

机器之心编辑部
随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。
视频细粒度文本描述
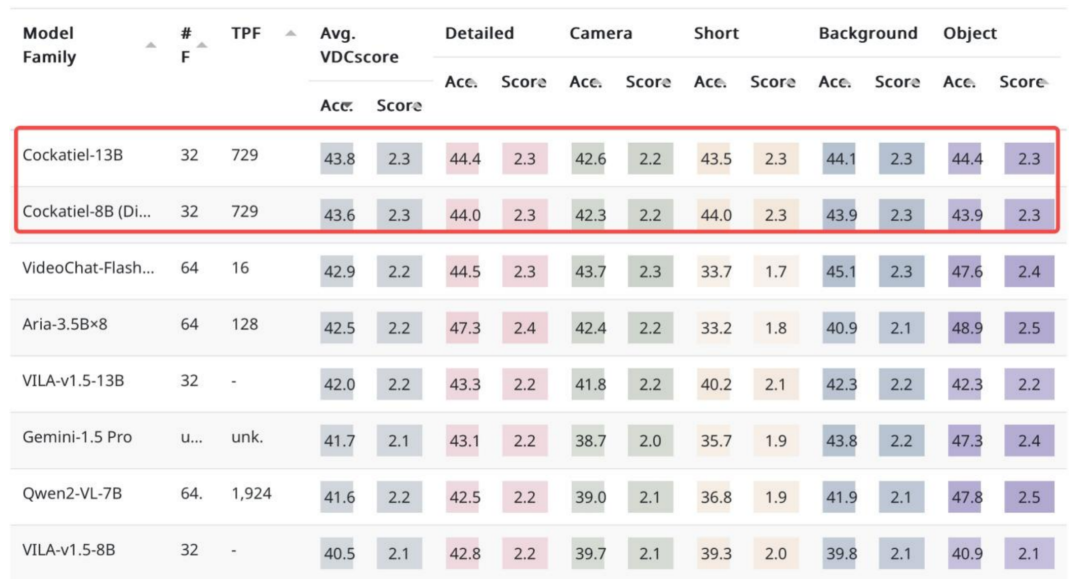
视频细粒度文本描述模型(video detailed caption)为视频生成模型提供标签,是视频生成的基础。复旦大学等机构提出了 Cockatiel 方法 [3],该方法在权威的 VDC(Video Detailed Captioning 视频细粒度文本描述评测集)榜单上获得第一名,超过了包括通义千问 2-VL、VILA1.5、LLaVA-OneVision,Gemini-1.5 等在内的多个主流视频理解多模态大模型。

-
论文标题:Cockatiel: Ensembling Synthetic and Human Preferenced Training for Detailed Video Caption
-
项目主页: https://sais-fuxi.github.io/projects/cockatiel/
-
论文地址: https://arxiv.org/pdf/2503.09279
-
Github: https://github.com/Fr0zenCrane/Cockatiel
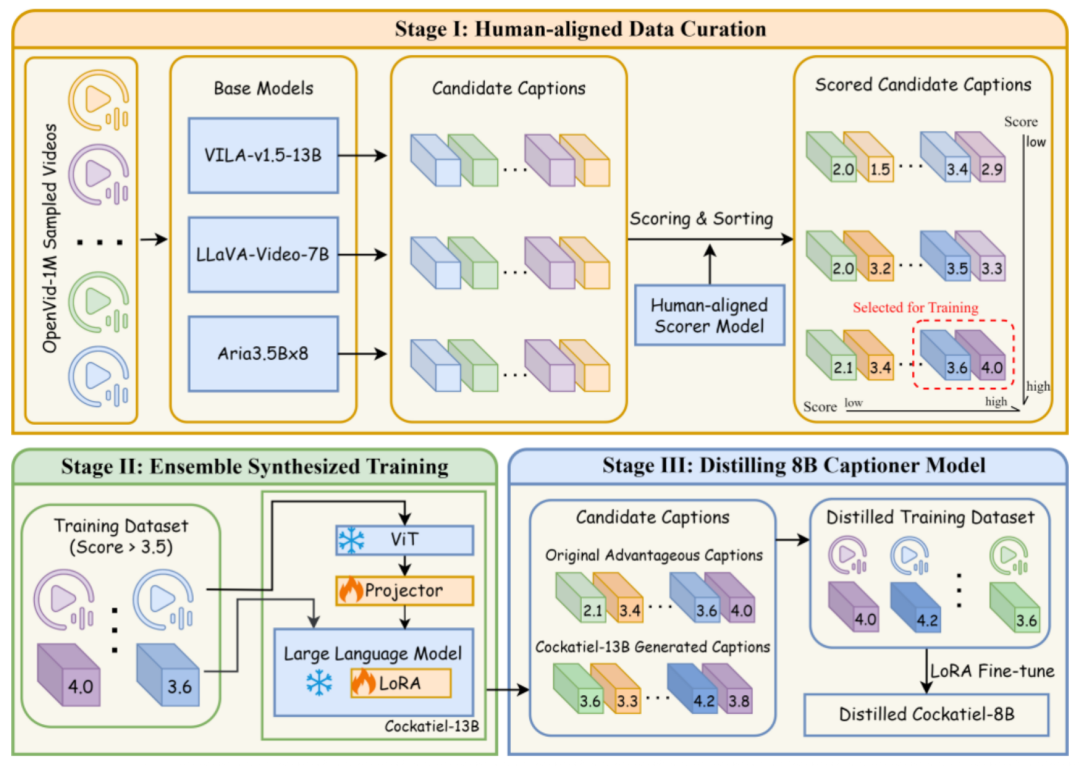
Cockatiel 的核心思路是:基于人类偏好对齐的高质量合成数据,设计三阶段微调训练流程,系统集成了多个在不同描述维度上表现领先的模型优势。通过这一方法,以单机的训练成本训练出了一套在细粒度表达、人类偏好一致性等方面均表现卓越的视频细粒度描述模型,为后续视频生成模型的训练和优化打下了坚实基础,模型细节如下(更多详情可参考论文和开源 github):
-
阶段一:构造视频细粒度描述的人类偏好数据:分别对视频描述的对象、对象特征、动态特征、镜头动作和背景的文本描述质量进行人工标注。
-
阶段二:基于打分器的多模型集成训练:基于人工标注数据训练奖励函数(reward model),并多个模型合成的视频描述计算奖励(reward),最终对 13B 的多模态大语言模型进行人类偏好对齐优化。
-
阶段三:蒸馏轻量化模型:基于上一步训练的 13B 的多模态大语言模型蒸馏 8B 模型,方便后续在下游任务中低成本推理。
实验结果显示基于 Cockatiel 系列模型生成的视频细粒度描述,具备维度全面、叙述精准详实以及幻觉现象较少的显著优势。如下图所示,与 ViLA,LLaVA 和 Aria 的基线模型相比,Cockatiel-13B 不仅能够准确复现基线模型所描述的细节(以黄底高亮部分表示),还能捕捉到基线模型遗漏的关键信息(以红底高亮部分表示)。而 Cockatiel 生成的描述则大量避免了幻觉性内容,Cockatiel 展现了更高的可靠性和准确性。

