



-
构建包含代码增强的长形式推理轨迹的数据集DCI

-
监督微调(SFT):使用DCI数据集对模型进行监督微调,使模型学会何时以及如何调用代码解释器,增强模型对计算工具的使用能力。
-
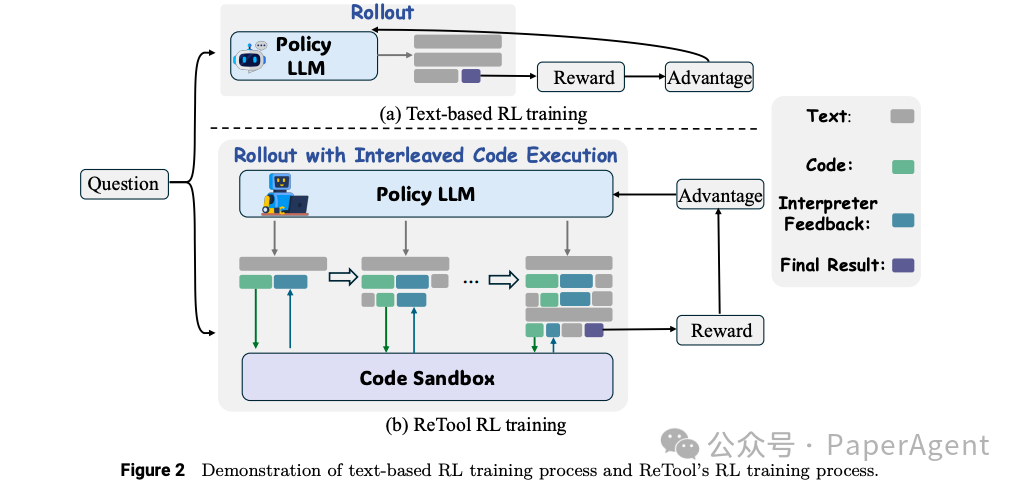
训练算法:基于PPO(Proximal Policy Optimization)算法进行训练,修改PPO以适应工具集成推理。在训练过程中,策略LLM与代码沙箱协作,生成包含多轮实时代码执行的rollout,用于解决给定问题。

-
奖励设计:采用基于规则的准确性奖励,通过比较模型输出的最终答案与真实答案来优化模型。要求模型以特定格式(如\boxed{})呈现最终答案,以便进行可靠的基于规则的验证。

