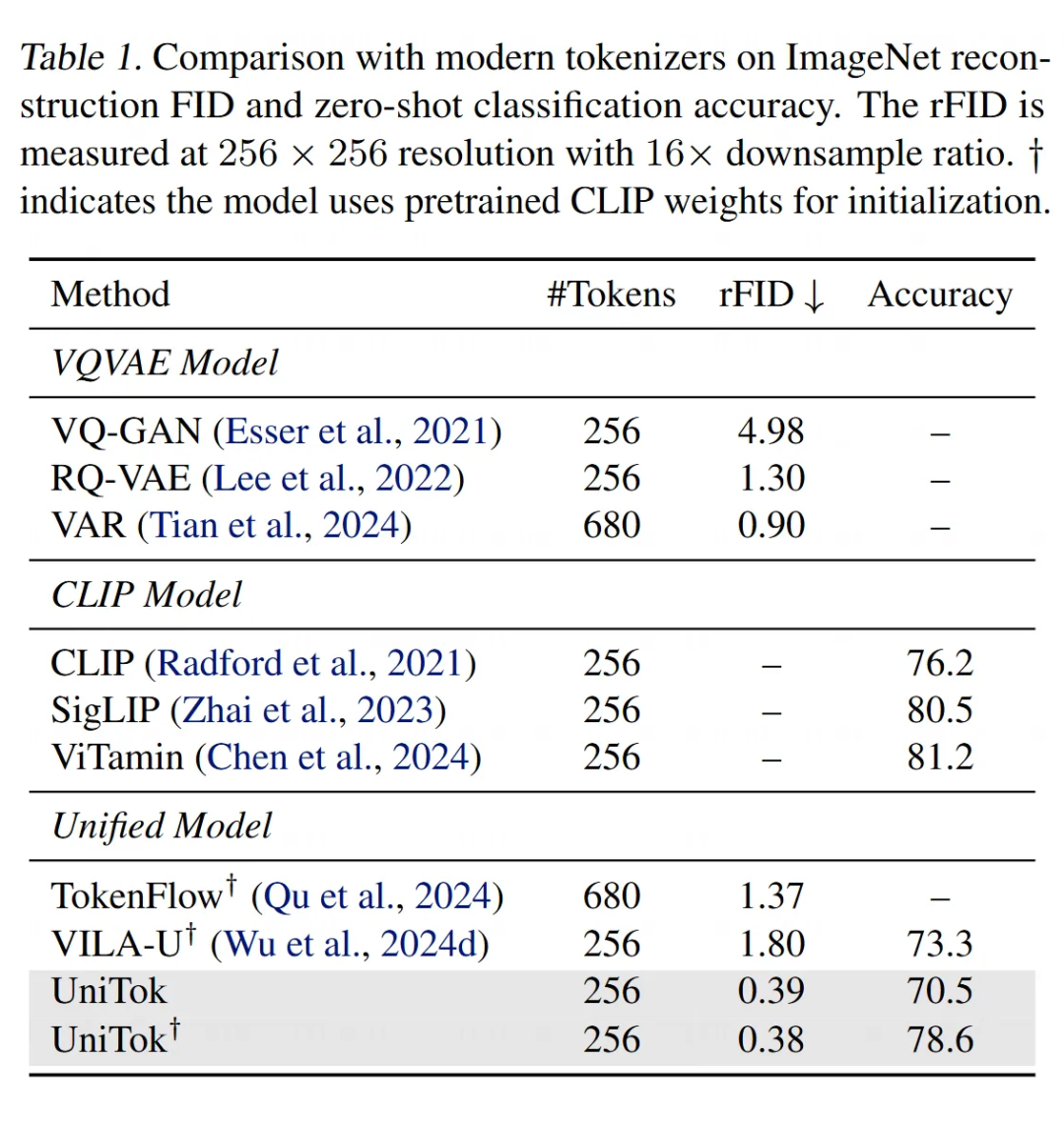
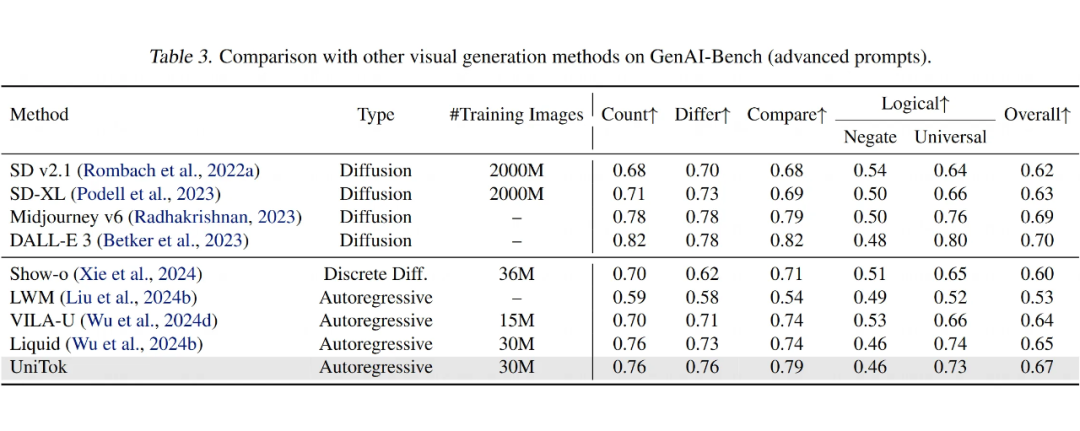
UniTok 相比于已有的 tokenizer 有这明显的优势,在重建质量和 probding 做分类的任务上都有更好的表现。
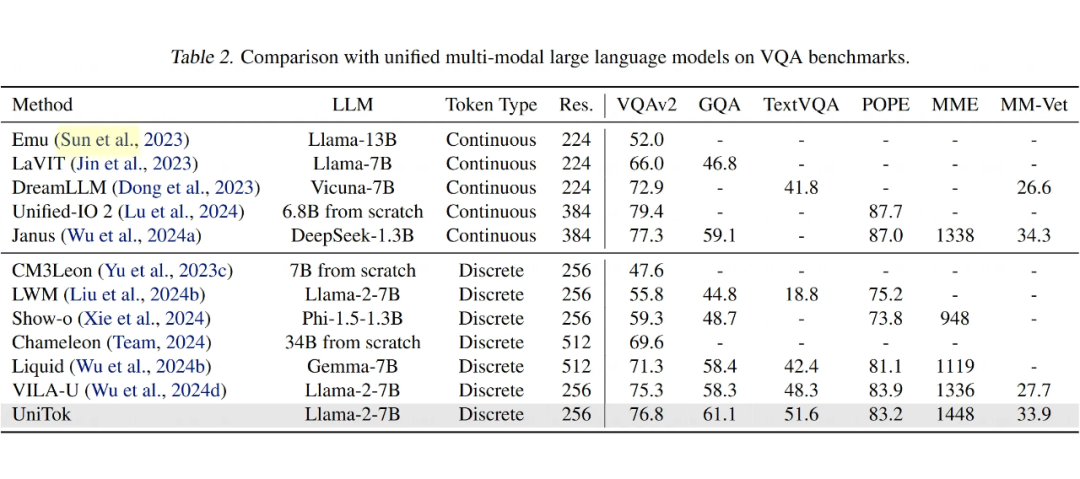
UniTok 在多个视觉问答(VQA)基准测试中,明显优于其他统一模型,如 Chameleon 和 VILA-U,在准确率和其他评分上都取得了更好的成绩。它缩小了与使用连续视觉标记器的模型之间的性能差距。
UniTok 在文本到图像生成任务中表现优异,超越了包括扩散模型在内的其他模型,尤其在像 GenAI-Bench 这样的复杂基准测试上表现出色。即使在较低分辨率下,UniTok 生成的图像也具有高质量、细节丰富的特点,且能够理解抽象概念,如“梵高画风”或“比特币”,并灵活地将这些概念结合生成创意图像。

CMU – D-DiT
论文标题:
Dual Diffusion for Unified Image Generation and Understanding
论文链接:
https://arxiv.org/abs/2501.00289
当前的多模态生成模型领域存在明显的分化:
-
扩散模型(如 Stable Diffusion)在文本到图像生成中表现卓越,但几乎没有处理视觉问答案例的能力,因为传统扩散模型不擅长处理文本任务。
-
自回归模型(如 LLaVA、BLIP-2)则在视觉问答和文本生成中表现出色,但图像生成能力有限。
这篇文章的核心动机是探索能否构建一个统一的端到端扩散模型,兼顾视觉理解和生成任务,打破两种模型的壁垒,实现更灵活的多模态交互。
2.1 主要贡献
第一个全端到端的多模态扩散模型:
-
基于 MM-DiT 架构(多模态扩散变换器),同时支持图像生成、图像描述、视觉问答等任务。
-
在扩散模型中首次实现了完全双向的模态交互(图像 ⇄ 文本),无需依赖自回归模型。
混合扩散策略:
-
图像分支采用连续潜在空间扩散(类似传统扩散模型)。
-
文本分支采用离散掩码标记扩散(通过最大似然估计处理文本生成)。
-
两种策略通过单一损失函数联合训练,实现参数共享。
快速适应能力:
-
模型可继承预训练扩散模型权重(如 Stable Diffusion 3)。
-
初始训练仅需 250 亿文本 Token 即可生成有意义的文本,显著降低计算成本。
任务扩展性:
-
在传统文本生成图像的基础上,新增可控文本填充能力,支持更复杂的视觉问答场景。
-
性能优于现有混合模型(如结合扩散 + 自回归的 Unidiffuser 等)。

2.2 双重扩散 Transformer(D-DiT)方法详解
模型架构
D-DiT 的核心是一个基于 Transformer 的架构,分成两个分支,就像两条腿一样分工合作:
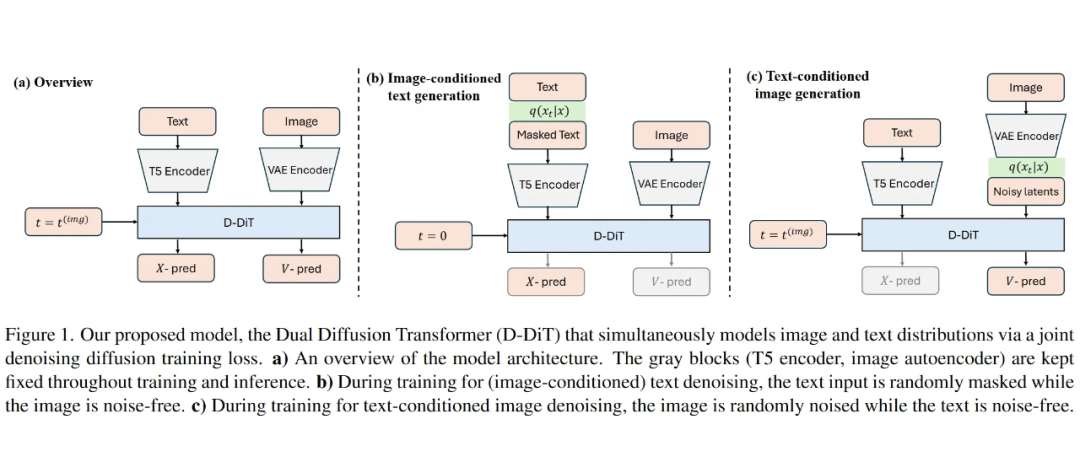
图像分支:负责处理图像的“词汇”(token),输出的是一个速度场,也就是告诉模型如何从带噪声的图像一步步恢复出清晰的图片。这个速度场的预测是基于文本条件的,记作:
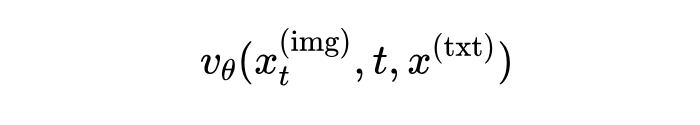
这里 是带噪声的图像, 是时间步, 是条件文本。
文本分支:负责处理文本的“词汇”,输出的是原始文本的预测,也就是从被打乱(比如部分被遮盖)的文本中猜出原本的内容。这个预测是基于图像条件的,记作:
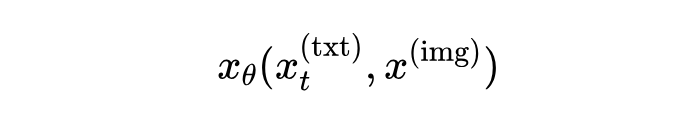
这里 是被打乱的文本, 是条件图像。
这两个分支不是各干各的,而是在每个注意力层里互相交流,通过 Transformer 的注意力机制让图像和文本的信息充分融合。
-
时间步的处理:模型用一个标量时间步嵌入(timestep embedding)来调整每一层的特征图,通过一种叫做 AdaLN(自适应层归一化)的方法。图像生成时,直接输入时间步 ;文本生成时不用显式输入 ,因为文本被遮盖的比例本身就暗示了时间信息。
-
额外的文本编码器:在文本分支上加了一个双向注意力的文本编码器,专门处理文本输入。这个编码器不能用 causal mask,不然会干扰文本扩散的过程。
-
降低计算成本:为了不让高分辨率图像拖慢速度,研究人员把图像从像素空间编码到一个压缩的潜空间(latent space),用的是带判别器损失和 KL 正则化的变分自编码器(VAE)。
2.3 训练方法
D-DiT 的训练目标是同时学会图像和文本的条件分布,用的是一种联合去噪策略,把连续扩散(continuous diffusion)和离散扩散(discrete diffusion)结合起来。
2.3.1 图像训练:流匹配损失
过程:先通过一个正向过程给图像加噪声,公式是:
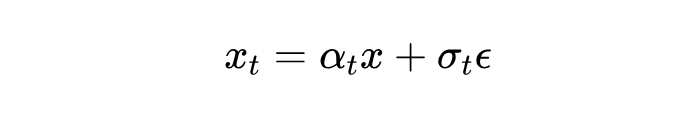
这里 和 是随时间变化的标量, 是噪声。
目标:让模型学会预测速度场 ,也就是从带噪图像 和条件文本 中恢复原始图像 。
损失函数:用的是一种流匹配损失,写成:
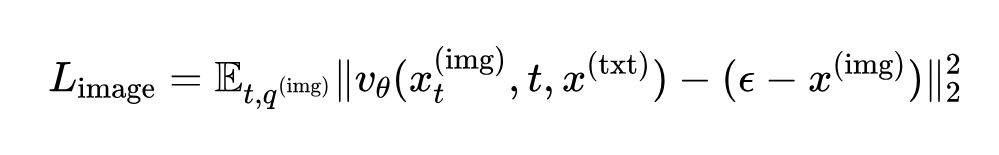