强化学习加强的视频生成技术
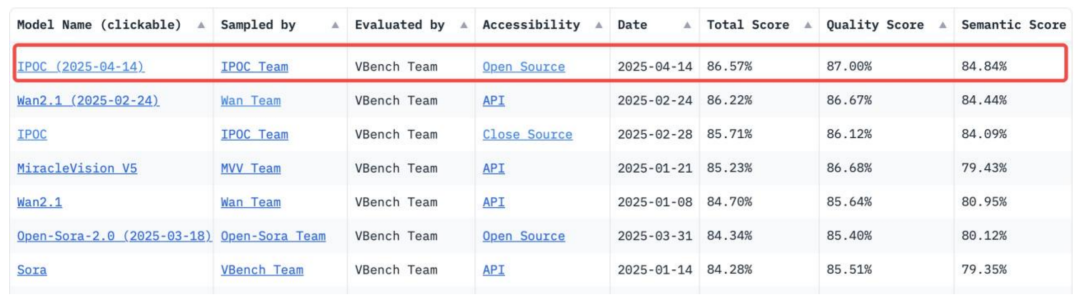
在视频生成领域,该团队首次提出了迭代式强化学习偏好优化方法 IPOC [4],在权威视频生成评测榜单 VBench (2025-04-14) 上,IPOC 以 86.57% 的总分强势登顶,领先通义万相、Sora、HunyuanVideo、Minimax、Gen3、Pika 等众多国内外知名视频生成模型。

-
论文标题:IPO: Iterative Preference Optimization for Text-to-Video Generation
-
论文地址:https://arxiv.org/pdf/2502.02088
-
项目主页:https://yangxlarge.github.io/ipoc//
-
GitHub 地址:https://github.com/SAIS-FUXI/IPO
研究者通过迭代式强化学习优化方式,避免了强化学习中训练不稳定的问题。同时只需要依赖少量的训练数据和算力,以低成本实现效果优化。 模型细节如下(更多详情可参考论文和开源 github):
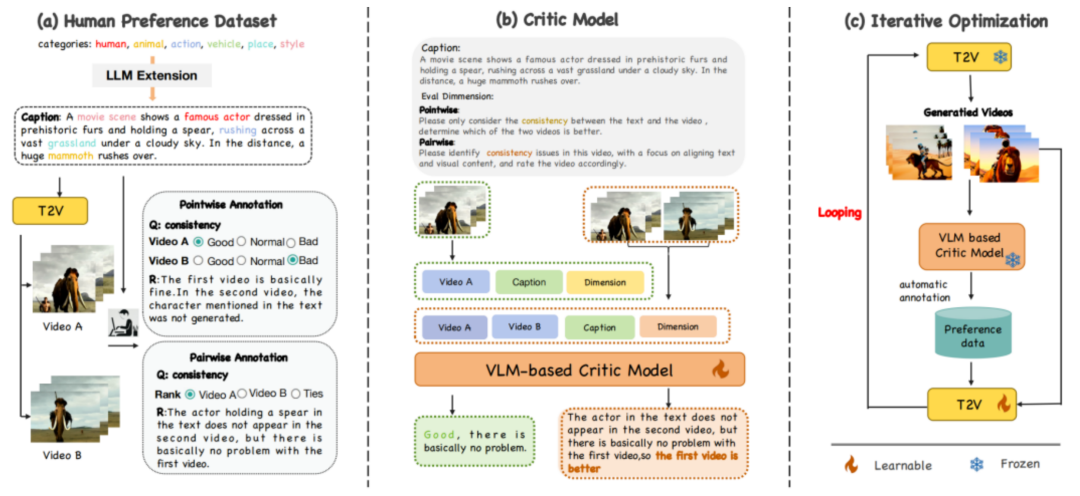
阶段一:人工偏好数据标注:IPO 方法通过逐视频打分(Pointwise Annotation)与成对视频排序(Pairwise Annotation)两种方式进行人工标注。标注过程中,标注者不仅需要提供评分或排序结果,还需详细阐述评分理由,以构建具有思维链(Chain-of-Thought, CoT)风格的标注数据。这种标注形式有助于模型深入理解视频内容与文本描述之间的语义一致性,从而形成高质量的人类偏好数据集。
阶段二:奖励模型训练:IPO 方法进一步引入了一种基于多模态大模型的 “奖励模型”(Critic Model)。奖励模型仅通过少量人工标注数据和少量算力即可高效训练完成,随后可自动实现对单个视频的评分以及对多个视频的对比排序。这种设计无需在每次迭代优化时都重新进行人工标注,显著提高了迭代优化效率。此外,奖励模型具备出色的通用性和 “即插即用” 特性,可广泛适配于各类视频生成模型。
阶段三:迭代强化学习优化:IPO 方法利用当前的视频生成(T2V)模型生成大量新视频,并由已训练的奖励模型对这些视频进行自动评价与标注,形成新的偏好数据集。随后,这些自动标注的数据用于进一步优化 T2V 模型。这一过程持续迭代循环,即:“视频生成采样 → 样本奖励计算 → 偏好对齐优化”。此外,我们提出的 IPO 框架同时兼容当前主流的偏好优化算法,包括基于对比排序的 Diffusion-DPO 方法与基于二分类评分的 Diffusion-KTO 方法,用户可灵活选择训练目标,其中两种人类偏好对齐方法(DPO 和 KTO)的训练目标为:
-
DPO (Direct Preference Optimization):
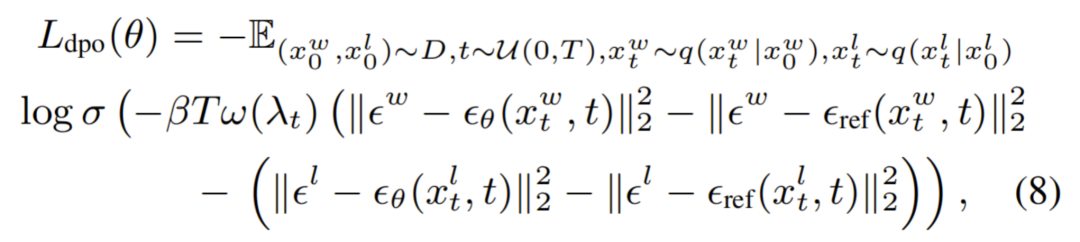
-
KTO (Kahneman-Tversky Optimization):

实验结果显示经过优化后,视频生成模型在时序一致性上实现了显著提升。相比于 CogVideoX-2B(左图),IPOC-2B 生成的视频(右图)中,狮子的行走动作更加自然连贯,整体动态流畅度有了明显改善。
Prompt: An astronaut in a sandy-colored spacesuit is seated on a majestic lion with a golden mane in the middle of a vast desert. The lion’s paws leave deep prints in the sand as it prowls forward. The astronaut holds a compass, looking for a way out of the endless expanse. The sun beats down mercilessly, and the heat shimmers in the air.
视频生成模型在结构合理性提升明显。相比于 CogVideoX-2B(左图),IPOC-2B 生成的视频(右图)中,人物和猛犸象具有更好结构合理性。
Prompt: A young girl in a futuristic spacesuit runs across a vast, icy landscape on a distant planet, with a towering mammoth-like creature beside her. The mammoth’s massive, shaggy form and long tusks contrast with the stark, alien environment. The sky above is a deep, star-filled space, with distant planets and nebulae visible.
视频生成模型在动态程度和美学度都有明显提升,相比于 CogVideoX-2B(左图),IPOC-2B 生成的视频(右图)中,人物动作更加流畅,人物和背景更好美观。