-
动态代码执行:提出一种支持推理和可执行代码动态集成的rollout方法。策略模型在生成文本推理的同时,可以动态地执行代码片段,并根据代码解释器的反馈调整后续推理过程。这种方法使模型能够在推理过程中迭代探索、优化和调整其策略。
-
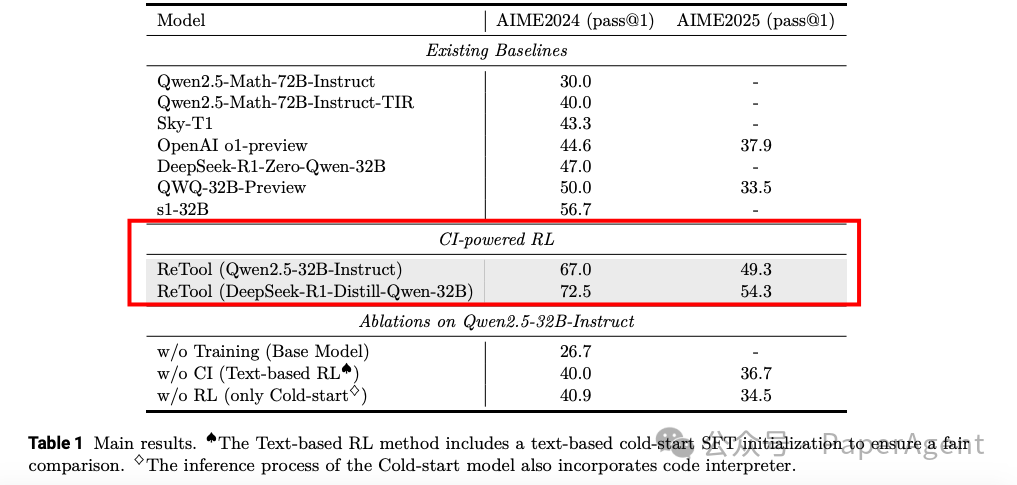
ReTool在AIME2024上达到了67.0%的准确率,仅用了400个训练步骤,显著优于基于文本的RL基线(40.0%准确率,1080个训练步骤)。 -
在AIME2025上,ReTool达到了49.3%的准确率。 -
此外,ReTool在与更先进的模型(如DeepSeek-R1-Distill-Qwen-32B)结合时,性能进一步提升,分别达到了72.5%和54.3%的准确率,比OpenAI的o1-preview高出27.9%
-
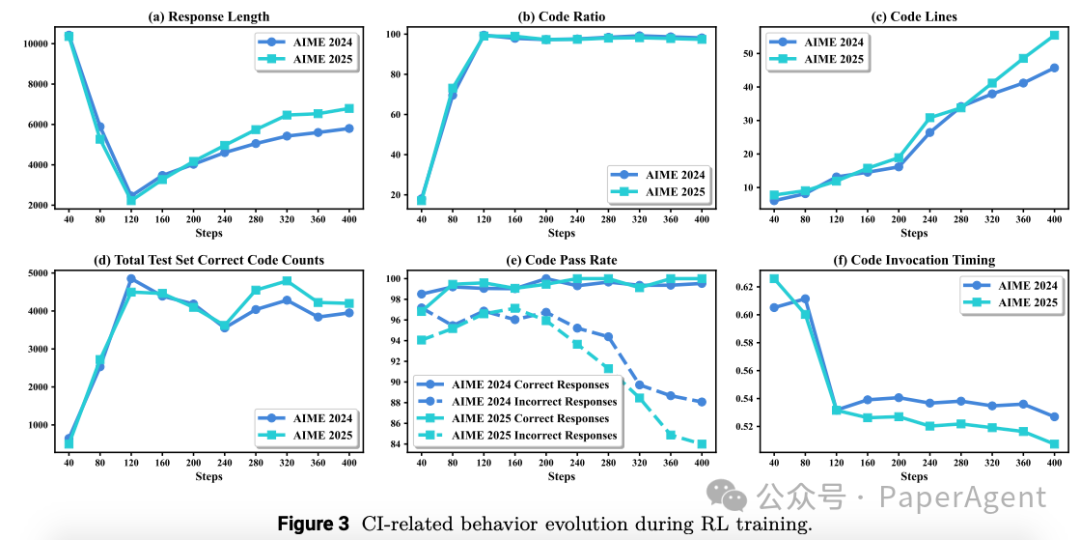
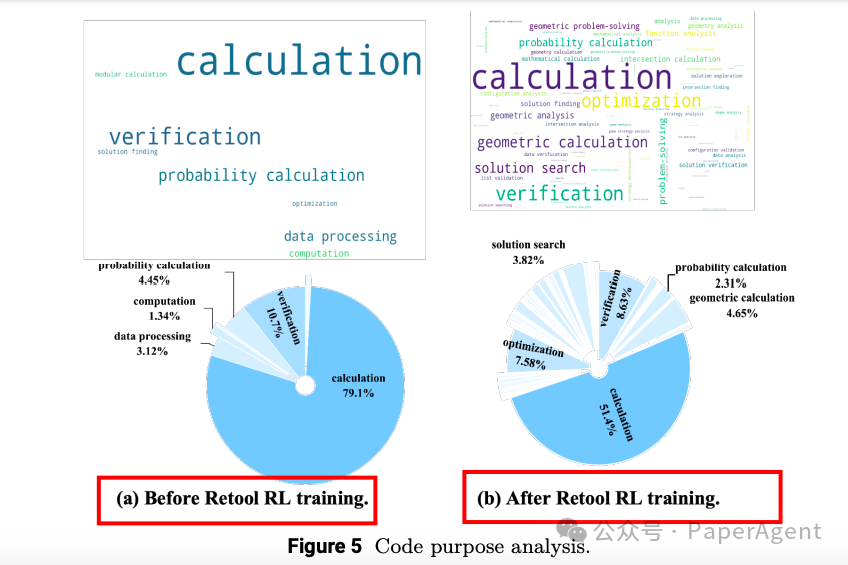
响应长度:经过RL训练后,模型的响应长度显著缩短,表明代码解释器(CI)增强了推理效率。 -
代码比率:模型生成的包含代码的响应比例在RL训练过程中逐渐增加,最终覆盖了几乎所有问题。 -
代码行数:模型生成的代码行数在训练过程中持续增加,表明模型学会了更复杂的代码策略。 -
正确代码数量:在测试集上,正确代码的数量在RL训练过程中持续增加。 -
代码调用时机:模型学会了在推理过程中更早地调用代码。 -
代码自我修正能力:模型在没有明确代码自我修正训练数据的情况下,展现出了自我修正非可执行代码的能力。

https://arxiv.org/pdf/2504.11536ReTool: Reinforcement Learning for Strategic Tool Use in LLMshttps://retool-rl.github.io/
(文:PaperAgent)