简单说,就是让模型预测的速度场尽量接近真实的速度场,用平方误差衡量。
2.3.2 文本训练:掩码扩散损失
过程:文本的正向过程是逐渐把原始 token 替换成掩码(mask),公式是:
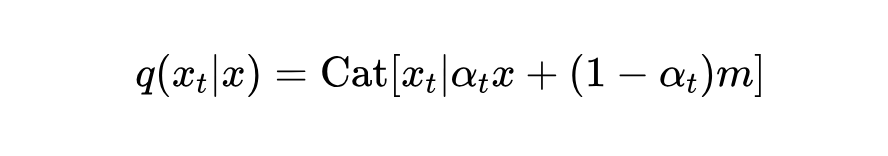
这里 是掩码状态, 控制损坏程度, 表示类别分布。
目标:让模型从被掩码的文本 和条件图像 中预测出原始文本 。
损失函数:用的是一个基于掩码扩散的损失,写成:
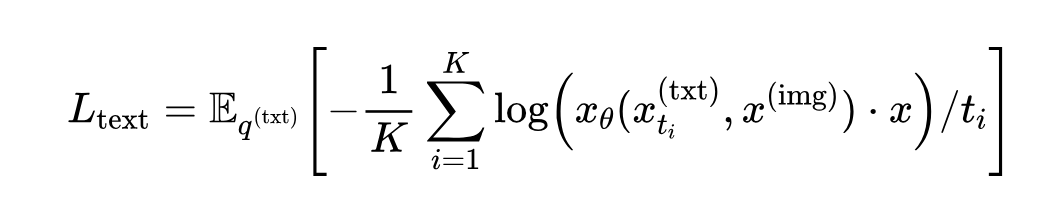
这里 是时间步采样点数, 是具体时间步,损失衡量预测文本和真实文本的对数相似度,再除以时间步做标准化。
采样细节:时间步 用对偶采样(antithetic sampling),在 区间均匀分成 个点( 是个小数,避免数值问题);图像的 则从对数正态分布中采样。
2.3.3 联合损失
训练时,条件样本(比如给图像去噪时的文本,或给文本去噪时的图像)保持干净,不加噪声。
总损失是两个单模态损失的加权和:

是个超参数,调节文本损失的比重。
2.4 推理方法:三种玩法
D-DiT 提供了三种推理方式,灵活应对不同的视觉-语言任务:
1. 文本到图像生成:
目标:从文本条件 生成图像 。
方法:用分类器自由引导(CFG)技术,通过调整速度场预测来采样:

这里 是引导强度的超参数, 是空文本的嵌入表示。
直白点说:模型根据文本提示,结合一点“无条件”预测,逐步把噪声变成清晰图片。
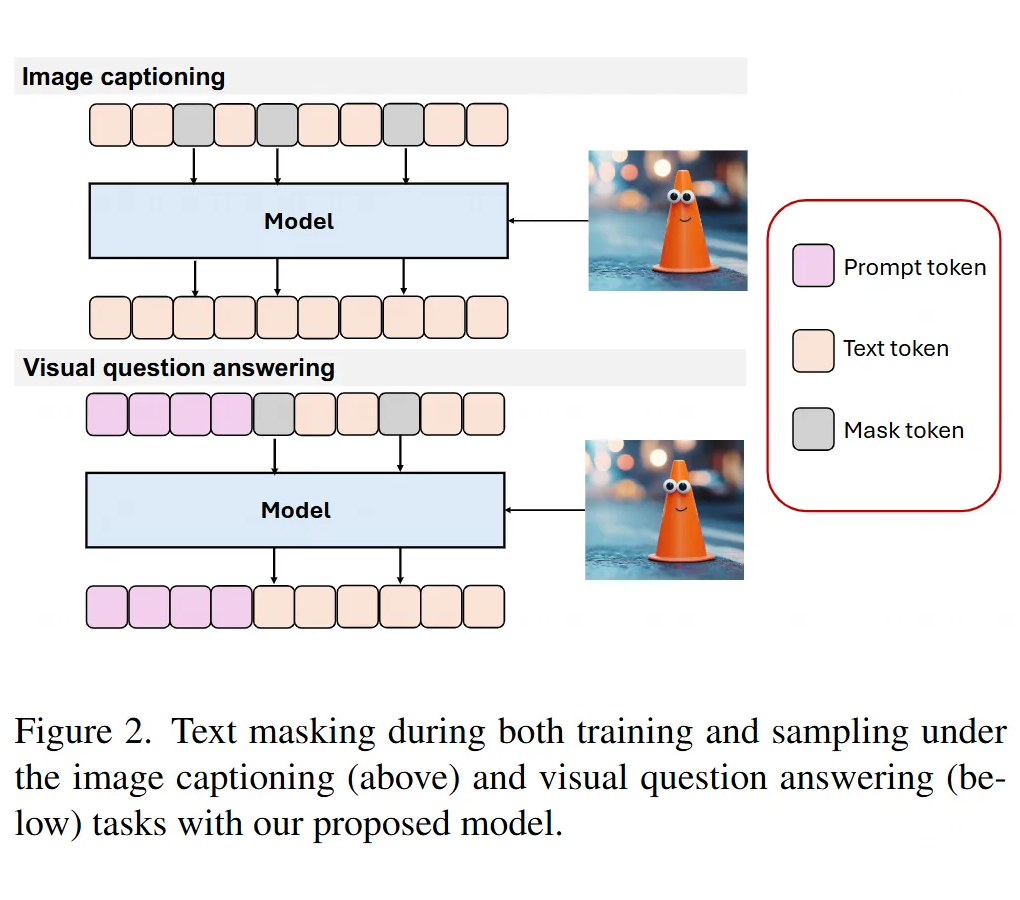
图像到文本生成:
目标:从图像条件 生成文本 。
方法:用祖先采样(ancestral sampling),从后验分布 中逐步抽样,预测 。
直白点说:从被掩码的文本开始,参考图像信息,一步步填回完整文本。
图像到文本填充:
目标:在有图像 和部分文本(比如问题 )的情况下,生成答案 。
方法:把问题初始化为带掩码的状态,利用文本扩散模型的填充能力,从条件分布 中采样。问题部分的 token 在采样时保持固定。
直白点说:比如视觉问答任务,给一张图和问题“天上有彩虹吗?”,模型填出答案“是的,有彩虹”。
训练策略
阶段一基础训练:该阶段的目标是使 D-DiT 适应文本生成任务。模型在约 30M 图像的 Datacomp-1b 数据集上训练,使用了联合扩散损失,并进行了 60K 次迭代。文本最大长度被截断为 64,图像分辨率设置为 256,批大小为 512。
阶段二高质量数据强化:此阶段使用了 ShareGPT4V 和 OpenImages 数据集,这些数据集提供了丰富的文本描述。模型在这些数据集上训练了 200K 次迭代,文本长度设置为 256,图像分辨率为 256,批大小为 512。此外,还对更高质量的图像数据集(包括 LAION-1024 和 Midjourney 图像)进行了可选的高分辨率模型微调。
阶段三视觉指令微调:此阶段,模型使用了 LLaVA-Pretrain558K、LLaVA-v1.5-mix-665K 以及 TextVQA 和 VizWiz 等视觉指令微调数据集。训练目标是促使模型生成联合文本-图像条件文本,并训练了 50K 次迭代,模型被训练以根据任务特定的指令提示(如“用一个单词或短语回答问题”或“简洁地描述图像”)来回答问题。
2.5 实验结果
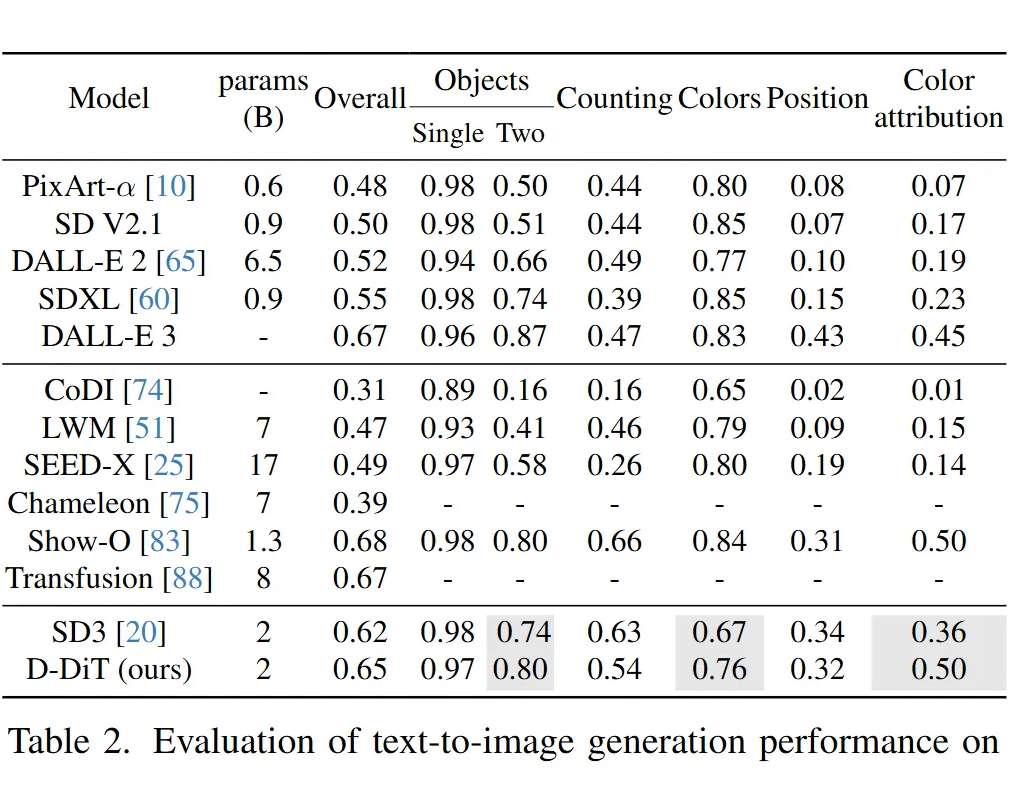
在 GenEval 专业作图测试中,和原版 Stable Diffusion3 保持相同水平,色彩准确率还提升 8%(可能因为视觉理解训练帮助模型更好把握描述细节)。
生成梵高风格图像时,新模型笔触更细腻(实验中的美学评分从 4.2 提升到 4.7)。
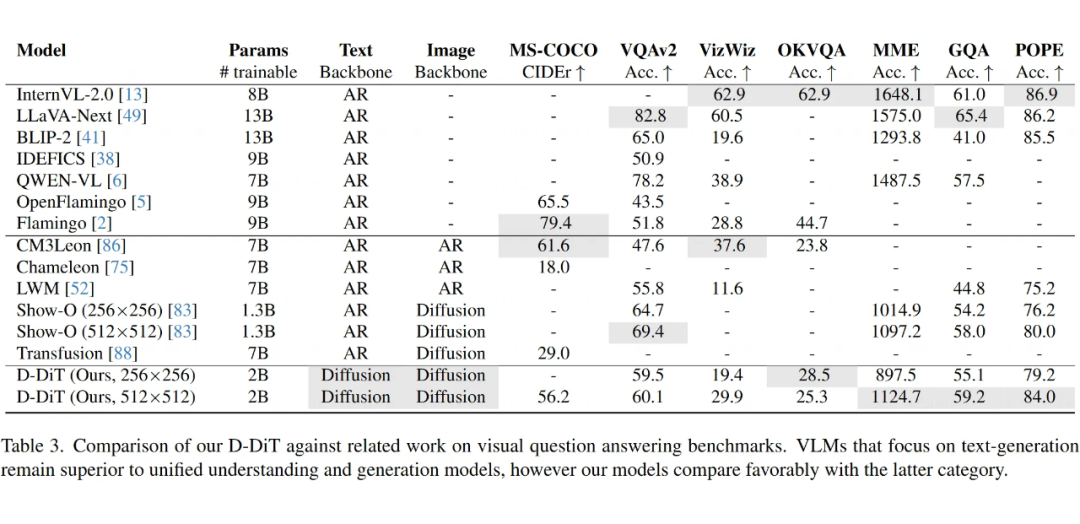
在经典视觉问答 VQAv2 中,512 分辨率版模型准确率达 60.1%,超过了部分自回归模型(如 BLIP-2 的 41%)。
2B 参数的模型在生成质量和计算开销之间取得完美平衡。当参数量翻倍时,答题准确率仅提升 1.7%,但耗能却增加 3 倍。
图像分辨率提高会明显提升视觉问答能力(从 256 到 512 分辨率时,MME 评分提升 25%),但文本生成质量几乎不变。

Show-lab – UniMoD
论文标题:
UniMoD: Efficient Unified Multimodal Transformers with Mixture-of-Depths
论文链接:
https://arxiv.org/abs/2502.06474
代码链接:
https://github.com/showlab/UniMoD
训练全能模型开销很大。主要原因有两个:一是因为模型处理的数据里面有很多是冗余的,其实没那么重要;二是因为“注意力机制”的部分,计算量特别大。
之前在研究纯文本大模型的时候,“深度混合(Mixture of Depths, MoD)”的方法,通过扔掉一些不重要的 token 来提高计算效率,效果还不错。这个方法就像给每个 token 打分,然后只让得分高的 token 进入下一层计算。
然而,研究人员发现,直接把这个 MoD 方法搬到全能型多模态模型上效果不太行。为什么呢?