Prompt: A woman with flowing dark hair and a serene expression sits at a cozy The café, sipping from a steaming ceramic mug. She wears a soft, cream-colored sweater and a light brown scarf, adding to the warm, inviting atmosphere. The The café is dimly lit with soft, ambient lighting, and a few potted plants add a touch of greenery.
相关内容:
[1].Chai, Wenhao, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, and Christopher D. Manning. “Auroracap: Efficient, performant video detailed captioning and a new benchmark.” arXiv preprint arXiv:2410.03051 (2024).Project Page:https://wenhaochai.com/aurora-web/
[2].Huang, Ziqi, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang et al. “Vbench: Comprehensive benchmark suite for video generative models.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21807-21818. 2024.Project Page:https://vchitect.github.io/VBench-project/
[3].Qin, Luozheng, Zhiyu Tan, Mengping Yang, Xiaomeng Yang, and Hao Li. “Cockatiel: Ensembling Synthetic and Human Preferenced Training for Detailed Video Caption.” arXiv preprint arXiv:2503.09279 (2025).Porject Page:https://sais-fuxi.github.io/projects/cockatiel/
[4].Yang, Xiaomeng, Zhiyu Tan, and Hao Li. “Ipo: Iterative preference optimization for text-to-video generation.” arXiv preprint arXiv:2502.02088 (2025). Porject Page:https://yangxlarge.github.io/ipoc//
©
(文:机器之心)