


极市导读
本文提出了一种名为 DC‑AR 的掩码自回归(Masked Autoregressive,AR)文本到图像生成框架,核心在于引入深度压缩混合 Tokenizer(DC‑HT),实现高达 32 倍的空间压缩同时保持重建质量与跨分辨率泛化能力。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 DC-AR:32 倍下采样轻量级混合 tokenizer
(来自 NVIDIA,韩松团队)
1.1 DC-AR 研究背景
1.2 32 倍空间压缩比的混合 tokenizer
1.3 三阶段训练策略
1.4 基于 DC-HT 的自回归文生图模型 DC-AR
1.5 实验结果
太长不看版
32 倍超高空间压缩率,专为 AR 模型设计的 tokenizer。
本文提出的方法叫做 DC-AR,是一种 Masked Autoregressive (AR) 文生图模型。本文觉得 Masked Autoregressive 模型落后于 Diffusion Model 的一个重要的原因是 tokenizer。本文于是提出了一种专门为 AR 模型设计的深度压缩混合 tokenizer 叫做 DC-HT,可以在实现 32× 的空间压缩率的同时,维持高水平重建性能和跨分辨率的生成能力。
基于 DC-HT,作者对 MaskGIT 进行了拓展,提出了一种新的混合 Masked Autoregressive 图像生成框架。DC-AR 在 MJHQ-30K 上达到了 5.49 的 gFID 以及总分 0.69 的 GenEval 结果。与之前的扩散和自回归模型相比,吞吐量提高了 1.5-7.9 倍,延迟降低了 2.0-3.5 倍。

1 DC-AR:32 倍下采样轻量级混合 tokenizer
论文名称:DC-AR: Efficient Masked Autoregressive Image Generation with Deep Compression Hybrid Tokenizer (ICCV 2025)
论文地址:
https://arxiv.org/pdf/2507.04947
项目主页:
https://hanlab.mit.edu/projects/dc-ar
1.1 DC-AR 研究背景
与扩散模型相比,自回归模型使用 Visual Tokenizer 通过矢量量化 (Vector Quantization) 将图像从像素空间转换为离散 token。然后,该模型可以类似于文本 token 的做法,处理这些视觉 token。
Masked Autoregressive Model 是一种受 NLP 领域 BERT 启发的方法,这些模型在逐渐去掉 mask 的过程中生成 image token 序列。与 GPT-like 的 next token prediction 的预测范式不同,Masked Autoregressive 模型允许在每一步同时生成多个 token,显著地减少了采样的步骤数,提高了生成效率。而且,这种 masking 和 unmasking 的做法使得它们天然适合图像编辑任务。
但是,与利用连续 token 来表示图像的 Diffusion Model 相比,AR 模型在从图像 tokenization 过程中面临着重大挑战。目前的 image tokenization 标准实践采用空间缩减比为 8× 或 16× 的 Autoencoder,其中大小为 256×256 的图像分别转换为 32×32 或 16×16 的 token。但是,进一步降低 token 数以提高效率仍然至关重要,尤其是考虑到生成高分辨率图像时的计算成本会增加。