因为不同的任务(比如生成任务和理解任务)对 token 的依赖程度不一样,冗余程度也不同。用同一个“裁判”(router)去决定所有任务里哪些 token 该被扔掉,就显得有点一刀切了,顾此失彼,可能会把生成任务需要的重要 token 给扔了,或者没把理解任务里的冗余 token 清理干净。
所以,怎么给这种全能模型“减负”,让训练更高效,同时又不牺牲性能,就成了一个亟待解决的问题。特别是,需要一种更聪明的、能区分不同任务需求的 token “瘦身”方法。
3.1 主要贡献
这篇研究为了解决上面提到的问题,做了一些挺有意思的探索和贡献:
深入分析了全能模型:研究人员仔细研究了现有的全能型多模态大模型(比如 Show-o 和 Emu3),从几个角度去扒细节:
-
注意力权重:看看不同的任务(生成 vs 理解)和不同的数据类型(图像 vs 文本)会不会影响模型内部的注意力分配模式。
-
层的重要性和 Token 冗余度:通过实验评估模型里不同层的重要性,以及不同层、不同任务下 token 的冗余程度(用了一个叫 ARank 的指标,值越高表示冗余越少)。
-
任务间的相互影响:研究了一下,如果模型只做一个任务,会不会影响另一个任务的表现;还设计了一个“竞争”场景,让不同任务的 token 抢着被选中,看看谁更重要。
得出了关键发现:通过上面的分析,得到了两个重要结论:
-
模型里的不同层,重要性确实不一样,token 的冗余程度也随着层数变化。
-
最关键的是,不同的任务(比如生成和理解),因为实现方式不同(比如一个是扩散模型方法,一个是自回归方法),导致它们的 token 冗余程度差异很大。就算是同一种类型的数据(比如图片 token),在生成任务里和在理解任务里,其重要性和冗余度也可能完全不同。
提出了 UniMoD 方法:基于这些发现,研究人员提出了一个叫 UniMoD(Unified Mixture-of-Depths)的新方法。这个方法的核心思想是任务感知(task-aware),也就是区别对待不同任务:
-
它不再用一个统一的裁判来决定丢弃哪些 token,而是给每个任务(比如生成任务、理解任务)配一个专属的裁判(router)。
-
这样,每个裁判就可以根据自己负责的任务的特点,来决定哪些 token 是冗余的、可以被“跳过”计算,从而更精准地进行 token 剪枝。
验证了效果:他们在 Show-o 和 Emu3 这两个代表性的全能模型上应用了UniMoD方法。结果显示:
-
显著降低了计算量:Show-o 的训练计算量(FLOPs)减少了大约 15%,Emu3 更是减少了约 40%。
-
性能不降反升:在降低计算量的同时,模型在一些评测标准上的表现甚至还有所提升。
3.2 对统一多模态 Transformer 的实证分析
这部分研究深入探讨了现有的“全能型”多模态大模型(Unified Multimodal Transformers)存在的一些问题,为后面提出 UniMoD 方法打下了基础。研究人员主要从几个方面入手,进行了细致的分析和实验。
3.2.1 预备知识:全能模型与 MoD
全能型多模态 Transformer:这种模型旨在用一套参数同时处理理解任务(比如看图回答问题)和生成任务(比如文字生成图片)。主要有两种流派:
一种是所有任务都用自回归(AR, Autoregressive)方式处理,典型代表是 Emu3。
另一种是生成任务用扩散模型(Diffusion)或流匹配(Flow Matching),理解任务用自回归方式,典型代表是 Show-o。
Show-o 的训练目标有两个:
下一个 Token 预测(NTP):用于生成任务。给定图片 token 和文本 token ,模型的目标是最大化预测下一个文本 token 的概率:
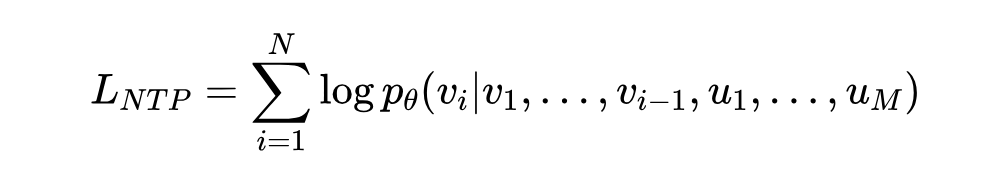
掩码 Token 预测(MTP):用于理解任务。给定一个序列,其中某些图片 token 被遮盖了,模型的目标是最大化预测这些被遮盖 token 的概率:
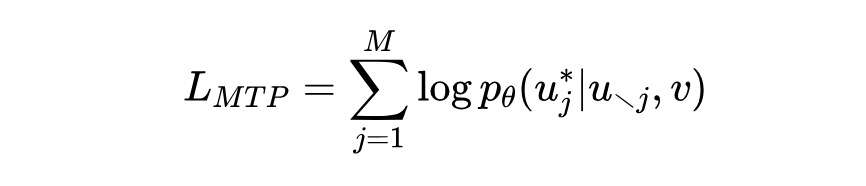
这里的 指的是除了第 j 个以外的所有图片 token。
Emu3 的训练目标则是标准的自回归,对图片和文本混合序列中的每一个 token 进行预测:
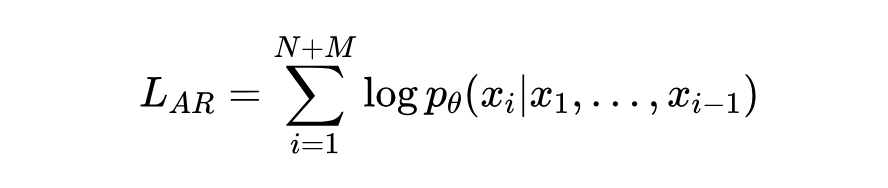
这里的 是混合序列中的第 i 个 token。
深度混合(MoD):这是一种提升 Transformer 训练效率的技术。简单来说,就是给模型每一层加一个“路由器”(Router)。这个路由器会判断哪些输入的 token 不太重要,然后让这些不重要的 token“跳过”当前层的计算,直接去下一层。这样就能减少计算量。公式表示大概是这样:
如果一个 token 通过路由器 计算出的得分大于等于阈值 ,那么它就正常经过当前层 的处理:
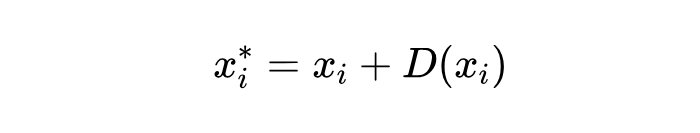
如果得分小于阈值 ,那么它就跳过:
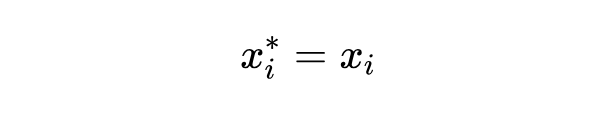
这个方法和 MoE(Mixture of Experts)不一样,MoE 是让不同的 token 被不同的“专家”(模型的一部分)处理,主要是为了扩大模型容量;而 MoD 是直接减少参与计算的 token 数量,旨在降低计算成本。
3.2.2 分析一:注意力权重模式
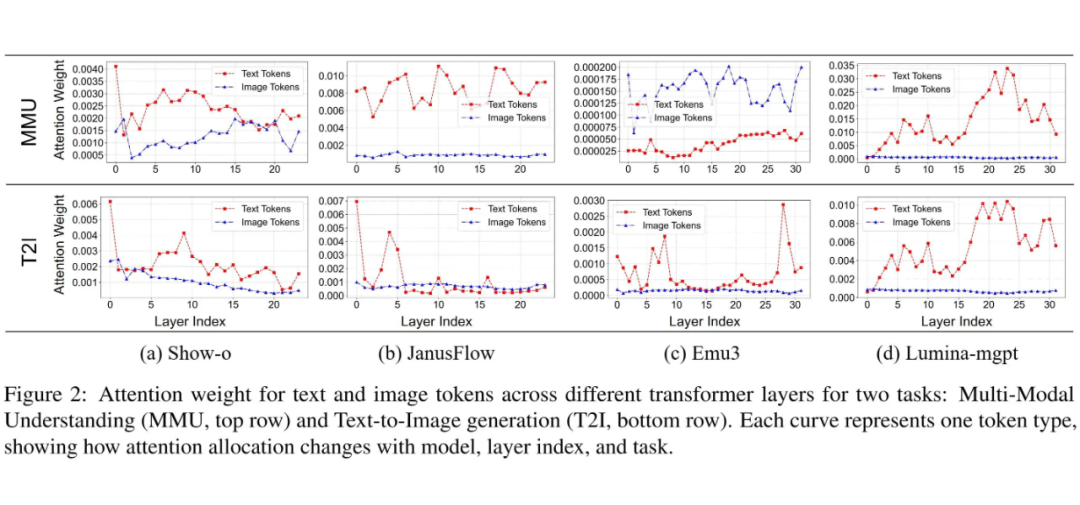
研究人员观察了四种不同的全能模型(Show-o, JanusFlow, Emu3, Lumina-mgpt)内部,图片 token 和文本 token 在不同层获得的注意力权重有啥规律。他们主要对比了两种任务:多模态理解(MMU)和文本到图片生成(T2I)。
-
发现 1:不同任务下,图片和文本 token 的注意力权重模式差异很大(尤其是在 Show-o, JanusFlow, Emu3 中)。但在 Lumina-mgpt 模型里,两种任务下的模式又很相似。
-
原因分析:研究人员认为,这主要是因为不同模型、不同任务采用的建模方法(比如 Show-o 的生成用扩散,理解用自回归)和序列组织方式(比如图片和文本 token 如何排列组合输入模型)不同。Lumina-mgpt 可能因为用了交错数据训练,并且建模和序列设计上更统一,所以任务间差异较小。
-
启发:这个发现说明,图片和文本 token 的重要性是随着任务变化的。因此,后面做 token 剪枝(pruning)的时候,不能只看一种模态,而是要综合考虑图片和文本 token 的冗余性。
