


极市导读
本文系统梳理了大模型强化学习训练框架从SFT到RL的演进,重点剖析了rollout与训练模块解耦、资源调度、异步通信等核心技术挑战,并对比了OpenRLHF、slime、ROLL、verl等主流开源框架的优劣与适用场景。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
大模型RL框架的进化之路
2024年O1路线发现之前,主流的有监督的机器学习,是让学生去学习一个问题的标准答案,根据loss更新模型参数。
训练流程相对简单,pytorch和tensorflow基于此做了各种训练的加速。
chatgpt O1发布之后。
SFT不断弱化,更多的被丢到退火,RL的重要性越来越高。
RL算法也一直在更新,从dpo到ppo,再到现在的grpo/rloo/reinforce++/DAPO。除了现在基本上没人用的dpo,大框架是一致的。
如果说SFT是呆板的学习标准答案,那么RL是给定题目后,让学生自己寻找答案,给学生的解题打分,最后学生根据打分结果来学习。
所以,RL框架就分成了三大块,细节可以参看mengyuan的文章 – https://zhuanlan.zhihu.com/p/677607581
a) 学生自己寻找答案
就是大家天天说的rollout
b) 给学生答案打分
理论上给学生批改作业没那么容易,特别我们现在需要学生做的任务越来越难。但现在大家都在卷数学,物理,代码,这些方向根据结果+规则判断对错是可行的,也就是rule-based。
以及,大家发现训练一个小的reward 模型(例如7B)好像也能用。
导致学生找到答案后,判断答案的成本并不高。所以,这块不怎么被重视,甚至有人直接合并到rollout里了。
但随着agent出来后,特别开始设计到商业领域,例如我在做的电商领域,就没那么简单了。
c) 学生根据打分来学习
训练模块,基于传统的训练框架,改改loss function就行。
所以,现在的RL训练框架,整体分成两块,训练和rollout。那么问题就来了,假如你来设计这个rl框架,你会碰到这些挑战。
挑战一,rollout和训练两个模块的管理
RL现在的共识是on policy效果好,rollout和训练必须顺序执行。
但现在模型越来越大,多卡是必然的,如何管理资源?
rollout是内存消耗型,因为要做kv cache,特别现在cot越来越长了,训练则是计算密集型。
这俩现在都分别做了非常做的复杂的性能优化,如何对这两者做好资源管理?两者的参数同步如何优化?
挑战二,底层框架
训练框架有很多,megatron,fsdp,deepspeed,差异还不小。
推理引擎vllm和sglang,你用那个?
不同的训练框架搭配不同的推理引擎,仅仅是参数更新这块,逻辑代码都不一样。
挑战三,异步问题
rollout批次执行的,但同批次差异巨大,特别agent时代这个差异更是大的离谱。最近在做技术选型,带着团队的小朋友 @和光同尘 一起花时间把roll/slime/verl/openrlhf的源码框架都过了一轮。也跟它们的作者,roll的 @王小惟 Weixun,slime的 @朱小霖,verl的生广明,openrlhf的 @OpenLLMAI,进行了一轮/多轮的探讨,学习了很多知识,也收到了非常多有价值的反馈。
也感谢 @猛猿 ,有几轮讨论给了非常好的反馈。一轮轮的讨论中,会发现大家对三个挑战的解决,是一个循序渐进的过程。也感受到不同的作者会有自己的坚持和侧重。重点感谢这篇文章,对我帮助非常大
从零开始的verl框架解析: https://zhuanlan.zhihu.com/p/30876678559
性能的挑战
原始版本
我们回顾下三个阶段。学生自己寻找答案,在agent之前,就是模型推理。给学生答案打分,也是模型推理,只不过模型多几个(不同的算法量级不一样)。学生根据答案来学习,则是训练。
这个逻辑,基于sft框架是能搞的,只不过之前只用初始化一个模型,现在要初始化多个罢了。很多rl框架一开始都是这样。
但很快,我们会发现速度非常非常慢,那么问题来了,我们要如何优化它?
