

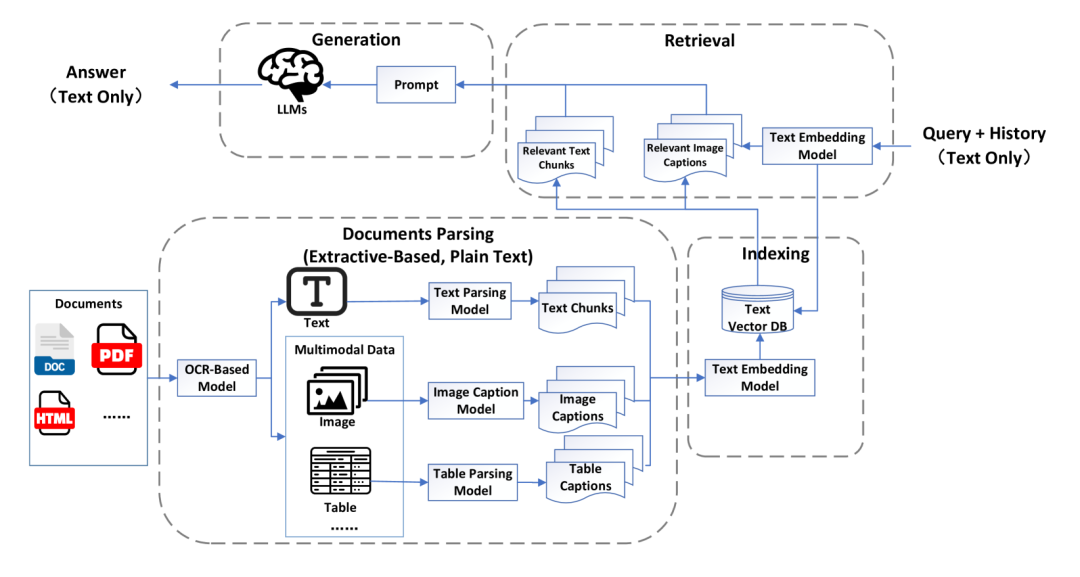
-
文档解析与索引:将多模态文档转换为文本和图像描述,存储在向量数据库中。 -
检索:使用嵌入模型检索与查询最相关的文本和图像描述。 -
生成:将检索到的信息与用户查询结合,生成回答。
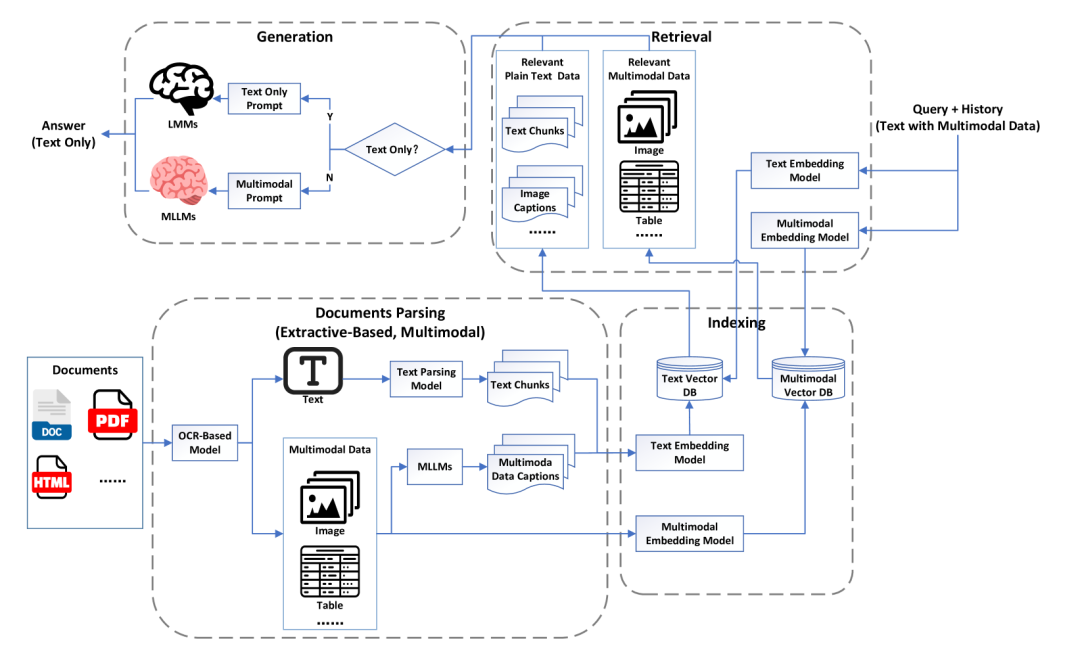
-
多模态检索:直接检索多模态数据,而不仅仅是文本描述。 -
多模态生成:利用多模态LLMs(MLLMs)生成答案,减少信息转换过程中的损失。

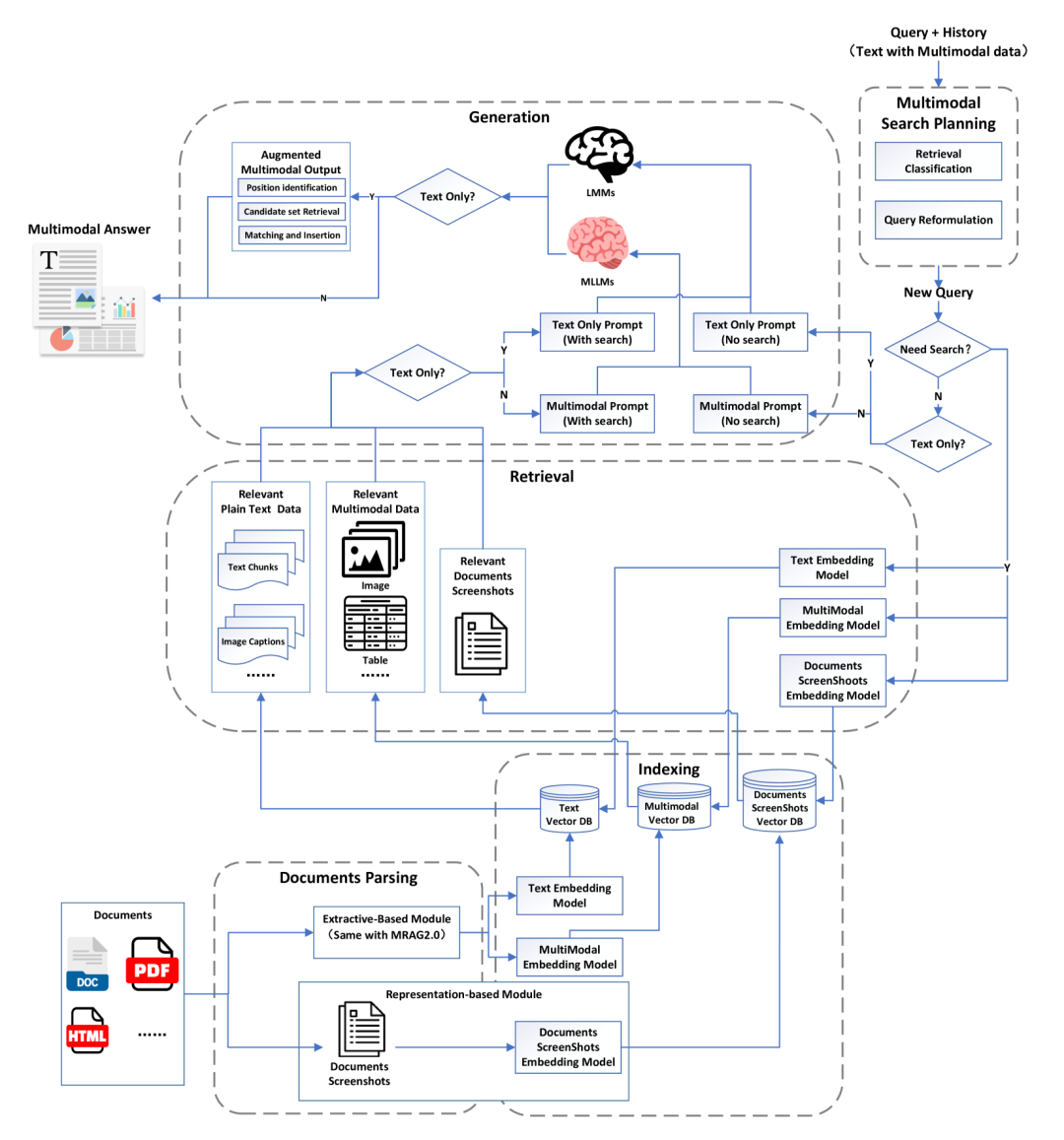
-
文档解析与索引:保留文档页面截图,减少信息丢失。 -
多模态检索增强型生成:在检索和生成过程中引入多模态数据,支持多模态输出。
-
多模态文档解析与索引
多模态文档解析与索引是MRAG系统的基础,负责处理和组织多模态知识库中的文档数据,以便后续的检索和生成模块能够高效利用这些数据。文档可以是结构化、半结构化或非结构化的,解析方法也因文档类型而异。
-
文档类型分类:
-
非结构化多模态数据:如包含文本、图像、视频和音频的文档,缺乏固定格式或模式。
-
半结构化多模态数据:如PDF、HTML、XML等,具有一定的组织结构,但不如关系数据库那样严格。
-
结构化多模态数据:如关系数据库和知识图谱,数据按照预定义的格式排列。