3.2.3 分析二:层的重要性和 Token 冗余度
这部分研究了模型里不同层到底哪个更重要,以及不同层、不同任务下的 token 有多“冗余”(即信息量低,可能可以被丢弃)。

层的重要性实验(Show-o):他们做了一个简单的实验:在推理(模型跑预测)的时候,依次跳过模型中的某些层(比如第 1 层、第 3 层……),然后看模型在 GQA 这个理解任务 benchmark 上的性能下降多少。
发现 2:结果(见表 1)显示,跳过靠前的层比跳过靠后的层,对模型性能的影响更大。这说明模型的前几层对于最终结果更关键。

Token 冗余度量化:研究人员借鉴了之前工作中的 ARank(Attention Map Rank)指标来衡量每一层中 token 的冗余程度。ARank 衡量的是注意力矩阵的秩(rank)。简单来说,ARank 值越高,表示这一层的 token 冗余度越低(信息量越大)。计算公式大致如下:
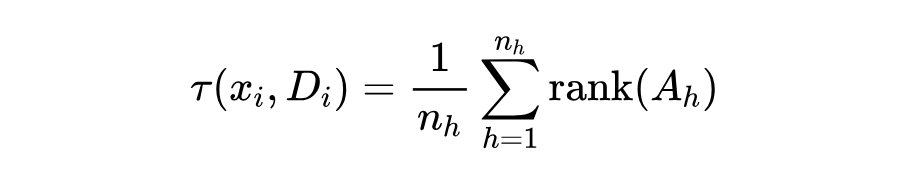
其中 是第 h 个注意力头的注意力图, 是注意力头的数量, 和 是对应的查询(Query)和键(Key)的投影矩阵。
ARank 分析(四个模型):他们计算了四个模型在不同层、不同任务下的 ARank 值。
发现 3:对于 Show-o 和 JanusFlow 模型,生成任务(T2I)和理解任务(MMU)的 token 冗余度差异显著。
比如在 Show-o 里,理解任务(MMU)的 ARank 值普遍比生成任务(T2I)低很多,说明理解任务中有更多的冗余 token。而在 Emu3 和 Lumina-mgpt 中,两个任务的冗余度则比较接近。研究者认为这还是和模型采用的建模方法有关(扩散 vs 自回归 vs 纯自回归)。
发现 4:对于同一个任务,不同层的 token 冗余度也差异巨大。通常,靠前的层 ARank 值较高(冗余少),靠后的层 ARank 值较低(冗余多)。这种现象在所有被分析的模型中都存在。研究者猜测这可能和模型使用的基础语言模型有关。
启发:这部分分析说明,进行 token 剪枝时,应该重点关注那些冗余度高的层(ARank 值低的层),并且需要根据不同的任务来确定剪枝的比例和策略。
3.2.4 分析三:任务间的相互作用
这部分探讨了同时训练多个任务会不会互相影响,以及不同任务的 token 在竞争中谁更重要。
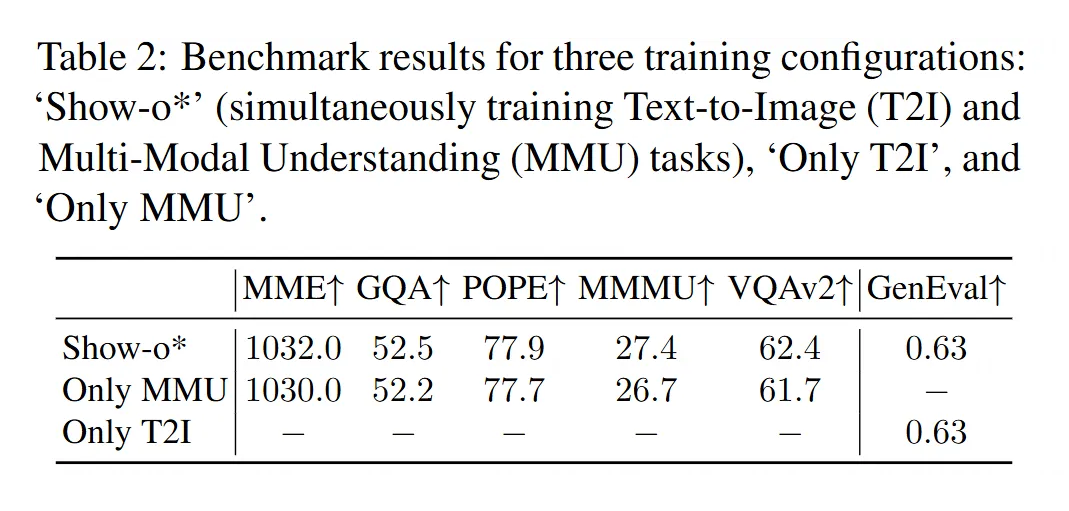
任务干扰实验(Show-o):研究人员比较了三种训练设置:只训练生成任务、只训练理解任务、同时训练两个任务。然后评估了模型在各自任务上的性能。
发现:结果(见表 2)显示,三种设置下,各自任务的性能几乎没差。这说明,至少在 Show-o 这个模型里,同时训练两个任务并不会显著地互相提升或者互相拖累。研究者推测,这可能还是因为 Show-o 对两个任务用了不同的处理流程(扩散 vs 自回归)。
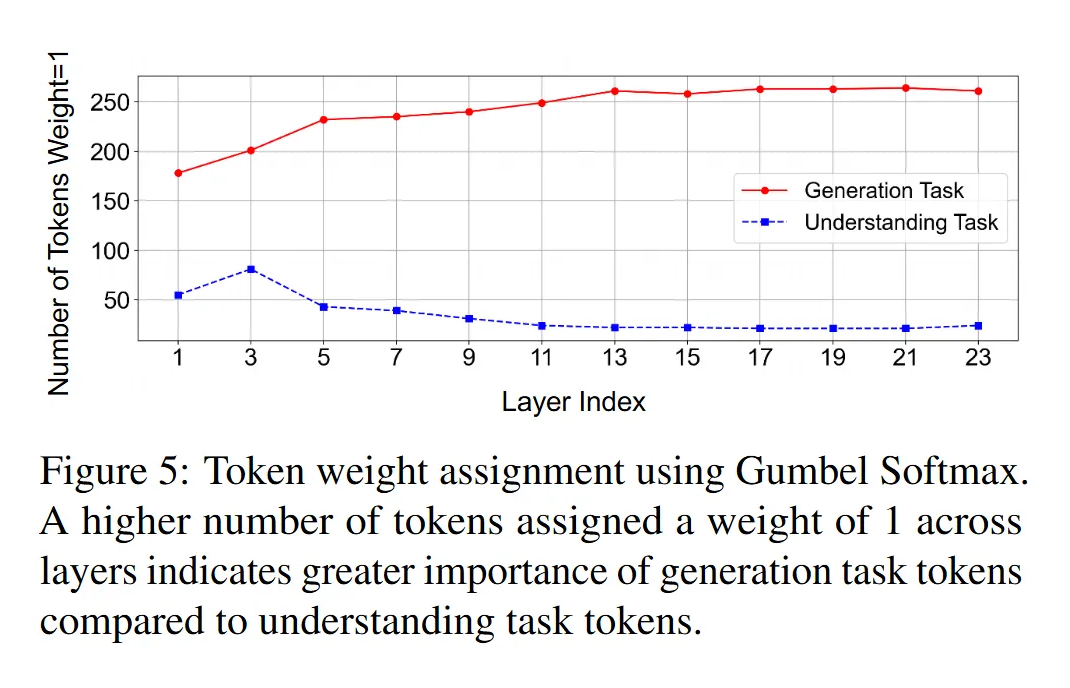
Token 竞争实验(Show-o):他们设计了一个场景,让生成任务(T2I)的 token 和理解任务(MMU)的 token 竞争被模型选中(不被剪枝)。他们使用了一种叫做 Gumbel-Softmax 的方法给每个 token 分配一个接近 0 或 1 的权重,1 表示保留,0 表示剪枝,并限制每层只能保留一半的 token。
发现 5:结果(见原文图 5)显示,生成任务(T2I)的 token 绝大多数都被赋予了权重 1(被保留),而理解任务(MMU)的 token 则有相当一部分被赋予了权重 0(被剪枝)。这说明,在当前的竞争机制下,模型认为生成任务的 token 对于优化目标(比如降低 loss)更重要。
启发:这个发现暗示,如果用统一的标准去剪枝所有任务的 token,可能会导致某些任务(比如这里的理解任务)的 token 被过度剪枝,从而影响其性能。因此,为不同的任务分别设置剪枝策略可能是更合理的方式。
这些细致的分析和有趣的发现,共同指向了同一个结论:简单地将 MoD 应用于统一多模态模型是行不通的,需要一种能够感知任务差异、层级差异的、更精细化的 token 剪枝方法。这直接催生了他们提出的 UniMoD 方法。
3.3 方法详解:UniMoD 是怎么做的?
前面分析了一大堆,发现了全能模型里的 token 冗余跟任务类型、模型层数都有关系,而且不同任务的 token 重要性也不一样。
基于这些观察,研究人员就提出了一个更聪明的 token 剪枝方法,叫做 UniMoD(Unified Mixture-of-Depths)。这个方法的核心就是区别对待不同的任务。
下面是具体的做法,也就是 UniMoD 的技术细节:
3.3.1 任务感知的 MoD 层(Task-Aware MoD Layer)
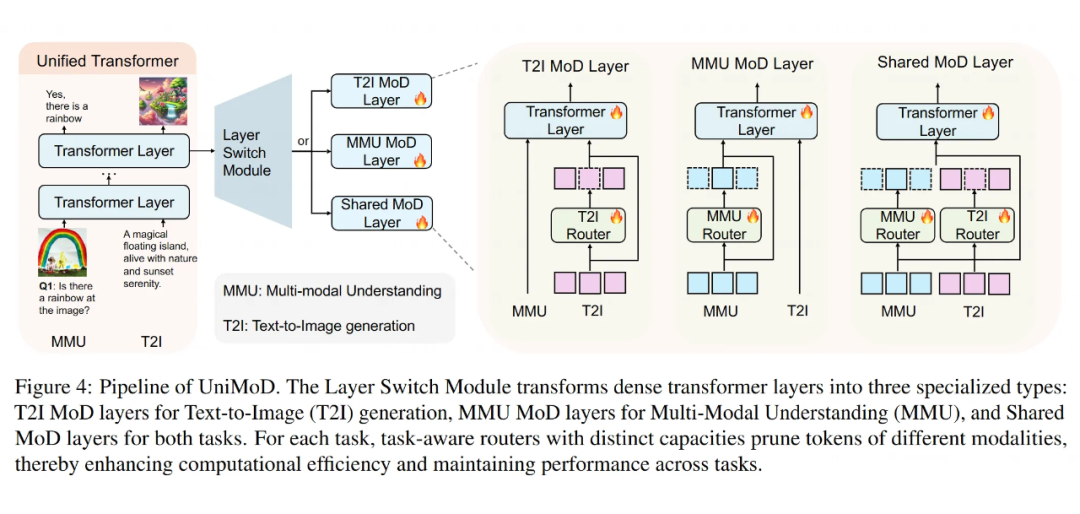
这个是 UniMoD 的核心改造。研究人员没有让所有的 Transformer 层都一视同仁地处理所有任务的 token,而是把一些普通的 Transformer 层变成了三种特殊的“深度混合(MoD)层”:
T2I MoD 层(Text-to-Image MoD block):这种层是专门为“文本生成图片”(T2I)任务设计的。当处理 T2I 任务的数据时,它会根据规则来决定哪些 T2I 任务的 token 可以被“跳过”(剪枝)。
但是,如果这时候进来的是“多模态理解”(MMU)任务的数据,这个层就老老实实处理所有的 MMU token,一个也不跳过。
MMU MoD 层(Multi-Modal Understanding MoD block):这个跟上面相反,是专门为“多模态理解”(MMU)任务设计的。它只会在处理 MMU 任务数据时进行 token 剪枝,对 T2I 任务的数据则全部处理。
共享 MoD 层(Shared MoD block):这种层就比较“公平”了,它会同时对 T2I 和 MMU 两种任务的 token 进行剪枝。
关键在于,每种 MoD 层(或者说每个任务在 MoD 层里)都有自己专属的“路由器”(Router)。这个路由器负责给当前任务的 token 打分,决定谁留下谁跳过。
而且,给 T2I 任务设计的路由器和给 MMU 任务设计的路由器,它们的“容量”(capacity,可以理解为剪枝的严格程度或者说保留 token 的比例)是可以不一样的。这样就能根据不同任务的实际需求来灵活地调整剪枝策略了。这些路由器会同时考虑图片和文本 token,进行跨模态的剪枝。