内存的优化
LLM训练-从显存占用分析到DeepSpeed ZeRO 三阶段解读:https://zhuanlan.zhihu.com/p/694880795
参考上面的文章。
训练过程中占用的显存有四种,模型训练参数,梯度占用,优化器占用,激活值占用。
梯度参数量和模型参数的规模是一一对应的,模型每一个参数都会有一个对应的梯度值来指导更新。
优化器占用则跟优化器的类型有关,这里按照adamw来计算。
拿7B模型来算内存,不考虑训练过程的中的激活值,模型参数14G,梯度14G,如果fp32,那就是28G,优化器28+28+28,一共都有112G。
现在的模型参数量,动不动千亿参数,单卡肯定放不下。为了解决这个方案,大家提出了DP/TP/PP来优化。
DP方式就是以deepspeed的zero1/2/3为主,每次计算前都会all gather得到完整的模型参数,计算的时候使用的是完整的参数和切分后的输入。
TP/PP从头到尾都只存模型的一部份,计算的时候使用的切分后的参数和完整的输入。这就是megatron擅长的,并且它的dp也做的很好。
详细区分参考如下表
英伟达有一篇论文,千卡以内差不多,千卡以外,TP/PP更好。
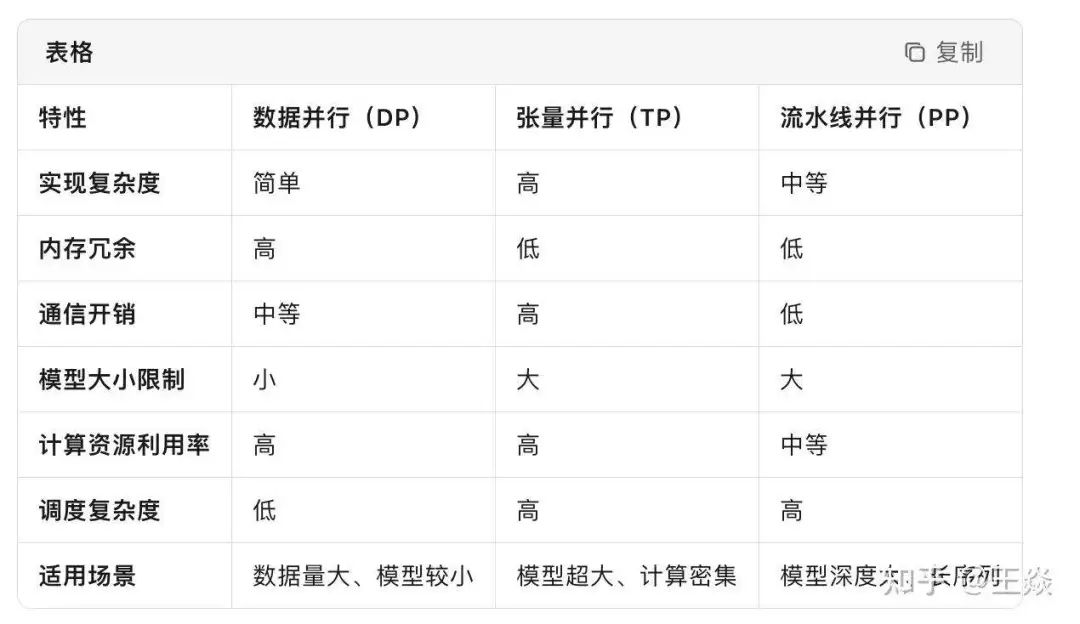
因为all gather的存在,理论上dp就是上限要比tp/pp差。
推理的速度
可以参考我的vllm,sglang,kv cache源码系列。现在的推理引擎,仅仅逻辑层kv cache的复用,就有非常多的点优化,更不用说底层算子的优化。
从零开始设计SGLang的KV Cache:https://zhuanlan.zhihu.com/p/31160183506
但使用推理引擎带来的问题就是,学生学习完毕后,需要把新的参数更新过去。但参数的更新耗时,对比于推理引擎提升的推理速度来看,百倍的提升,是完全可以接受的。
不过,现在推理引擎跟训练框架的generate的精度还是有差距,并且根据vllm和sglang的反馈来看,短期内依然比较难解决。
所以,现在rollout拿回来后,训练引擎还会再算一遍logits(相当于只有prefill,速度快的多)我们把训练框架和推理引擎拼接起来,做个新的rl框架,性能就有巨大的提升。
那么新的问题来了,如何拼接?
