

-
通过 GRPO 训练 DeepSeek-R1-Zero 模型。 -
在 DeepSeek-R1-Zero 生成的 CoT 数据和其他来源的数据上进行 SFT(冷启动)。 -
在推理密集型数据上进行 GRPO。 -
在大约 60 万个推理实例和 20 万个非推理实例上进行 SFT。注意,这一阶段从 DeepSeek-V3-base 模型重新开始。 -
使用 GRPO 在多样化的提示分布(包括安全训练)上进行强化学习微调。

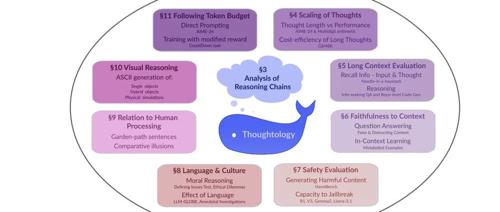
提出了一个分类体系,将DeepSeek-R1的推理链条分解为以下几个基本单元:
-
问题定义(Problem Definition):模型重新定义问题目标,通常以“我需要找到……”(I need to find…)结尾。
-
分解周期(Bloom Cycle):模型首次分解问题,生成中间答案,并可能验证其信心。
-
重构周期(Reconstruction Cycle):模型重新考虑初始假设,可能引入新的答案或验证现有答案。
-
最终决策(Final Decision):模型得出最终答案,并表达对答案的信心。

通过分析DeepSeek-R1在多个任务中的推理链条,揭示了以下关键发现:
-
推理链条的结构一致性:DeepSeek-R1的推理链条在不同任务中表现出一致的结构,通常包括问题定义、分解、多次重构和最终决策。
-
反刍行为(Rumination):模型在重构阶段会多次重新考虑问题的初始分解,这种行为类似于人类的“反刍”,但缺乏有效的监控机制。
-
推理链条的长度:推理链条的长度在不同任务中有所不同,但通常在分解周期最长,随后的重构周期逐渐变短,偶尔会出现较长的重构周期。
-
推理链条的多样性:在复杂的任务中,模型可能会尝试多种不同的问题分解方式,并在后续的重构周期中验证这些分解。
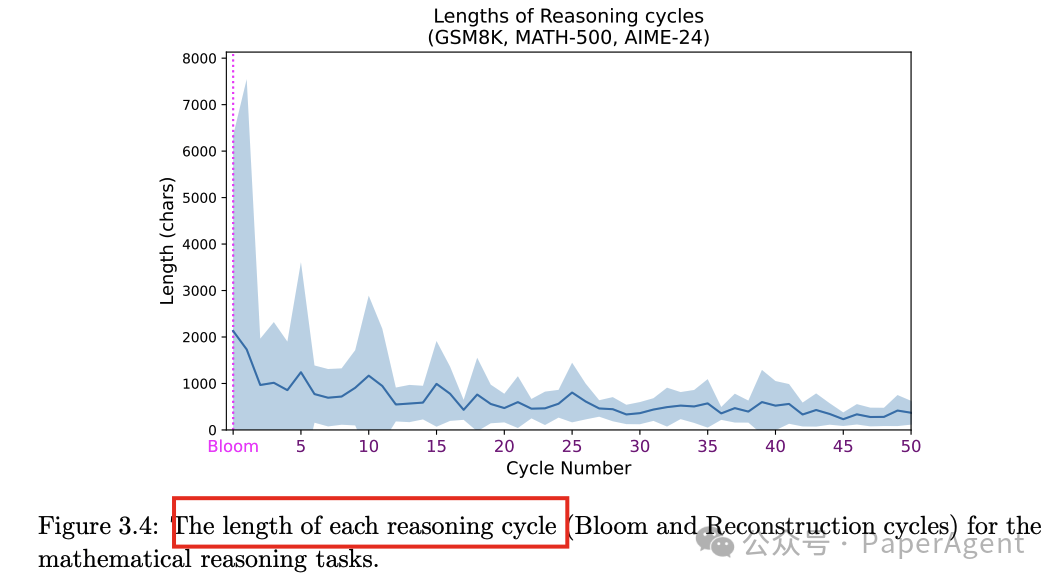