不同的任务流经模型时,在特定的 MoD 层会遇到自己的专属路由器,决定哪些 token 可以“抄近路”。
3.3.2 任务相关的 MoD 公式
为了实现这种任务相关的剪枝,研究人员稍微修改了一下标准 MoD 的公式:
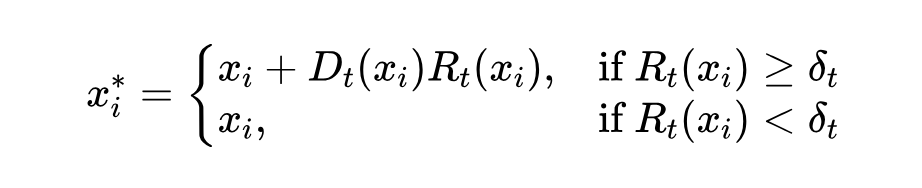
解释一下这个公式里的符号:
:表示原始的、进入这一层的第 个 token。
:表示经过这层(可能被剪枝)处理后的 token。
:代表当前处理的是哪个任务,比如 =T2I 或者 =MMU。
:指的是专门为任务 设计的 Transformer 层处理函数(就是正常的 Attention 和 FFN 计算)。
:这是任务 专属的路由器函数,它会给输入的 token 算出一个权重(重要性得分)。
:这是任务 专属的剪枝阈值。只有当一个 token 的得分 大于等于这个阈值 时,它才会被认为是重要的,需要经过 的完整计算(然后加上残差连接 )。
如果得分 小于阈值 ,那么这个 token 就被认为是冗余的,直接“跳过” 的计算,原封不动地输出 。
通过这种方式,UniMoD 就能针对不同任务、不同层级应用不同的剪枝策略和阈值,更加精细化地管理计算资源,提升训练效率。
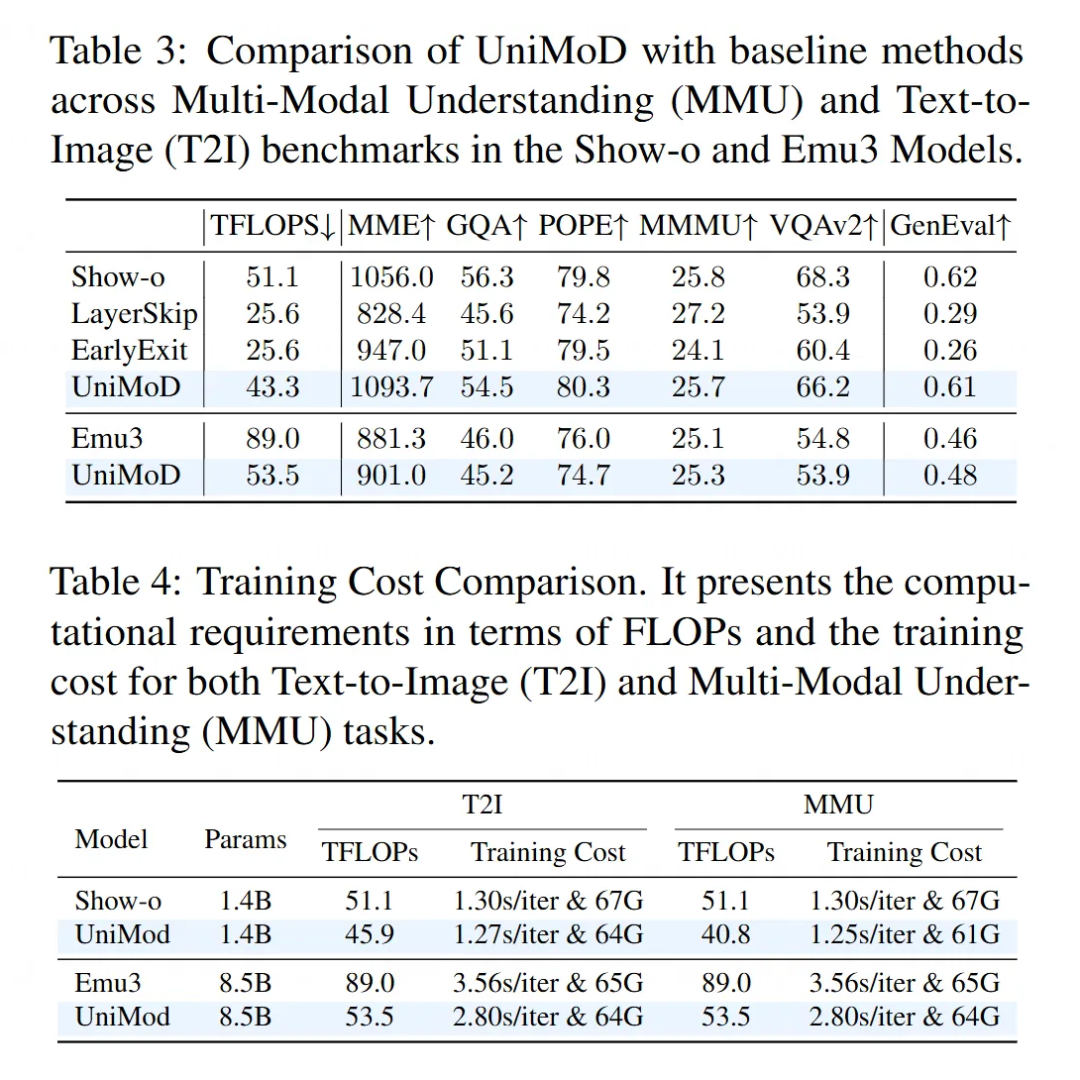
他们在 Show-o 和 Emu3 这两个代表性的全能模型上应用了 UniMoD 方法。结果显示:
-
显著降低了计算量:Show-o 的训练计算量(FLOPs)减少了大约 15%,Emu3 更是减少了约 40%。
-
性能不降反升:在降低计算量的同时,模型在一些评测标准上的表现甚至还有所提升。

英伟达 – QLIP
论文标题:
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
论文链接:
https://arxiv.org/abs/2502.05178
代码链接:
https://github.com/NVlabs/QLIP/tree/main
在多模态理解和生成任务中,现有的视觉编码器往往面临着两个问题:一方面是图像的重建质量不足,另一方面是多模态的理解效果不理想。传统的自回归序列模型在视觉与语言的结合上面临瓶颈,尤其是视觉编码的 token 化方法上存在较大的挑战。
常见的做法是通过自编码器来学习图像的压缩表示,但这种方式通常不能有效捕捉语义信息,导致视觉和语言的处理分开,训练效率低下,且需要大量计算资源。因此,如何在保证图像重建质量的同时,提升视觉-语言理解能力,成为了当前的研究重点。
4.1 主要贡献
本文提出了一种新的视觉 token 化方法——量化语言-图像预训练(QLIP),该方法将视觉-语言对齐引入到视觉token化阶段,从而在图像重建和多模态理解之间取得了很好的平衡。QLIP 使用基于二进制球形量化(BSQ)的自编码器,并结合对比学习和图像重建目标进行训练。
本文的创新之处在于:
1. 提出了在视觉 token 化阶段同时进行视觉-语言对齐的做法,解决了图像重建与语义理解之间的冲突。
2. 提出了动态平衡两种损失的策略,使得对比目标和回归目标可以协调优化。
3. 提出了两阶段训练方法,解决了对比学习和图像重建所需的不同批量大小问题,从而使得 QLIP 能够在大规模的视觉-语言预训练任务中表现出色。
4. QLIP 在多个多模态理解和生成任务上取得了优异的表现,尤其是在 LLaVA 和 LlamaGen 等任务中的应用上,能够替代传统的视觉编码器,并且在某些任务中表现得更好。
4.2 核心思路
这篇文章的目标是搞一个与文本对齐的视觉分词器(visual tokenizer)。简单来说,就是想让图像块也能像文字一样被表示成一个个“词”(token),而且这些图像“词”的表示能跟文本“词”的表示在同一个空间里,这样模型就能更好地理解图文关系。
大概思路是:
基础是图像自编码器:用一个叫 BSQ(Binary Spherical Quantization)的量化方法来压缩图像信息,得到离散的视觉 token。这种方法比传统的 VQ 更能适应大词汇表。
加入文本对齐:在训练自编码器的同时,引入像 CLIP 那样的对比学习方法,利用图像附带的文本描述,来让视觉 token 的表示和文本 token 的表示相互靠近。
最后,他们把这些学好的、与文本对齐的视觉 token 和普通的文本 token 拼在一起,喂给一个大语言模型(基于 Llama 3),训练出一个能同时处理和生成文本、图像的统一多模态模型(UM3)。
4.2.1 量化方法:BSQ(Binary Spherical Quantization)
文章没有用常见的 VQ,而是选择了一个叫 BSQ 的方法,因为它在大词汇量(就是视觉 token 种类很多)的情况下表现更好。
怎么工作:BSQ 不是直接学一个巨大的码本(codebook),而是用一个“隐式”的码本。它先把图像编码器输出的连续特征 (latent embedding)线性投影到一个 维的单位超球面,得到向量 。
然后对 的每一维进行二值化(大于 0 就是 ,小于等于 0 就是 ),得到量化后的向量 。这个 就对应着隐式码本里的一个码字(一个超立方体的顶点)。最后再把 投影回原始的特征空间得到 。
获取 token 索引:在推理时,根据 每个维度是正还是负,就能直接计算出对应的 token 索引 :
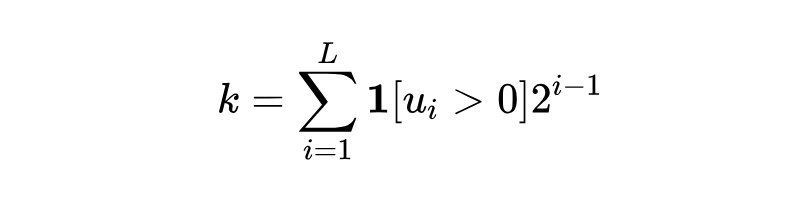
这里 是指示函数,条件成立时为 1,否则为 0。
BSQ 损失函数:为了让模型好好学习怎么量化,并且让不同的码字都被用到,BSQ 用了一个基于熵的损失函数:
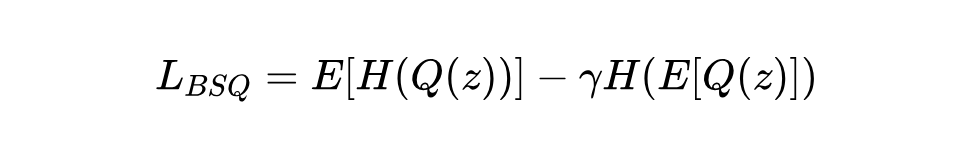
这里 表示熵, 是量化操作。这个损失鼓励单个样本量化结果的熵高(不确定性大,即用软量化时概率分布平坦),同时鼓励整个数据集量化结果的平均熵低(整体上某些 token 更常用)。
4.2.2 语言-图像对齐
这部分和 CLIP 类似,目标是让匹配的图像和文本在表示空间里靠得更近,不匹配的则相互远离。
特征提取:用一个视觉编码器 提取图像 的特征,用一个文本编码器 提取文本 的特征。在 QLIP 里,视觉特征 是通过一个专门的分类 token 经过编码器 得到 ,再通过一个线性投影头 得到并归一化的:
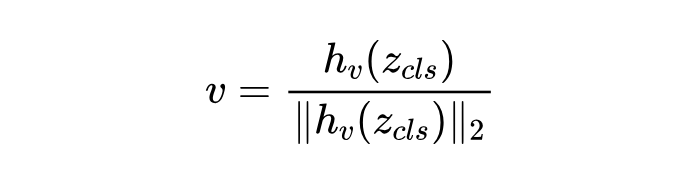
文本特征 也是归一化的:
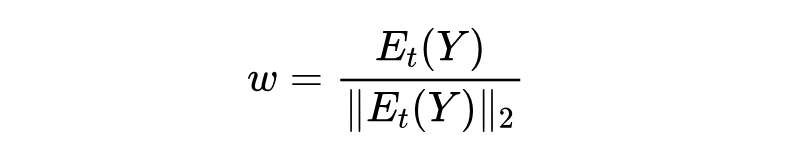
对比损失:使用 InfoNCE 类型的损失函数:
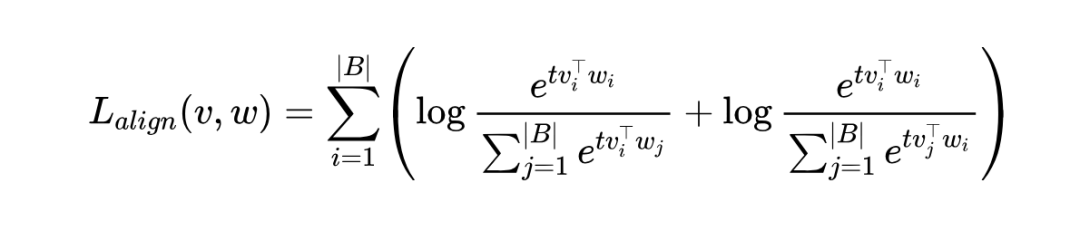
这里的 是一个批次 (batch) 的样本, 和 是样本索引, 是一个可学习的温度参数。这个公式的意思是,对于第 对图文 ,要让 和 的相似度(用点积表示)尽可能高,同时让 和其他文本 () 的相似度尽可能低(第一项),也要让 和其他图像 () 的相似度尽可能低(第二项)。
4.2.3 QLIP 训练中的挑战与技巧
直接把自编码器和对比学习合在一起训练会遇到问题,主要是计算资源(显存)和不同任务目标(重建图像 vs. 语义对齐)之间的平衡。文章提出了几个解决方法:
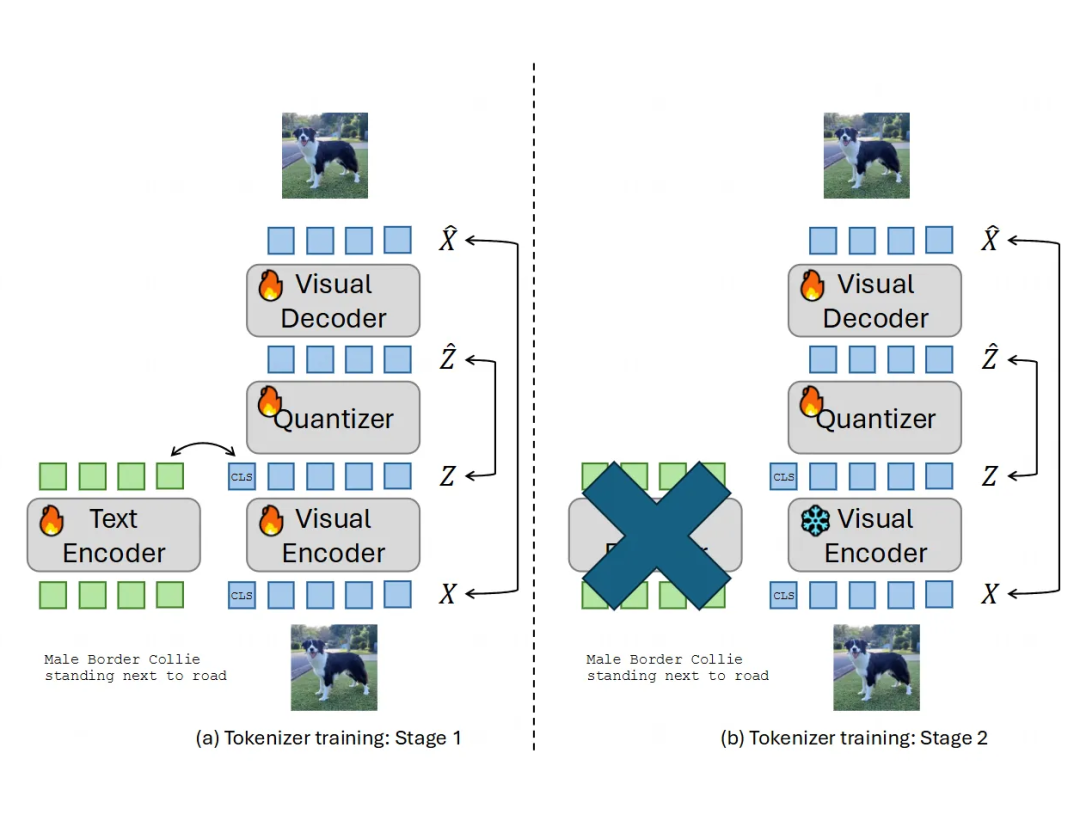
两阶段训练(Two-stage training):
第一阶段:主要目标是学习有意义的语义表示。只优化重建损失()、量化损失()和对比损失(),不加那些很占显存的感知损失(perceptual loss)和对抗损失(adversarial loss)。总损失是这三者的加权和:
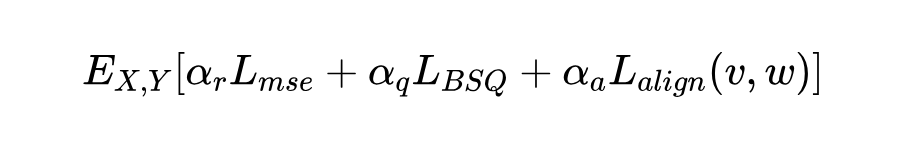
这里的 是权重系数。他们更看重对比损失,学习语义。
第二阶段:主要目标是提升图像重建的质量,恢复更多细节。冻结视觉编码器(防止语义表示变差),只微调量化器和解码器。这时候加入感知损失()和对抗损失(),同时保留重建和量化损失。总损失变为:
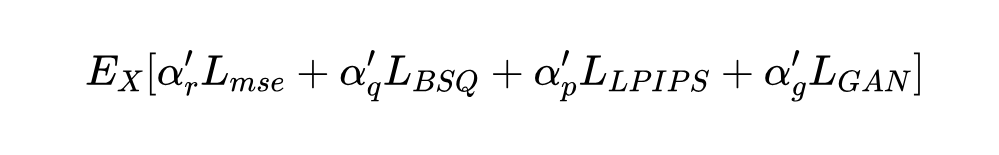
这时候因为不需要文本编码器了,可以适当调整批大小限制。
加速训练与更好的初始化(Accelerated training with better initializations):
-
从头训练 CLIP 类模型需要海量数据(几十亿样本)。为了加速,他们建议用 MIM(Masked Image Modeling)或 CLIP 预训练好的模型来初始化视觉编码器,用 CLIP 预训练好的模型初始化文本编码器。这样,据说用 40 亿样本就能达到不错的效果,比从零开始快 10 倍。
平衡重建和对齐目标(Balancing reconstruction and alignment objectives):
-
重建损失和对齐损失对模型参数的梯度幅度差异很大(可能差好几个数量级),导致它们收敛速度不一致。
-
他们提出一个简单的事后加权方法:分别单独训练只带重建损失和只带对齐损失的模型,看它们收敛后的最终损失值 和 。然后设置第一阶段训练时的权重比,使其与最终损失值成反比:
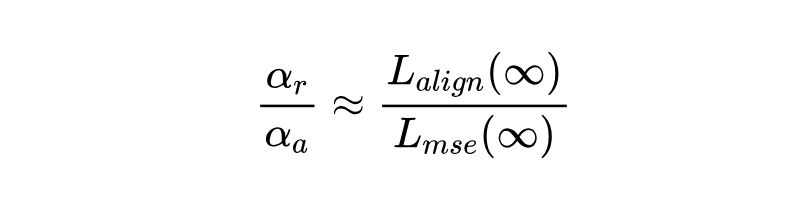
-
他们认为这种方法比一些自动调权重的自适应方法(需要额外计算梯度,带来时间和显存开销)更实用,并且发现这个比例比较稳定,在不同模型设置下都有效。
改进的 BSQ 瓶颈(Improved bottleneck in BSQ-AE):
-
原始 BSQ 里从 到 以及从 到 的投影是线性的。他们把这俩线性层换成了 MLP(多层感知机),让这个瓶颈部分更深、表达能力更强: 。
-
因为瓶颈变深了,他们还发现加入一个类似 VQ-VAE 里的 commitment loss 的辅助项 有助于改善重建效果( 表示 stop gradient,阻止梯度回传)。这个在原始线性 BSQ 里不是必需的。
4.2.4 UM3 模型架构与训练
有了 QLIP 产生的视觉 token,就可以构建统一多模态模型 UM3 了。
架构(Architecture):
-
基础模型是 Llama 3
-
为了解决多模态输入可能导致的 attention 计算中的数值不稳定问题(Chameleon 论文中提到),他们采用了 QK-Norm(Query-Key Normalization)。好消息是,QK-Norm 可以直接用到预训练好的 Llama 3 上,不需要从头训练。
-
扩展了模型的词嵌入层(token embedding)和输出层 (output layer)** 来容纳新的视觉 token。新增的视觉 token 的初始 embedding 用的是所有文本 token embedding 的平均值。
-
为了缓解 logit shift(不同模态输出概率分布范围不一致)问题,他们对文本 token 和视觉 token 分开计算 softmax:
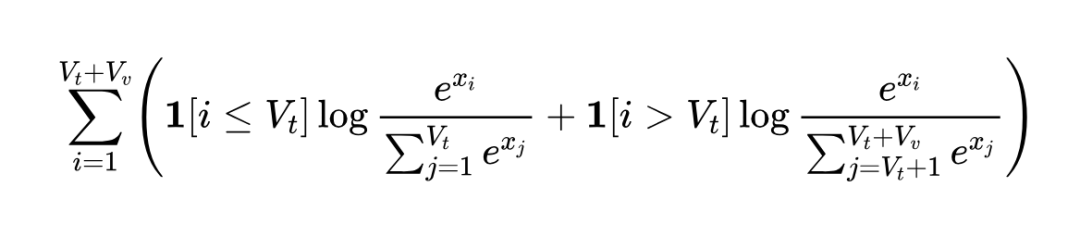
这里 是文本词汇量, 是视觉词汇量, 是第 个 token 的 logit 输出。
数据混合策略(Data Mixing):
-
训练时,每个批次里混合了纯文本、图文对、文图对(可能是指生成任务)数据。
-
为了防止模型在刚开始接触多模态数据时就“忘记”了强大的语言能力,他们提出了一个 “冷静期”(calm-down)数据混合调度策略。具体来说,在一个训练周期 内,每个批次中纯文本数据的比例 从一个较高的初始值 线性下降到一个较低的目标值 :
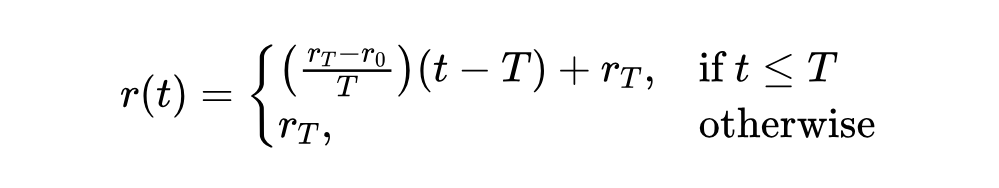
这里 是训练步数。这样可以平稳地过渡到多模态训练。
4.3 实验设置概览
训练 QLIP:主要用了 DataComp-1B 这个大数据集,包含十亿个图文对。
评估 QLIP:
-
视觉基础能力:在 ImageNet-1k 上测零样本分类准确率、线性探测准确率,还有图像重建质量(用 rFID、PSNR、SSIM 这些指标)。
-
图文理解能力:把 QLIP 的视觉编码器接到大语言模型(LLM)前面(像 LLaVA 1.5 那样),看看在视觉问答(VQAv2, GQA, TextVQA)和更复杂的 VLM 基准(POPE, MME, MM-Vet)上表现怎么样。他们用了一个可学习的投影网络 来连接视觉特征 和 LLM:
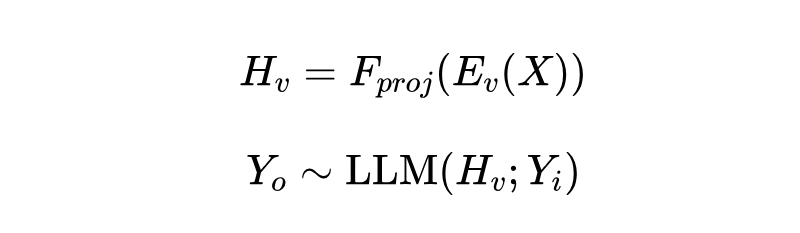
这里 是图像, 是输入的文本指令, 是模型生成的文本输出。
-
文生图能力:用 QLIP 把图像变成离散的视觉 token 序列 。然后用一个 Transformer 模型(类似 Llama-2)学习根据文本描述(编码成 )自回归地生成这些视觉 token:
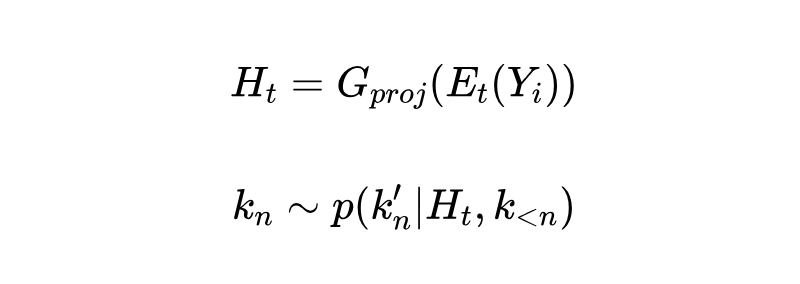
训练和评估统一多模态模型(UM3):
-
训练数据:混合了纯文本数据(DCLM-baseline)、图文对(CC-12M+SA-1B)。