训练框架和推理引擎的拼接
SPMD和MPMD
SPMD(Single Program, Multiple Data),MPMD(Multiple Programs, Multiple Data),或者可以称之为single controller vs multi controller。
single controller,worker可以执行不同的程序(MPMD),需要一个老板来控制,不然就乱掉了。
multi controller,每个worker都执行相同的程序(SPMD),好处是不需要老板。但没有老板就代表各个worker在各种情况下,需要仔细考虑各种corner case,不然会乱跑。
DeepSpeed和Megatron等主流的训练框架都属于SPMD,所有进程执行相同的代码逻辑。
推理引擎(SGlang和vLLM)会很不一样。当他们执行计算的时候,是SPMD的,因为怎么计算是固定的。但next token从哪里来,如何计算,是kv cache,是从requset,还是pd分离,这就不适合用SPMD和MPMD做区分了。
广明建议看看google的pathway,再来讨论。(我理解的也很浅,就不展开了。我们抛开SPMD/MPMD,single controller/multi controller。训练框架和推理引擎之间最核心的是训练数据和模型参数的通信。我们带着疑问去看代码,看slime和roll是如何做的。
slime的做法
slime只定义了两个worker,RayTrainGroup 和RolloutGroup,训练框架和推理引擎。
https://github.com/THUDM/slime
数据的传输
slime单独定义了一个buffer类,专门用来做推理引擎和训练模块的数据传输中间件。数据都放到buffer里(甚至可以写入到磁盘),通过rollout id来指定。
并且buffer类的数据处理函数,rollout/eval function都是通过命令行参数指定,带来了极大的自由度。
self.generate_rollout = load_function(self.args.rollout_function_path)
self.eval_generate_rollout = load_function(self.args.eval_function_path)
这才是业务方真正的痛点,大家日常做业务,会有各种各样奇怪的需求和数据,这个地方如何改的爽很重要。rollout的generate函数是通过buffer。
def async_generate(self, rollout_id, evaluation=False):
return self.data_buffer.generate.remote(rollout_id, evaluation=evaluation)
训练框架获取数据,也是通过buffer。
def get_rollout_data(self, rollout_id):
# Fetch data through ray on CPU, not sure if this will be performance bottleneck.
# Both first pp stage and the last pp stage will recieve the data.
megatron_utils.process_rollout_data(rollout_id, self.args, self.data_buffer)
def process_rollout_data(rollout_id, args, data_buffer):
rank = dist.get_rank()
dp_rank = mpu.get_data_parallel_rank(with_context_parallel=False)
dp_size = mpu.get_data_parallel_world_size(with_context_parallel=False)
if rank == 0:
data = ray.get(data_buffer.get_data.remote(rollout_id))
dist.broadcast_object_list([data], src=0)
else:
data = [None]
dist.broadcast_object_list(data, src=0)
data = data[0]
使用的是同一个buffer,同步代码如下,把rollout的buffer同步给actor。
def async_init_weight_update_connections(self, rollout):
"""
Connect rollout engines and actors, e.g. initialize the process group between them
to update weights after each training stage.
"""
self.rollout = rollout
ray.get([actor.set_data_buffer.remote(rollout.data_buffer) for actor in self._actor_handlers])
模型的传输
把actor的配置传给rollout,让rollout引擎在需要的时候正确的同步参数。
def async_init_weight_update_connections(self, rollout):
"""
Connect rollout engines and actors, e.g. initialize the process group between them
to update weights after each training stage.
"""
self.rollout = rollout
ray.get([actor.set_data_buffer.remote(rollout.data_buffer) for actor in self._actor_handlers])
actor_parallel_configs = ray.get([actor.get_parallel_config.remote() for actor in self._actor_handlers])
parallel_config = {}
for rank, config in enumerate(actor_parallel_configs):
assert config["rank"] == rank and config["world_size"] == len(self._actor_handlers)
config.pop("rank")
for key, value in config.items():
if"size"in key and key:
if key not in parallel_config:
parallel_config[key] = value
else:
assert (
parallel_config[key] == value
), f"mismatch {key} on rank {rank}: {parallel_config[key]} != {value}"
parallel_config["actors"] = actor_parallel_configs
ray.get(rollout.async_set_parallel_config(parallel_config))
return [
actor.connect_rollout_engines.remote(
rollout.rollout_engines,
rollout.rollout_engine_lock,
)
for actor in self._actor_handlers
]
看到这里,我们发现好像纠结什么single controller,multi controller并不重要。这些逻辑直接硬编码,好像也能支持?问题在哪?