三、DeepSeek R1推理长度的影响
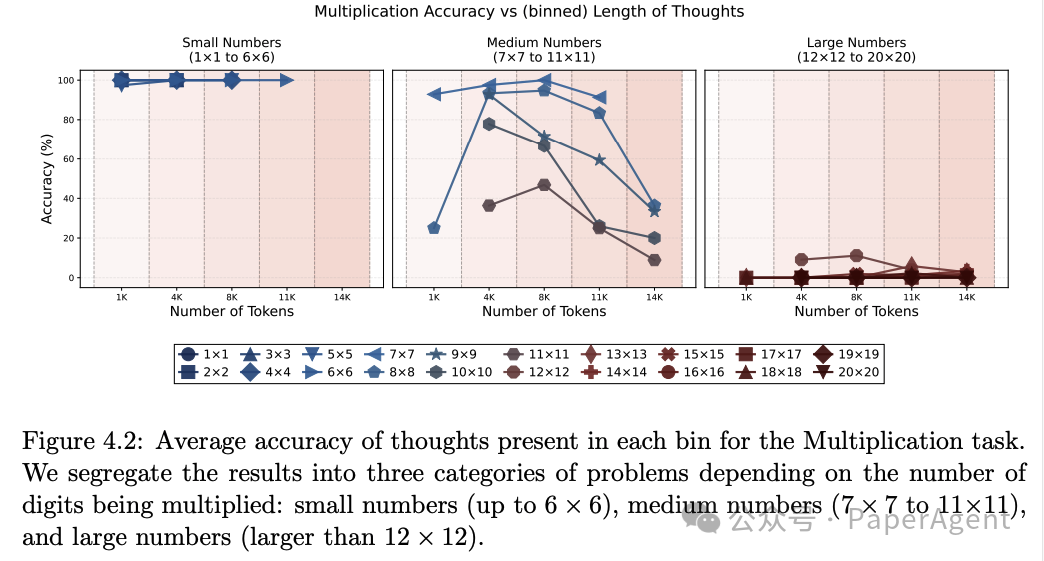
通过实验分析了推理长度对模型性能的影响,发现存在一个“推理甜点区”,超过这个长度范围,性能会下降。
-
对于某些问题,随着推理长度的增加,准确率先是上升,达到一个峰值后开始下降。这表明存在一个最优的推理长度范围(即“推理甜点区”),在这个范围内,模型的性能最佳。
-
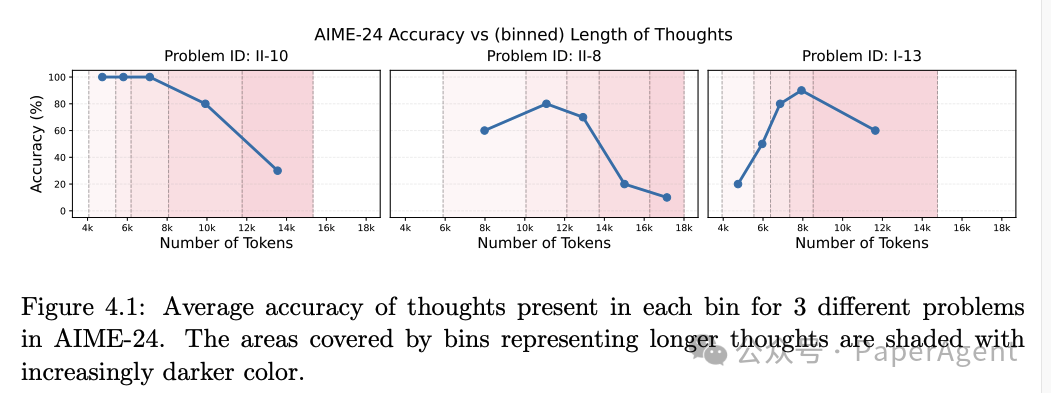
例如,对于 AIME-24 中的某些问题,推理长度在 6k 到 10k tokens 之间时,准确率最高,超过这个范围后,准确率显著下降。
-
对于小数字乘法问题,模型几乎总是能够正确回答,推理长度对准确率影响不大。
-
对于中等数字乘法问题,推理长度与准确率的关系与 AIME-24 类似,存在一个最优的推理长度范围。
-
对于大数字乘法问题,模型几乎总是失败,这表明推理长度的增加并不能解决所有问题,某些问题可能需要其他策略。
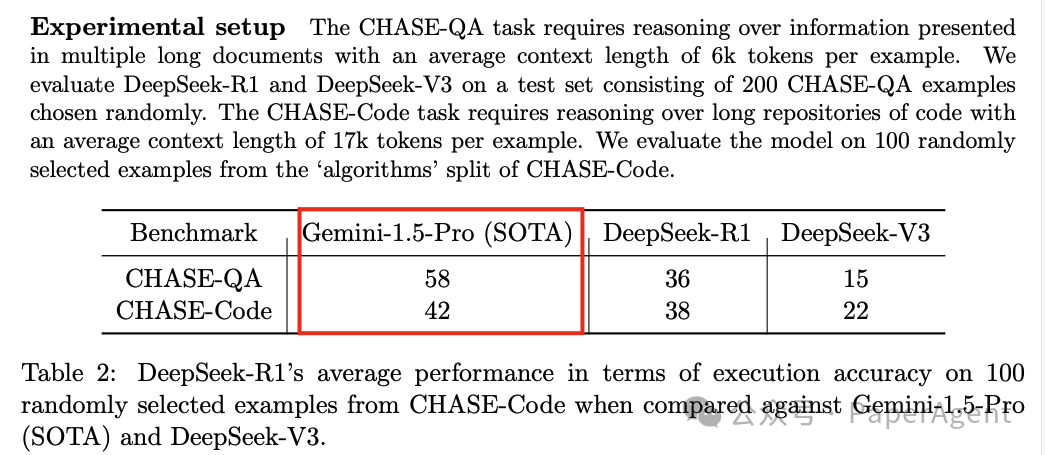