-
解析方法:
-
提取式方法(Extraction-based):从文档中提取多模态信息,然后进行解析和结构化存储。例如,使用OCR技术从图像中提取文本,或从HTML文档中提取结构化数据。
-
表示式方法(Representation-based):将整个文档作为一个整体进行处理,生成文档的表示,而不是显式地提取多模态信息。这种方法可以减少信息丢失,但可能需要更多的计算资源。
-
多模态搜索规划
多模态搜索规划模块负责根据用户查询制定检索策略,以确定如何从多模态知识库中检索相关信息。这一模块需要考虑查询的多模态特性,并动态调整检索策略以适应不同的查询需求。
-
固定规划(Fixed Planning):采用预定义的检索流程,不根据查询的具体内容进行调整。例如,始终使用文本检索或图像检索,而不考虑查询的实际需求。
-
自适应规划(Adaptive Planning):根据查询的特性和上下文动态调整检索策略。例如,对于需要多模态信息的查询,可以同时检索文本和图像,或者根据查询的复杂性调整检索的深度和广度。
-
多模态检索
多模态检索模块负责从大规模知识库中检索与用户查询最相关的多模态文档。检索模块需要处理不同模态数据之间的语义对齐问题,并生成高质量的检索结果。
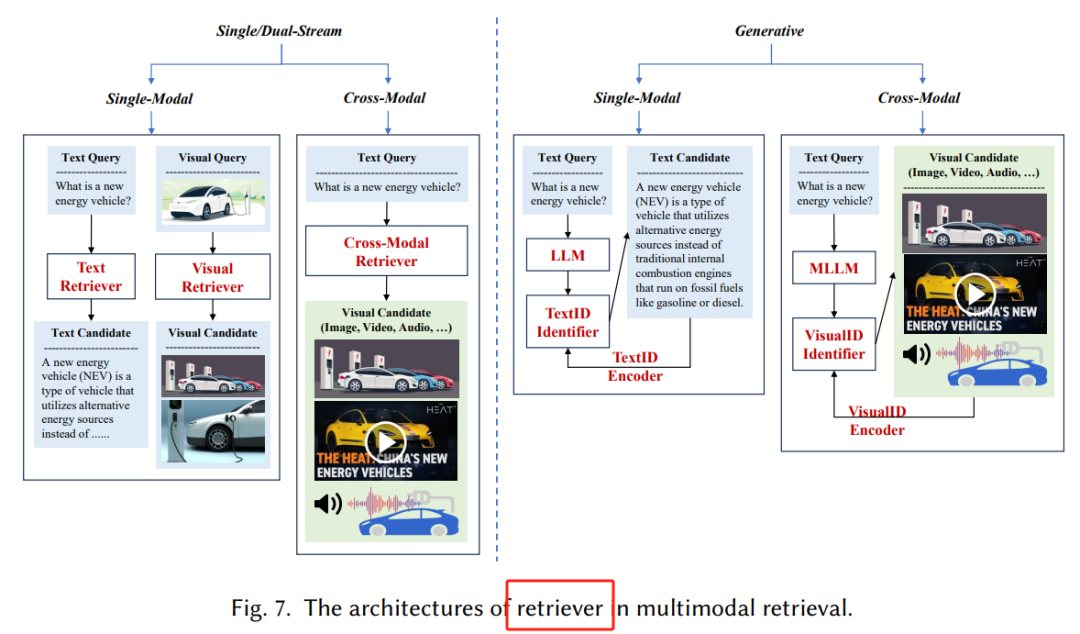
-
检索架构:
-