暂且不急,我们再看看roll。
roll的做法
roll通过cluster的方式,定义了多个角色。
self.actor_train: Any = Cluster(
name=self.pipeline_config.actor_train.name,
worker_cls=self.pipeline_config.actor_train.worker_cls,
resource_manager=self.resource_manager,
worker_config=self.pipeline_config.actor_train,
)
self.actor_infer: Any = Cluster(
name=self.pipeline_config.actor_infer.name,
worker_cls=self.pipeline_config.actor_infer.worker_cls,
resource_manager=self.resource_manager,
worker_config=self.pipeline_config.actor_infer,
)
self.reference: Any = Cluster(
name=self.pipeline_config.reference.name,
worker_cls=self.pipeline_config.reference.worker_cls,
resource_manager=self.resource_manager,
worker_config=self.pipeline_config.reference,
)
if self.pipeline_config.adv_estimator == "gae":
self.critic: Any = Cluster(
name=self.pipeline_config.critic.name,
worker_cls=self.pipeline_config.critic.worker_cls,
resource_manager=self.resource_manager,
worker_config=self.pipeline_config.critic,
)
分的比slime更细,好处是跟算法侧的认知比较一致,都是用cluster封装好了,毕竟算法是不知道训练框架和推理引擎有这么大的区别。
数据的传输
类似megatron,可以按照domain分开来采样,在pipeline.py文件定义好。 如果懒得写data generator,roll这个就很省心了。
重点讨论一下reward,理想情况下,我们肯定是期望有一个统一的reward模型,但现在统一的reward比较难训,并且看起来会持续很长一段时间。
我们退而求其次,不同的domain用不同的reward来打分,代码/数学/物理/写作等各一个,最后做聚合。
roll细化到,不同domain,不同batch,不同query上都可以做自定义配置。
https://github.com/alibaba/ROLL/blob/9b85e63ad4c715aa6602ba2a43657e25217c7732/examples/qwen2.5-7B-rlvr_megatron/rlvr_config.yaml#L176-L252
模型的传输
def model_update(self, tgt_workers, broadcast_tgt_devices, p2p_tgt_devices):
comm_plan = self.model_update_comm_plan[self.worker.rank_info.pp_rank]
model = self.unwrap_model()
broadcast_time_cost = 0
with Timer("model_update_total") as timer_total:
for param_name, param in tqdm(
model.named_parameters(), desc="weight update progress", total=len(list(model.named_parameters()))
):
shape = param.shape if not self.ds_config.is_zero3() else param.ds_shape
if not self.ds_config.is_zero3():
param_weight = param.data
refs = []
for p2p_tgt_device in p2p_tgt_devices:
p2p_tgt_worker = tgt_workers[p2p_tgt_device["rank"]]
ref = p2p_tgt_worker.update_parameter.remote(
parameter_name=param_name,
weight=param_weight,
ranks_in_worker=[p2p_tgt_device["device"]["rank"]],
)
refs.append(ref)
if (
self.worker.rank_info.tp_rank == 0
and self.worker.rank_info.cp_rank == 0
and self.worker.rank_info.dp_rank == 0
):
for worker in tgt_workers:
ref = worker.broadcast_parameter.remote(
src_pp_rank=self.worker.rank_info.pp_rank,
dtype=param_weight.dtype,
shape=shape,
parameter_name=param_name,
)
refs.append(ref)
if len(broadcast_tgt_devices) > 0:
collective.broadcast(tensor=param_weight, src_rank=0, group_name=comm_plan["group_name"])
ray.get(refs)
两种通信方式结合,会通过worker的node_rank和gpu_rank来判断是否在同一个设备上。
第一种,对于同一设备上的参数,直接通过点对点通信更新。
第二种,通过 collective communication 广播参数到目标集群,只在主进程(rank 0)执行广播操作。这两种就是colocate和非colocate的差异,下文会说到。
从roll来看,这些逻辑直接硬编码,也是能支持,特别当如果在同一个机器上的话。
从slime和roll来看,参数同步,其实只是controller告诉GPU要做参数同步了,中间的通信是不走controller的。
而如果是rolleout的通信,这个single controller压力是非常小的,多模态会大一些?不确定。从这个角度来看,SPMD和MPMD不重要。
但我们刚刚的讨论,都是如果这些role在同一个机器上,硬编码会很简单?