虽然 DC-AE[1]已经成功地实现了连续 tokenizer 的高空间压缩比 (32 倍),但构建一个可用于 Masked Autoregressive 模型的高压缩 tokenizer 仍然没有成功的实践。本文实验发现直接将 DC-AE 应用于离散 tokenizer 会导致糟糕的重建质量。
本文提出的 DC-AR 是一种文生图的高效 Masked Autoregressive Model。DC-AR 结合了 DC-HT,一种 Single-scale 的 2D tokenizer,可实现 32 倍的空间缩减率,同时通过 Hybrid Tokenization 保持具有竞争力的重建质量。Hybrid Tokenization 最初由 HART[2]提出,是一种旨在弥合离散和连续 tokenizer 之间的性能差距的技术。但是,与采用压缩比为 16× 的 Multi-scale tokenizer 的 HART 不同,使用传统方法训练具有 32× 压缩比的 Single-scale tokenizer 通常会导致重建质量次优。
本文提出了一种三阶段训练策略,来优化 tokenizer。这个策略使得 DC-HT 能够实现与 1D Compact tokenizer 相同的压缩级别,同时能够跨分辨率进行泛化。基于这个 tokenizer,本文继续提出基于 MaskGIT 的文生图模型 DC-AR。使用离散 token 的 Cross-entropy Loss 以及连续 token 的 Diffusion Loss 来训练模型。在推理时,DC-AR 首先通过 unmasking 过程生成离散 token,然后通过轻量级的 Diffusion head 生成 Residual token。然后把这些 token 混合之后,再经过 de-tokenizer 得到最终的输出图像。
1.2 32 倍空间压缩比的混合 tokenizer
深度压缩混合 tokenizer (Deep Compression Hybrid Tokenizer, DC-HT) 是一种用于自回归生成的 2D tokenizer,实现了 32 倍空间压缩比。
DC-HT 采用 2D 离散 tokenizer 的设计,包括:
-
基于 CNN 的 Encoder:Enc -
基于 CNN 的 Decoder:Dec -
Vector-quantized(VQ)的 Quantizer:Quant
DC-HT 采用与 DC-AE[1]相同的架构。作者发现离散 tokenization 在码本训练过程中高度敏感。在很高的空间压缩比下,作者观察到直接训练 2D 离散 tokenizer 导致重建质量很差。因此,作者建议使用混合 tokenization 和三阶段学习策略,以减轻质量损失。
混合 tokenization
给定输入图像 \mathbf{I} ,重建过程可以通过离散的方式或者连续的方式进行。
给定输入图像 I,重建过程可以通过离散的方式或者连续的方式进行。 对于离散方式,首先将输入图像 由 CNN Encoder 压缩为连续 token 的 latent 表征 ,然后进行 VQ 过程 得到离散 token。然后将离散 token 通过CNN Decoder 重建图像 。计算 和 之间的 Reconstruction Loss 和 GAN Loss 来训练 tokenizer。