-
评估:涵盖了纯文本任务(ARC-C, HellaSwag 等)、看图说话(MS-COCO Captioning)和文生图(MS-COCO)。
4.3.1 QLIP 效果怎么样?
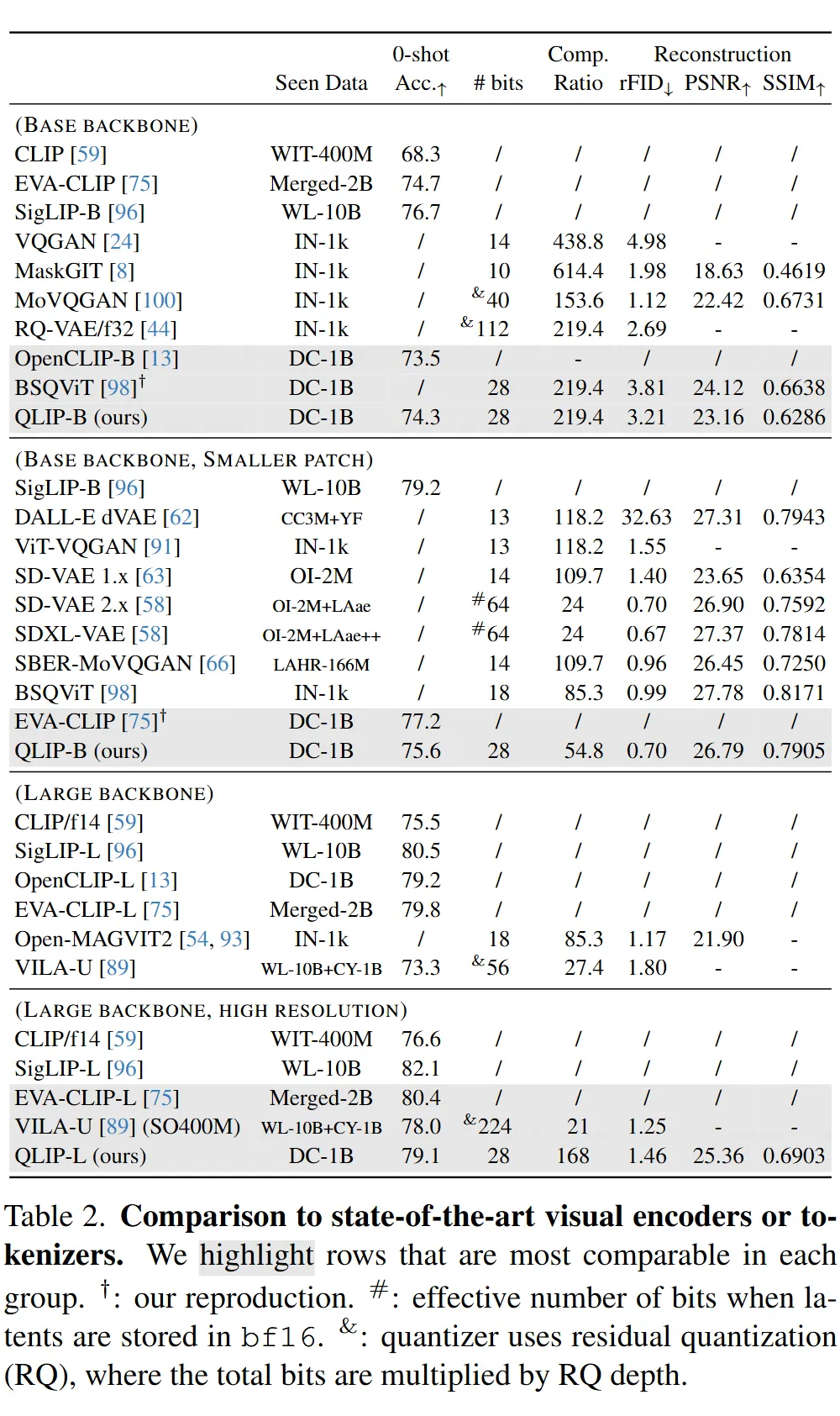
QLIP 又能打又能压:
-
在视觉理解(比如零样本图像分类)上,QLIP(如 QLIP-B)的表现和只做对比学习的 CLIP 模型差不多,甚至比一些 CLIP 变种(如 OpenCLIP-B)还好一点。
-
同时,QLIP 还能做图像压缩和重建,压缩率挺高(比如 QLIP-B 压缩到 28 比特,压缩比 219.4),重建质量(看 rFID, PSNR, SSIM)也跟专门做图像压缩的模型(比如 BSQViT)有一拼。
-
跟 VILA-U 的视觉模型比,QLIP-L 参数更少,但零样本分类性能更好,而且压缩率高得多(QLIP 8 倍 vs VILA-U 低压缩率),rFID 还很接近。这说明 QLIP 在理解和生成之间取得了不错的平衡。
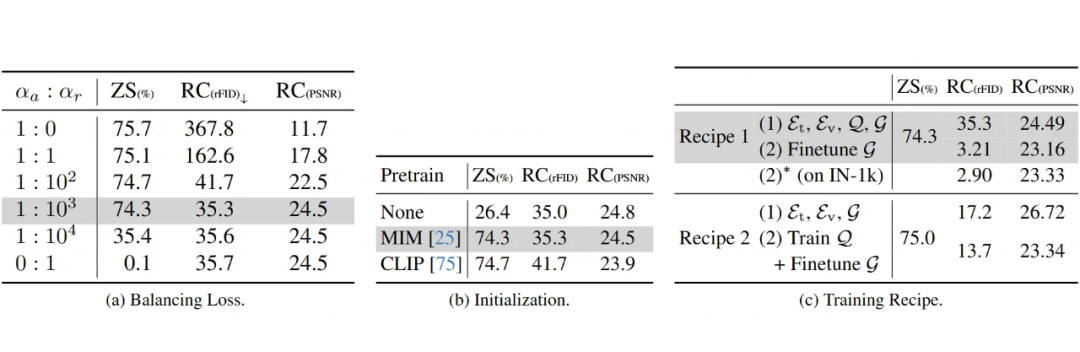
平衡损失很重要,但有技巧:
-
实验发现(Table 3a),调整对齐损失权重()和重建损失权重()确实影响很大。
-
如果 太高(太看重对齐),模型分类能力可能强,但图像重建质量会变得很差。
-
如果 太高(太看重建),重建质量可能好,但分类准确率提升缓慢。
-
他们提出的那个根据收敛后的损失反向定权重的方法(比如 )看起来效果不错,能在保证重建质量的同时,只比纯 CLIP 模型低一点点分类准确率(大概 1%)。
预训练初始化帮大忙:
-
从零开始训练 QLIP 的视觉编码器效果不好(Table 3b),就算用 20 亿样本,零样本分类准确率也很低(26.4%)。这说明光靠文本监督从头学视觉特征有点难。
-
用 MIM(Masked Image Modeling)或者 CLIP 预训练好的模型来初始化,效果就好多了,分类准确率能提到 74% 以上。
-
有趣的是,用 MIM 初始化在重建任务上比 CLIP 初始化表现更好。作者猜可能是因为 CLIP 训练出来的特征里有些“异常值”(outlier tokens with high norms),对重建不太友好。
两阶段训练确实管用:
第一阶段学语义,第二阶段专门优化重建。实验证明(Table 3c),第二阶段只微调解码器,能极大提升重建质量(rFID 从 35.3 降到 3.21),虽然 PSNR 可能稍微掉一点。
他们还试了另一种策略:第一阶段不加量化,只训练普通的自编码器 + 对比学习,到第二阶段再加入量化器训练。结果发现,虽然分类准确率和 PSNR 还行,但 rFID 变得非常差(13.7 vs 3.21)。
这说明,在第一阶段就让量化过程也接受语言信号的监督(通过对比损失)对于学习到包含高层语义信息的视觉 token 很重要,因为 rFID 这个指标主要看高级特征的相似度。
4.3.2 QLIP 在下游任务中的表现
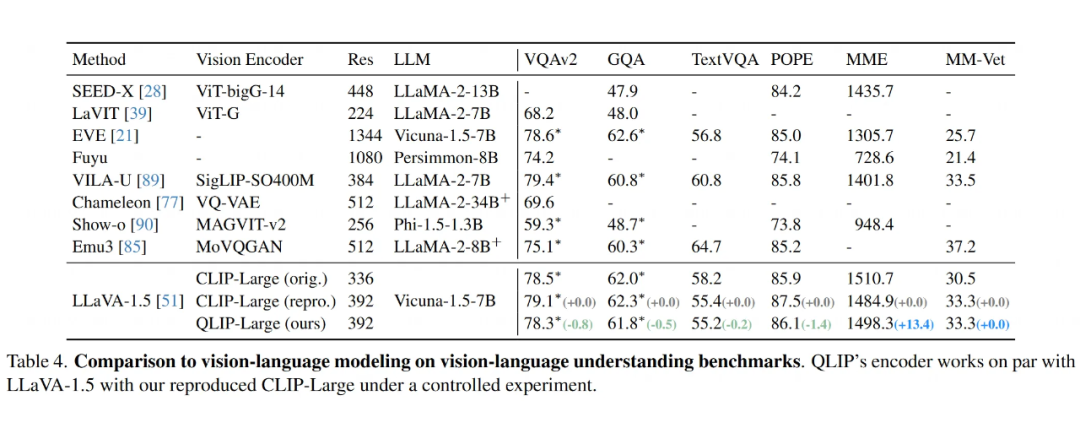
图文理解:QLIP 不输 CLIP:
-
把 QLIP 的编码器用到 LLaVA 1.5 这种 VLM 架构里,跟用同等规模、同样设置下复现的 CLIP 编码器相比,性能基本持平(Table 4)。各项指标互有胜负,总体差距不大。这说明 QLIP 在提供语义信息方面跟 CLIP 一样有效,同时还具备了生成能力的基础。
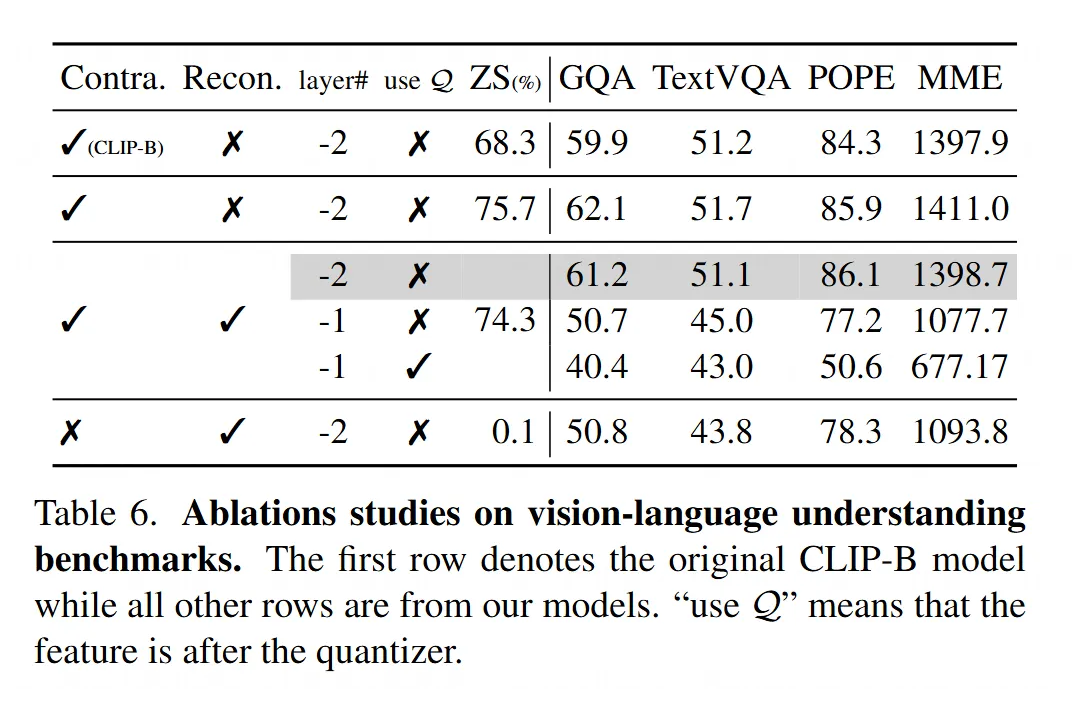
VLM 用哪层特征有讲究:
-
他们试了把 QLIP 编码器不同层的特征喂给 VLM(Table 6)。结果发现,用量化器前面那一层(倒数第二层)的特征效果最好。
-
如果用最后一层(更靠近重建目标)的特征,或者用量化器之后的特征,性能都会严重下降。这可能是因为最后一层为了重建牺牲了部分语义信息,而量化本身也会损失信息。
-
只用重建损失训练的自编码器,其特征用于 VLM 时效果也很差,再次证明了语言监督对于学习理解任务所需语义的重要性。
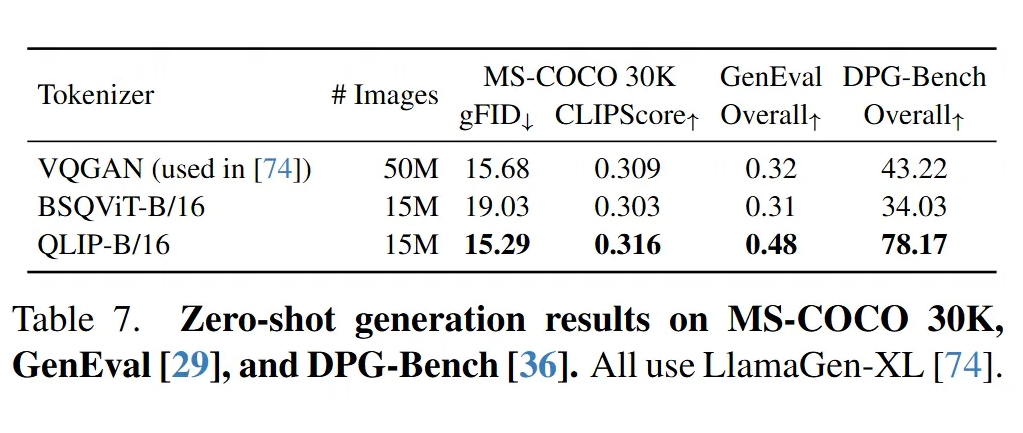
文生图:QLIP 比没对齐的更好:
-
把 QLIP 用在 LlamaGen 这个文生图框架里,跟用没有经过语言对齐的 BSQViT 或原始 LlamaGen 用的 VQGAN 相比,QLIP 能生成质量更高的图像(Table 7,看 gFID 和 CLIPScore)。
-
特别是,QLIP 只用了 LlamaGen 原训练数据量的 30%,效果就超过了原版 VQGAN。
-
从生成的图片例子来看(Figure 6),用 QLIP 生成的图更能紧扣文本描述的细节,比如 VQGAN 可能漏掉的“光束”、“水槽台面”、“白色灌木”、“看 [长颈鹿] 的人”等,QLIP 都能画出来。
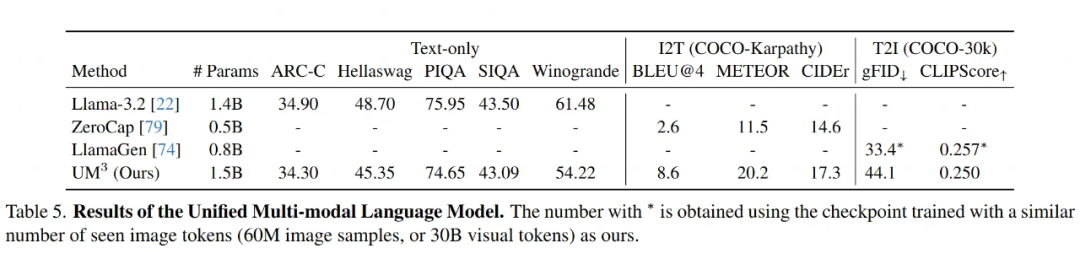
统一多模态模型(UM3)初见成效:
最后搞的那个 UM3 模型,想用一个模型搞定所有事(纯文本、看图说话、文生图)。
实验结果(Table 5)显示,这个 1.5B 参数的 UM3 模型:
-
在一些纯文本任务上,跟差不多大小的纯语言模型(Llama-3.2 1.4B)相比,表现差不多。
-
在看图说话(COCO Captioning)上,比之前的零样本方法(ZeroCap)好得多。
-
在文生图(MS-COCO)上,生成的图像质量(CLIPScore)跟专门的生成模型(LlamaGen)相当,但 FID 略差一点。
这初步说明,基于 QLIP 这种与语言对齐的视觉 token,训练一个能同时理解和生成多种模态的统一模型是可行的。

Deepseek – Janus-Pro
论文标题:
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
论文链接:
https://arxiv.org/abs/2501.17811
代码链接:
https://github.com/deepseek-ai/Janus
跟前面工作一致,本文 argue 的也是:
-
理解 VS 生成互掐:模型用同一套视觉编码处理图片理解和生成任务。就像用同一支笔画画和写文章,两边都施展不开。
-
小模型的局限:初代 Janus 只有 1B 参数,遇到简单指令(比如“画块黑板”)容易翻车,生成质量比专业绘图模型差一截。
于是,Janus-Pro 团队决定从训练策略、数据量和模型规模三路出击,打造更强大的多模态模型。