那么如果不在同一个机器会怎么样?
colocate和ray
把actor/ref/reward/critic模型都放一张卡上就是colocate。 但正如上文所说,7B模型训练单卡都塞不下,1000B的模型下半年预计也会开源好几个,并行带来的开销是很夸张的。 现在reward模型也普遍不大,7-30B就满足要求,模型size也有差异,分开部署性价比更高。
但分开部署的硬编码就相对麻烦了,于是大家引入了ray。 ray能支持更加复杂的分布式计算的框架,不用我们过多的操心底层逻辑。如下两篇文章写的已经非常好了,这里不做赘述。 图解OpenRLHF中基于Ray的分布式训练流程:https://zhuanlan.zhihu.com/p/12871616401 Ray分布式计算框架详解:https://zhuanlan.zhihu.com/p/460600694
我们对比下slime/verl/roll/openrlhf四个框架的colocate和非colocate实现。
slime
只有俩worker,训练和推理,RayTrainGroup 和RolloutGroup
colocate是训练和推理分开部署,那么非colocate的情况下,只需要处理分布式通信来同步参数。
这种拆分,抽象易于理解,跟上文讨论的训练和推理是一致的。
只需要在训练的时参数配置colocate,就会自动在所有重要环节执行。
roll
非colocate的话,roll支持各种细粒度的worker指定在不同的显卡的部署,并且还能按轮次去配置,如果不指定的话,ray也会自动帮你部署。
RL资源消耗这么大,细粒度的显卡配置,更有助于显卡资源的高效利用,但对算法侧的资源调度能力要求也更高了。
很明显,这个逻辑用ray来管理更合适。
verl
ActorRolloutRefWorker这个类设计的有点问题,已经在改了。
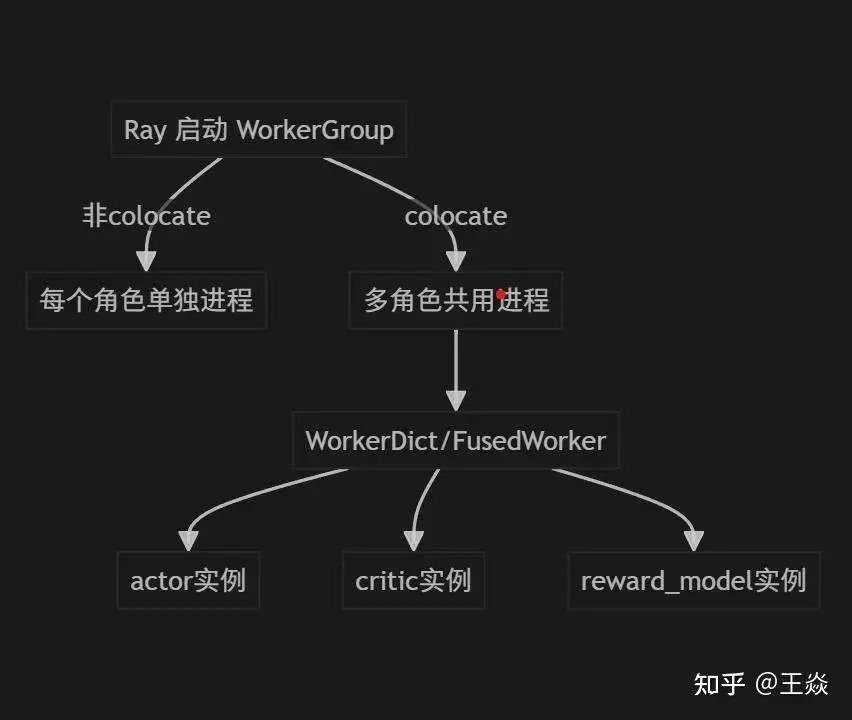
非colocate就是每个worker(actor,crtic,reward等)一个进程,靠ray自行调度。
colocate,多个角色共用一个ray actor实例,同一个进程内实例化多个worker类。
通过 create_colocated_worker_cls 或 create_colocated_worker_cls_fused 动态生成一个“多角色”类(如 WorkerDict/FusedWorker),内部持有多个 Worker 实例。
外部通过统一的接口调度不同角色的 Worker 方法,内部自动分发到对应的 Worker 实例。
# deprecated, switching to FusedWorker
def create_colocated_worker_cls(class_dict: dict[str, RayClassWithInitArgs]):
"""
This function should return a class instance that delegates the calls to every
cls in cls_dict
"""
cls_dict = {}
init_args_dict = {}
worker_cls = _determine_fsdp_megatron_base_class([cls.cls.__ray_actor_class__.__mro__ for cls in class_dict.values()])
assert issubclass(worker_cls, Worker), f"worker_cls {worker_cls} should be a subclass of Worker"
print(f"colocated worker base class {worker_cls}")
for key, cls in class_dict.items():
cls_dict[key] = cls.cls
init_args_dict[key] = {"args": cls.args, "kwargs": cls.kwargs}
assert cls_dict.keys() == init_args_dict.keys()
# TODO: create a class with customizable name
class WorkerDict(worker_cls):
def __init__(self):
super().__init__()
self.worker_dict = {}