对于连续方式,VQ 过程省了。连续的 latent 表征 直接输入到 CNN Decoder Dec 中,得到重建图像 。
根据 HART,混合 tokenizer 成功生成的一个关键特性是它能够有效解码连续 token 和离散 token 。它确保从 Decoder 的角度来看,这两种类型的 token 足够相似,这有助于在生成过程中更容易建模它们的 Residual token,定义为 。
1.3 三阶段训练策略
仅混合 tokenization 不能完全解决重建质量下降的问题,因为离散潜在空间和连续潜在空间之间本就存在内在冲突。
作者提出了一种三阶段的训练策略来应对这一挑战。详细的训练 Pipeline 如图 2 所示。
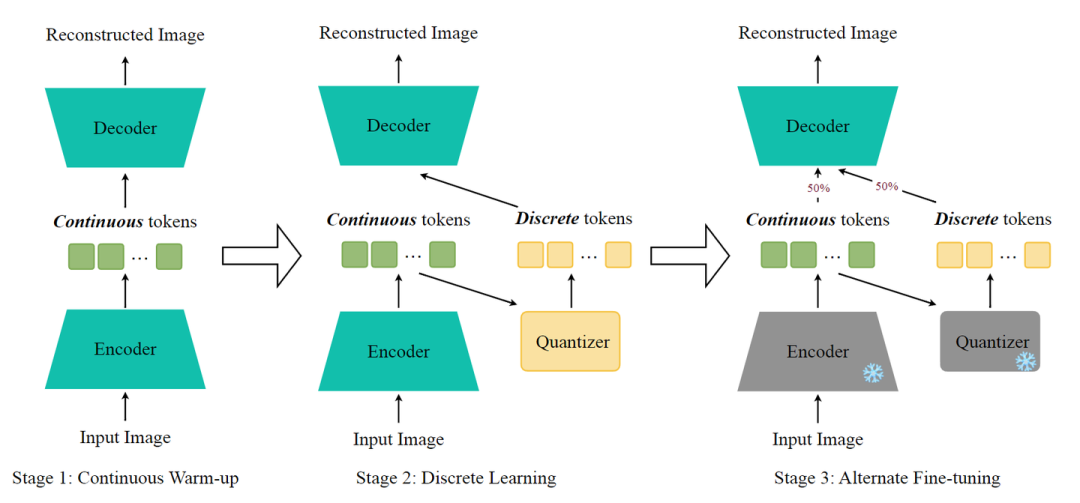
第一阶段:Continuous Warm-up
仅关注连续路径。这一阶段相对较短,旨在用适合重建任务的权重初始化 Encoder。
第二阶段:Discrete Learning
只激活离散路径。目标是训练 tokenizer 来学习稳定的 latent space,并使其能够有效地重建图像。
第三阶段:Alternate Fine-tuning
对每个图像,以相等概率 (50%) 随机选择连续路径或离散路径来微调 tokenizer。这个阶段中,Encoder 和 Quantizer 被冻结,只微调 Decoder。这一阶段确保 Decoder 可以有效地处理连续 token 和离散 token。
这个三阶段训练策略,将 rFID 从 1.92 提高到了 1.60,将 discrete-rFID (离散路径的 rFID) 从 6.18 提高到了 5.13。
1.4 基于 DC-HT 的自回归文生图模型 DC-AR
为了充分利用 DC-HT 的能力,作者构建了 DC-AR,一种 Mased Autoregressive Model,可以在文本引导下生成高分辨率图像,如图 3 所示。
文本模型从输入 Prompt 中提取文本 Embedding,然后通过 Cross-attention 将其集成到 Transformer 中,以提供文本指导。
DC-AR 训练过程: 如图 3 所示,随机 mask 掉一些离散 token,训练 Transformer 模型使用 Cross-entropy Loss 预测这些 masked token。同时,Transformer 产生的隐藏状态作为 Condition 输入,通过轻量级 Diffusion Head (MLP) 预测 Residual token,使用 Diffusion Loss[3]进行优化。
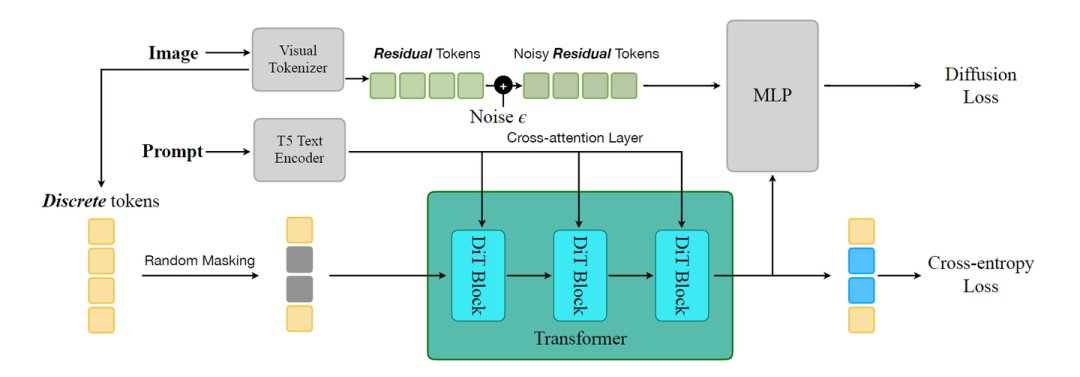
DC-AR 推理过程: 如图 4 所示,是 DC-AR 推理过程。
一开始所有离散 token 都是被 mask 掉的。然后通过一个逐渐 unmasking 的过程,递归地预测离散 token。一旦生成了所有的离散 token,Transformer 最后的隐藏状态就被拿来作为 Diffusion Head 的 Condition。然后,通过一个去噪的过程来预测 Residual token。
然后,把离散 token 和 Residual token 加在一起得到连续 token,通过 Decoder 生成最终的输出图片。