单/双流结构(Single/Dual-stream Structure):单流结构将多模态数据融合到一个统一的语义空间中,而双流结构则分别处理不同模态的数据,通过对比学习对齐特征。
-
生成式结构(Generative Structure):使用生成模型直接生成与查询相关的文档标识符(DocIDs),然后通过索引和检索这些标识符来获取相关文档。
-
检索方法:
-
稀疏检索(Sparse Retrieval):基于词袋模型或TF-IDF等技术,通过关键词匹配来检索文档。
-
密集检索(Dense Retrieval):使用深度学习模型生成文档和查询的密集向量表示,通过计算向量相似度来检索文档。

-
多模态生成
多模态生成模块负责根据检索到的多模态信息生成最终的答案。这一模块需要处理多模态输入,并生成包含多种模态数据的输出。
-
多模态输入(Multimodal Input):生成模块需要能够处理来自不同模态的输入,如文本、图像、视频等,并将这些输入融合到一个统一的表示中。
-
多模态输出(Multimodal Output):生成模块不仅需要生成文本答案,还需要能够生成与文本相关的图像、视频等多模态内容,以增强答案的表达力和信息量。

A Survey on Multimodal Retrieval-Augmented Generationhttps://arxiv.org/pdf/2504.08748
(文:PaperAgent)