for key, user_defined_cls in cls_dict.items():
user_defined_cls = _unwrap_ray_remote(user_defined_cls)
# directly instantiate the class without remote
# in worker class, e.g. <verl.single_controller.base.worker.Worker>
# when DISABLE_WORKER_INIT == 1 it will return immediately
with patch.dict(os.environ, {"DISABLE_WORKER_INIT": "1"}):
self.worker_dict[key] = user_defined_cls(*init_args_dict[key].get("args", ()), **init_args_dict[key].get("kwargs", {}))
跟别的框架不一样的点,同进程和非同进程。根据verl的反馈,同进程收益是非常大的。
同进程通信的话,在某些场景下,速度会差十几倍,memory的碎片问题之类的也会造成很大的影响。
openrlhf
Openrlhf支持多种混合部署方式,允许共置 vLLM 引擎、Actor、Reference、Reward 和 Critic 模型节点或是部分混合部署。支持任意方式的混合部署 也支持分开部署异步训练。
汇总下来,非colocate情况下,ray的确能帮我们更省心的做资源管理,更不用说复杂的agent和多轮。 不过根据运维侧的反馈,ray设计跟现在prod k8s云原生体系比较违背,落地到prod,管理成本比较高。 但ray反馈他们也在针对性优化了,例如,ray现在tensor可以直接走nccl了 bypass object store,也可以期待下他们后续的更新。
不同的训练框架和推理引擎的连接也不同
举个例子,假如vLLM的TP是4,而deepspeed分在了8个GPU,那么就需要做参数的转换才能传输,megatron也类似。
如果训练框架有俩,推理引擎有俩,那么要适配的不是两种,而是四种方案。
某位不愿意透露姓名的朋友,曾被这样的bug坑过,导致他们一直以为百张卡内megatron没有fsdp快,并且持续了很长一段时间。
代码的解耦
拿slime来举例子。 推理引擎分成三层了,顶层-RolloutGroup,中层-RolloutRayActor,底层-SglangEngine。
顶层的 RolloutGroup 是一个总控器,负责启动推理引擎,分配资源,管理数据。在 RolloutRayActor 中可以看到各个接口都很精简,因为具体的实现都放在了 backends 中的相关 utils 里。因为推理本身并不复杂,所以在 sglang_engine 中各个功能也通过调用接口实现。假如有一天我发现sglang不行了,那么我改底层就可以了,上层是感受不到的。 训练框架也是分了三层,看 TrainRayActor 可以更直观的感受到解耦程度。对于最复杂的 train 方法,涉及到 ref,actor,rollout,包含了logprob的计算,日志的记录等,但是因为各种功能被写在了 megatron_utils 中,所以并不会显得很复杂。而在 megatron_utils 中,就可以看到 forward,train 等的详细实现。当需要替换 backend 的时候,在 backend 中新增一个 utils 并确保 train,forward 等接口的实现就可以实现 backend 的切换。 现在各大框架基本上都是这么设计了。 还有一些模块,loss function,打分模块,相对比较简单,就不展开了。
关于Agentic RL
roll,verl,openrlhf都有了不错的支持。 roll甚至单独定义了agentic_pipeline.py来方便大家做进一步的自定义,虽然这样会导致代码的逻辑复杂度增加。但weixun反馈,后续等agentic RL稳定下来后,会重新做一版梳理。weixun16年就开始做RL,经验非常丰富,大家可以多去反馈。 个人认为,未来应该只有agentic RL,现有的rlvr只是其中的一个组成模块。
但这块我还不打算展开,特别现在的agent框架问题更大。
自主agent+沙盒+workflow的混合,agent+rl如何有效的扩大自主agent的范围和边界,等一系列问题,现在并没有一个开源框架能做有效支撑。 太多的不确定,我的下一篇文章会重点展开讨论。
用哪个RL框架?