-
DeepSeek-R1在处理Garden path sentences时生成的推理链条显著长于处理非花园路径句时的推理链条。
-
这种推理链条长度的差异与人类处理Garden path sentences时的认知负荷高度相关,表明DeepSeek-R1在处理复杂句子时的行为与人类有一定的相似性。
-
然而,DeepSeek-R1在处理控制句(非Garden path sentences)时,推理链条长度不合理地长,且存在重复和循环推理的现象,这与人类的处理方式有显著差异。

-
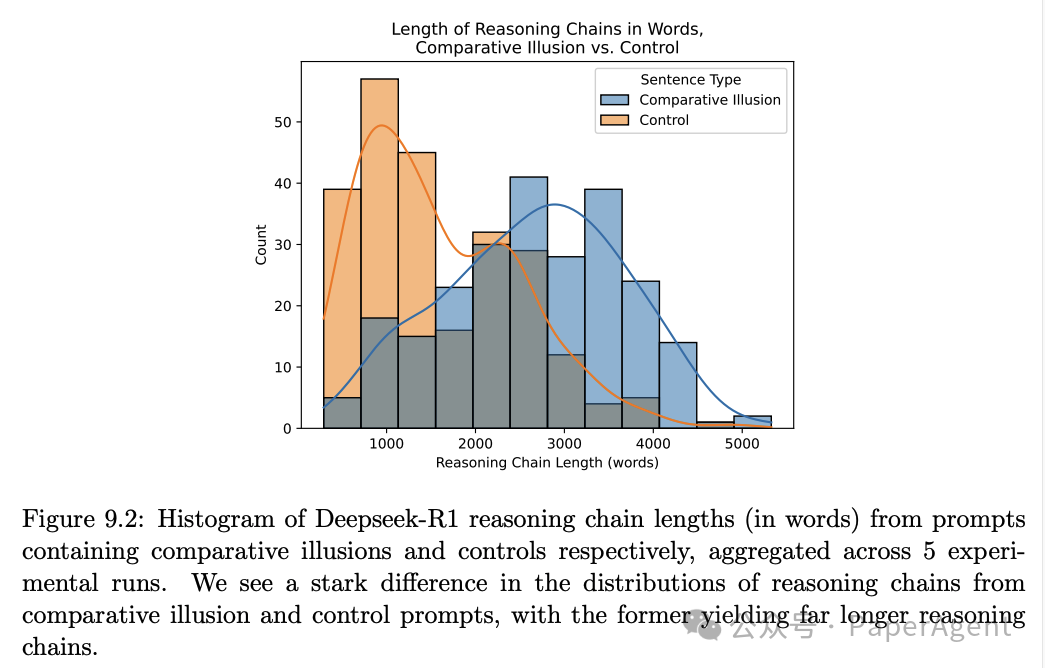
DeepSeek-R1在处理比较错觉句时生成的推理链条显著长于处理控制句时的推理链条。
-
这种推理链条长度的差异进一步支持了DeepSeek-R1在处理复杂句子时的认知负荷与人类相似的观点。
-
然而,DeepSeek-R1在处理控制句时仍然表现出不合理的长推理链条和重复推理行为,这表明其推理过程缺乏人类的高效性和目标导向性。
DeepSeek-R1 Thoughtology:Let’s about LLM reasoninghttps://arxiv.org/pdf/2504.07128
(文:PaperAgent)