5.1 主要贡献
给视觉编码松绑:
-
把处理图片理解(比如回答问题时分析图片)和图片生成(比如画黑板)的模块拆开训练。
-
效果立竿见影:生成图片时细节更细腻(花瓣上的蜜蜂翅膀纹路都清晰),理解图片时答题正确率飙升。
数据扩展:
-
训练数据规模大幅扩展,还新加了专门提升生成稳定性的场景数据(比如节日物品图像)。
-
这让模型面对简短指令(如“新年橘子”)时,生成效果不再容易崩(不会把橘子画成苹果)。
模型扩展:
-
推出两个版本:1B 参数版保持轻量,7B 参数版主打性能。
-
7B 版本在 MMBench 综合测试中拿下 79.2分,碾压 MetaMorph 等对手。生成质量在 GenEval 测评里干掉了 DALL-E 3 这种专业选手。
5.2 方法详细
Janus-Pro 是对前代模型 Janus 的升级版,这篇论文详细介绍了它的“方法”部分。研究人员通过优化架构、训练策略、数据和模型规模,让它在多模态理解和图像生成上都更厉害。
5.2.1 架构
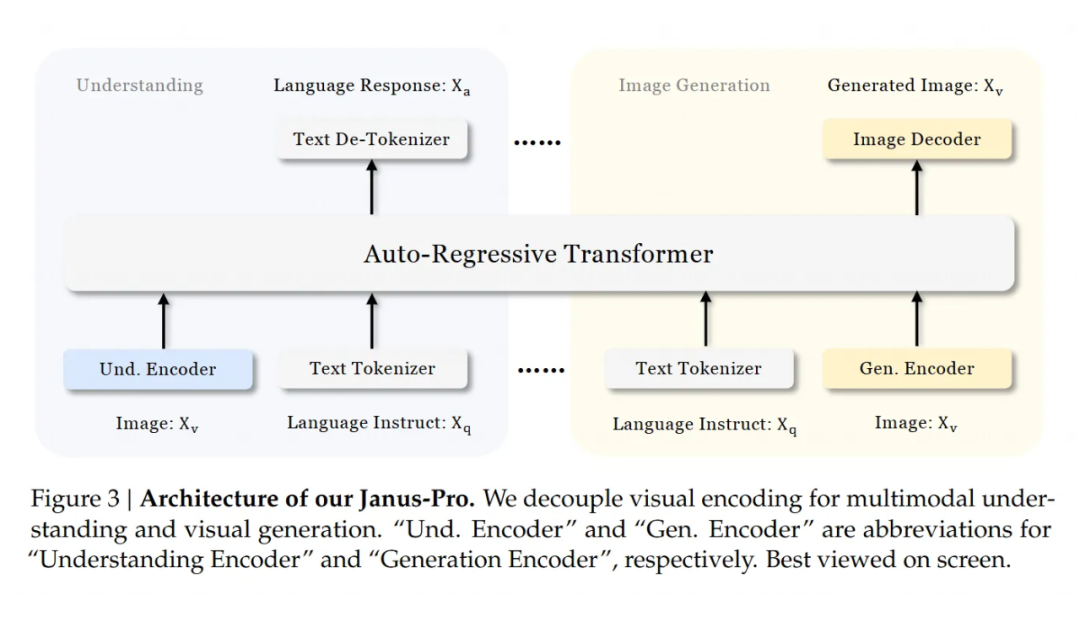
Janus-Pro 的架构跟 Janus 一样,核心想法是把视觉编码分开处理,避免理解和生成任务抢资源:
-
理解任务:用 SigLIP 编码器从图像里挖出高级语义特征(就是理解图片里“讲了啥”),这些特征本来是二维网格的,先拍平成一维序列,再通过一个“理解适配器”映射到语言模型(LLM)的输入空间。
-
生成任务:用 VQ tokenizer 把图像转成一堆离散的 ID(就像把图片拆成小块拼图),然后把这些 ID 对应的码本嵌入(codebook embedding)通过“生成适配器”也映射到 LLM 的输入空间。
最后,把理解和生成的特征拼成一个多模态序列,扔给一个统一的自回归 Transformer 处理。LLM 自带一个预测头负责文本输出,另外还加了个随机初始化的图像预测头,专门管生成图片。整个模型是自回归的。
5.2.2 训练策略
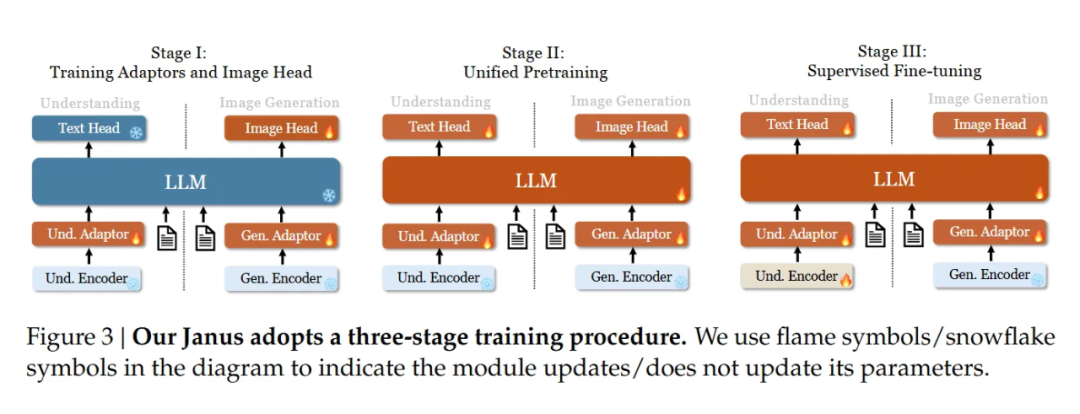
Janus 原来用的是三阶段训练,但有些地方效率不高。Janus-Pro 做了调整,让训练更聪明:
第一阶段:原来第一阶段主要是训练适配器和图像头,用的是 ImageNet 数据。Janus-Pro 把这阶段的训练步数加长了,发现即使 LLM 参数不动,模型也能学会像素之间的联系,根据类别名生成像样的图片。
第二阶段:Janus 在第二阶段把文本-图像训练分成两块:先用 ImageNet 数据练像素依赖,再用正常文本-图像数据练生成,结果有三分之二的时间花在了前者上,太浪费。Janus-Pro 直接砍掉 ImageNet,改用正常文本-图像数据,让模型专注学怎么根据详细描述画图。
第三阶段调比例:在监督微调阶段,Janus-Pro 把多模态数据、纯文本数据和文本-图像数据的比例从原来的 7:3:10 改成了 5:1:4。稍微少用点图像数据后,发现生成能力没掉,反而理解能力更强了。
5.2.3 数据扩展
Janus-Pro 在数据上下了大功夫:
理解数据:
-
第二阶段预训练加了 9000 万条样本,包括图片描述(比如 YFCC 数据集)、表格、图表和文档理解(比如 Docmatix 数据集)。
-
第三阶段微调又加了 MEME 理解、中文对话等数据,丰富了模型的对话能力和任务范围。
生成数据:
-
Janus 原来用的是真实数据,质量不稳定,生成的图片经常不好看。Janus-Pro 加了 7200 万条合成美学数据,让真实和合成数据的比例变成 1:1。这些合成数据的提示词是公开的,质量有保障。
-
实验发现,合成数据让模型学得更快,生成的图片更稳定,审美水平也更高。
5.3 实验发现
这篇文章的实验部分详细展示了 Janus-Pro 在多模态理解和视觉生成任务上的表现。研究人员通过一系列测试,挖出了一些特别好玩的发现。下面就用通俗的语言,把这些亮点整理出来,讲讲 Janus-Pro 到底有多厉害。
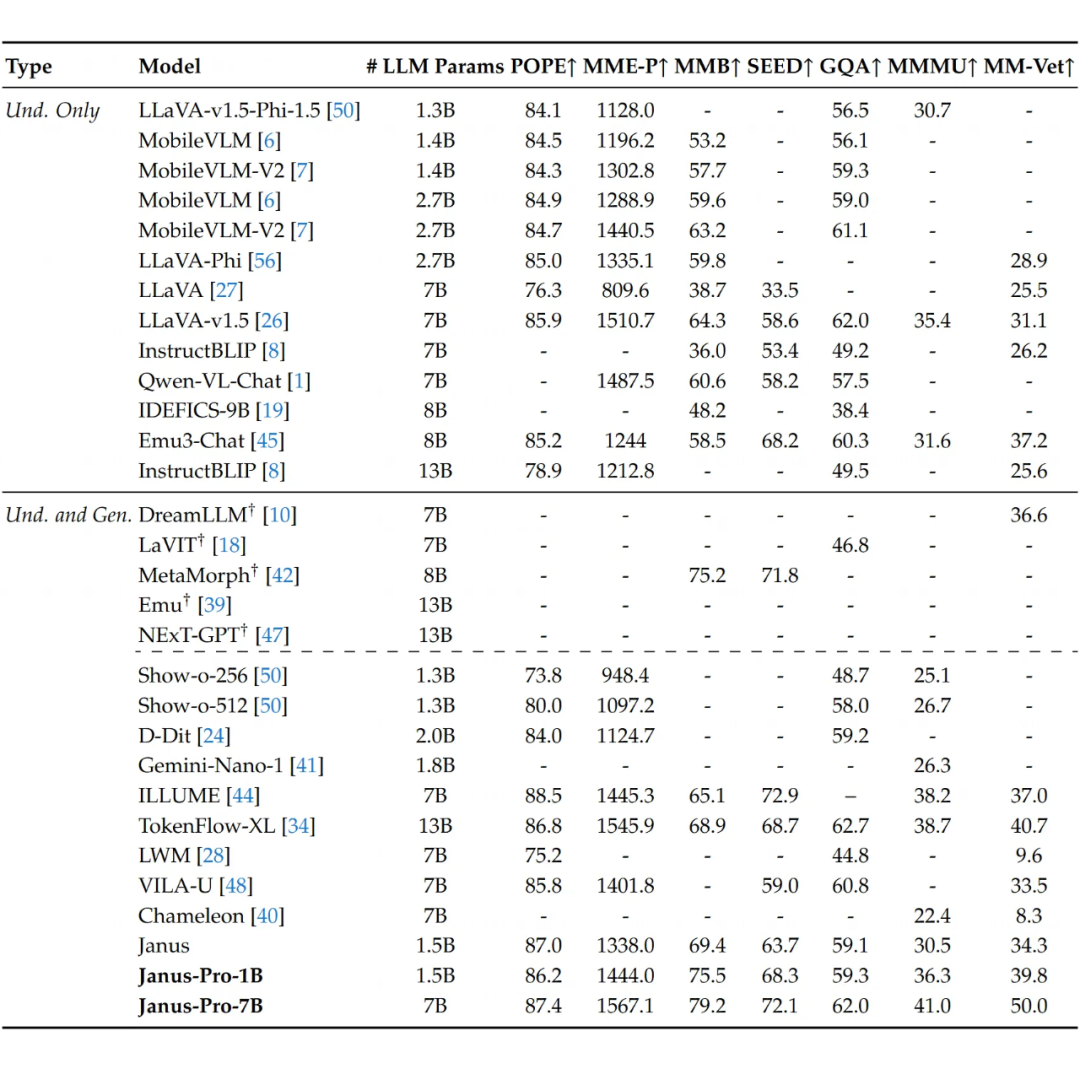
多模态理解 Janus-Pro-7B 在 MMBench 上拿了 79.2 分,比原来的 Janus(69.4 分)高出一大截,还超过了其他统一模型,比如 TokenFlow-XL(68.9 分)和 MetaMorph(75.2 分)。
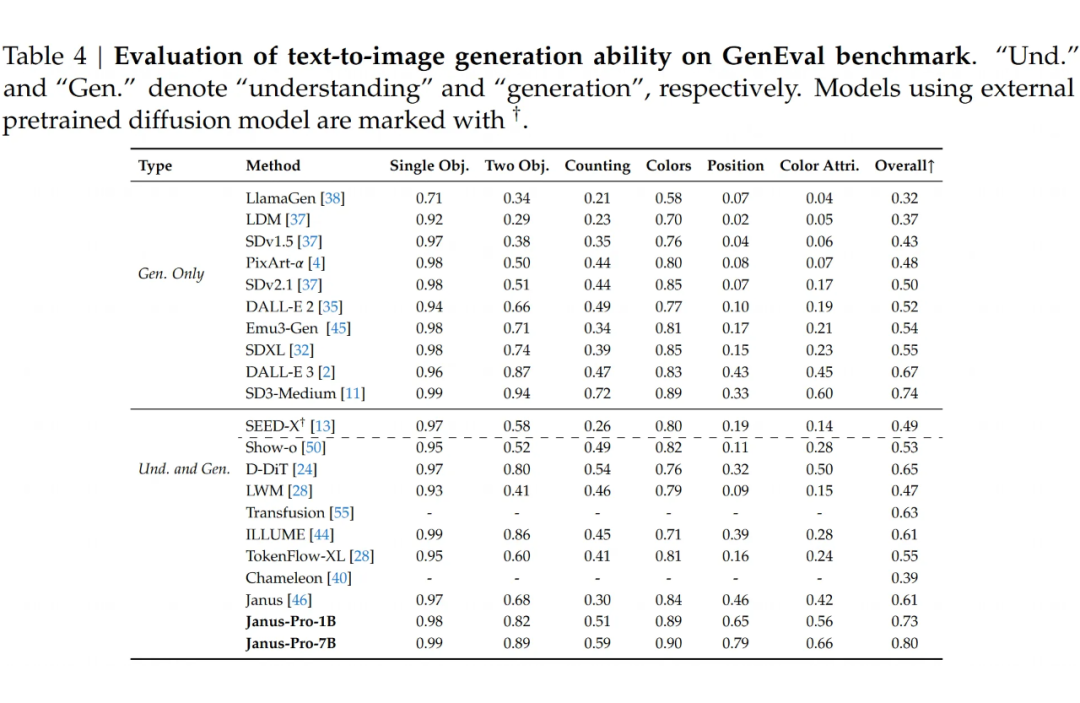
图像生成:在 GenEval 测试里,Janus-Pro-7B 的总体准确率达到 80%,碾压了其他模型,比如 Transfusion(63%)、SD3-Medium(74%)和 DALL-E 3(67%)。
数据质量比数量更重要:用了 7200 万条合成美学数据后,模型学得更快,生成的图片更稳定、更漂亮。
-
启示:不是数据越多越好,高质量的合成数据比杂乱的真实数据更能帮模型提升审美和稳定性。

Unify 多模态模型进展总结与未来方向
当前围绕”理解-生成”统一多模态系统的研究呈现出三大主攻路线,在模型架构与表达能力上取得关键突破:
功能边界的双向突破
-
自回归派(MLLM)通过学习图像离散表征与预测头,实现了从纯理解到可控生成的跨越(如 Janus-Pro 的适配器设计);
-
扩散派(Stable Diffusion 等)通过注入对比学习目标与问答数据,使生成过程具备场景推理能力(如 D-DiT 在视觉问答中的 60%+ 准确率);
模型架构的范式革新
-
探索出文本-图像对偶训练架构(D-DiT 的双分支设计)、多码本量化(UniTok 的子字典拼接)、任务感知剪枝(UniMoD 的差异化路由)等创新方案,解决传统架构中模态冲突与效率瓶颈的问题;
基础表征的改进方案
-
新型视觉 tokenizer(如 UniTok/QLIP)通过语义-细节分层编码,让单一特征兼具 CLIP 的高层语义和 VQ-GAN 的像素级重建能力,突破离散表征的信息容量限制
同时除了方法以外,如何评估 Unify MLLM 也是一个大问题,现有的 benchmark 1)缺乏传统任务的标准化基准,都是各自找一些 benchmark 分开评估理解和生成,导致比较结果不一致,信服力差;2)缺乏混合模态生成基准,无法评估多模态推理能力,比如图文交错生成。
近期虽然出现了一些工作比如 [MME-Unify](https://mme-unify.github.io/),但是数据量,任务种类,评估方式等都还比较初始,有很大的进步空间。
(文:PaperWeekly)