框架的难点
如果技术进化速度很快,老的框架往往很快就会被大家遗忘,这的确比较令人尴尬。 agent方向也是如此,langchain2023年有多火,现在呢?用dify的更多吧。 原因很简单,老的框架历史包袱太重。 一边清理老功能,一边加新功能,同时如何保证代码框架的简洁和高维护性,是非常考验框架负责人的。
拿dify举例,它为了把rag,chat,workflow,自主agent都塞到一起,代码的臃肿程度看的非常痛苦。 很多老用户可能的确还在用rag功能。但讲道理,dify里面的rag都是开源的模型和方案。干脆丢掉,让用户调用优质的rag接口/mcp,毕竟rag只是agent未来无数tools中的一个重要模块。
新框架设计者,没有这些包袱,弯道超车就会很容易。 再提一嘴,SFT时代很火的训练框架,现在大家还有谁在用?特别现在RL框架顺路就可以把SFT给做了。
而随着模型不断变大,现在其实就俩选择,彻底自己写一套框架,或者基于megatron做定义。 前者对团队要求高,后者则是要忍megatron。
用哪个?
现在的RL框架,各有各的优点,大家按需自取即可。
a] OpenRLHF
OpenRLHF 是第一个基于 Ray、vLLM、ZeRO-3 和 HuggingFace Transformers 构建的易于使用、高性能的开源 RLHF 框架,旨在使 RLHF 训练变得简单易行。
很多人发论文都用它。
https://github.com/OpenRLHF/OpenRLHF
b] slime
刚出没有历史包袱,轻装上阵,代码是真的简洁且清晰,有我当年看完vLLM再去看SGlang的快感。
zilin本身算法认知也很到位,经常跟我们探讨算法细节,对算法侧的痛点是很懂的。例如buffer对数据的处理,很明显就是理解算法侧天天洗数据的痛。
大规模训练上,在zhipu也经过了验证。
大家想要去做一些大胆的框架魔改尝试,slime非常值得一试。
https://github.com/THUDM/slime
c] ROLL
数据处理做的蛮精细,分domain采样,训练和评估的异步都做好了。
agentic和异步是支持的比较完善,weixun从16年就开始做RL,经验非常丰富,ROLL也在这个方向投入了很大的精力去优化。
agentic一直在更新,下周估计还会放新feature。
各种角色的显卡配置指定也可以实现非常细致的调配,支持算法做精细化的算法性能调优。agentic RL这块如果你想要深入折腾的话,可以试试。
https://github.com/alibaba/ROLL
d] verl
据我所知,很多大厂都在用这个,在大规模服务上,它跑起来就是稳且靠谱。
以及,在大规模集群的显卡性能优化上,是有过非常多的踩坑经验。
agentic和异步也做了很多的优化和探索,对deepseek v3的支持也很好。
如果你的团队卡多,时间排期紧张,想要快速scale起来,用这个就好了,很多大厂团队已经帮你验证过。
https://github.com/volcengine/verl
至于aReal的异步,我自己都没想清楚,估计年底会再写一些篇做个专门探讨。
写在最后
最近半年,把RL训练框架,agent框架,推理引擎框架都过了一轮。 代码量,agent > 推理引擎> rl训练框架。 代码难度,推理引擎>rl训练框架>agent。 但如果把推理引擎的底层算子抛开,RL训练的框架难度是跟推理引擎持平的。因为RL训练框架的难点在于缝合,很考验框架作者对各种系统,业务的理解。
verl/slime/roll/openRLHF,这几个开源框架各有所长,能看到不少作者都有自己的追求和坚持,社区的积极性又很高。我觉得大家可以很自豪的说,我们中国在开源的RL框架方向,技术和认知,就是世界第一。算法上人才差异也没那么大,差的大概就是显卡。
大家还是要有一些家国情怀和自信,而不是单纯copy硅谷to china。不是说,谁离openai/claude近一些,更早的获取一些模型训练上的小道信息,谁就迭代的更快。 接下来谁能基于国产卡,训练出来第一个真好用的1T模型。谁就能站在主席台上领奖了,China AI number one 也就不远了。 2023年我清了腾讯股票,梭哈了英伟达和微软。我还是蛮期待明年能有这么一个大新闻,可以让英伟达的股价大大的波动一下,给世界展示下中国制造的实力。
(文:极市干货)