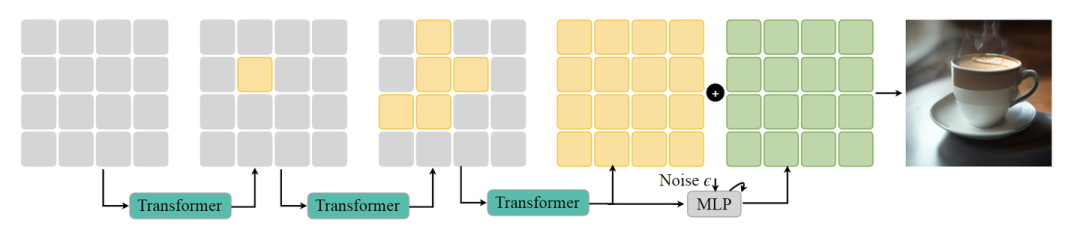
DC-AR 的一个关键设计是,Transformer 模型的前向过程中只涉及离散 token。这种方法是基于这样一个原则,即:Residual token 应该作为一种 Refining function,而不改变生成图像的整体结构。
这种设计至关重要,因为 MaskGIT[4]表明,基于离散 token 的 MaskGIT 通常需要 8 步能达到接近最优的生成性能。相比之下,基于连续 token 的 MAR[3]需要 64 步才能达到最佳性能,导致推理成本明显更高。
通过 Transformer 预测离散 token 以及 Residual token 的 Refinement,DC-AR 方法保持了离散 token 方法的高的采样效率,同时获得了更好的图像生成质量。
2D tokenizer 设计相对于 1D tokenizer 的一个关键优势是能够在不同分辨率下具有泛化性。
利用这一特性,作者采用两阶段训练策略来高效地训练 512×512 图像的图像生成模型。首先,使用相对较长的训练计划,在 256×256 图像上预训练模型。然后,在 512×512 图像上对预训练的 256×256 模型进行微调,得到最终的模型,由于共享的 latent space,收敛速度很快。
1.5 实验结果
模型
Tokenizer 采用了 DC-AE-f32c32 架构,空间压缩比为 32×,latent channel 为 32。作者将 Codebook 配置为 。对于生成器,利用 PixArt-α 架构的 Transformer 模型,去掉了其 adaptive norm 层。它由 28 层组成,宽度为 1152,相当于 634M 参数。扩散头包含 6 个 MLP 层,总共 37M 参数。使用 T5-base 作为我们的文本编码器,包含 109M 参数。
效率分析
作者在 NVIDIA A100 GPU 上分析了延迟和吞吐量。作者以 16 的 Batch Size 来测吞吐量,以 1 的 Batch Size 来测时延。在所有情况下都使用 Float16 精度。
Image Tokenization 结果
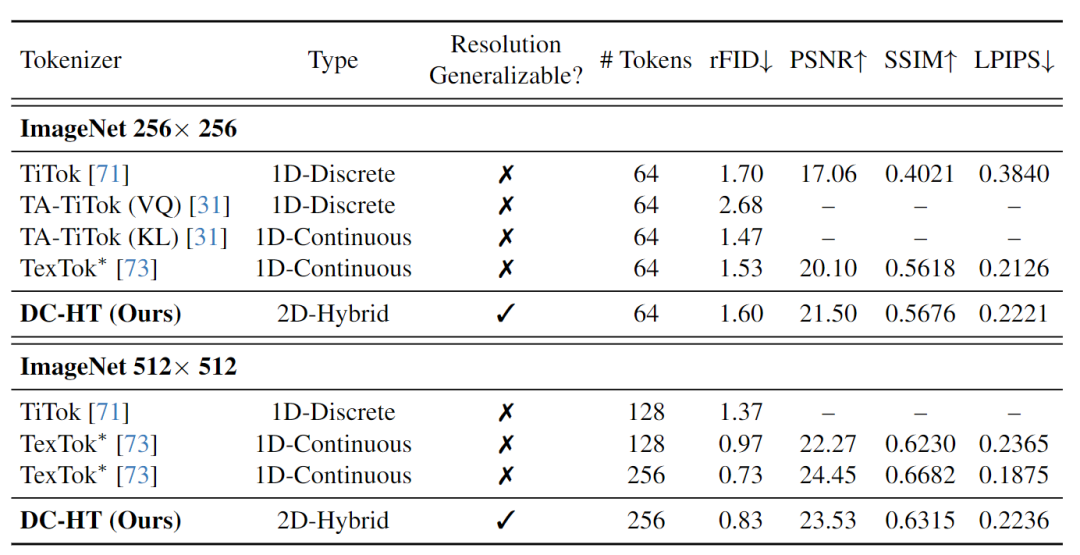
如图 5 所示,DC-HT 在保持高压缩比的同时实现了与 1D compact tokenizer 相当的重建性能。值得注意的是,DC-HT 仅在 256×256 图像上进行训练,但在 512×512 分辨率下提供了具有竞争力的性能,而 1D tokenizer 的模型需要在 256×256 和 512×512 图像上单独训练。
这个优势是来自 DC-HT 拥有 2D tokenizer 固有的,对于分辨率的泛化性。而这恰恰是 1D tokenizer 不具备的。
文生图结果
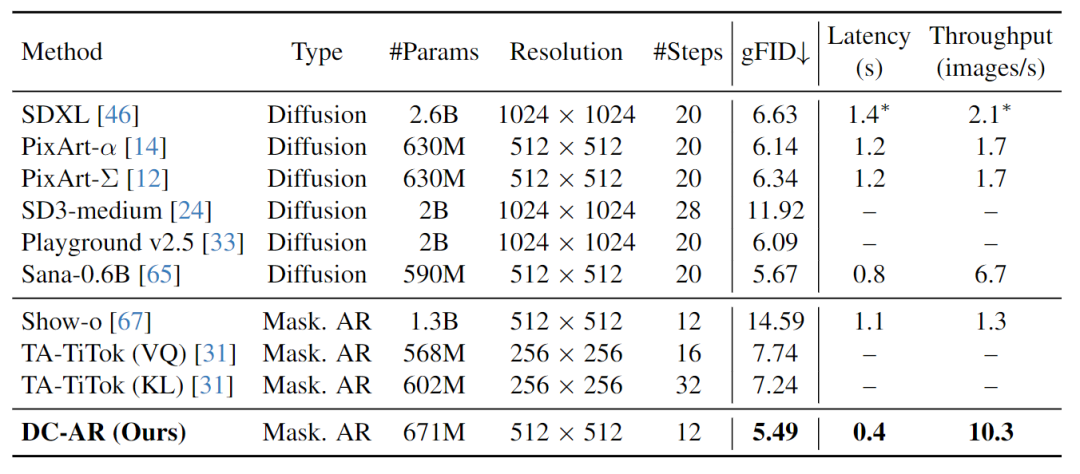
图 6 和 7 为定量文生图结果。在 MJHQ-30K Benchmark 上,与领先的 Diffusion Model 和其他 Masked Autoregressive Model 相比,DC-AR 达到了 5.49 的 gFID。值得注意的是,DC-AR 显著降低了推理成本,只需要 12 步。
对于 512×512 图像生成,DC-AR 的时延分别比 Sana-0.6B 和 SD-XL 低 2.0 倍和 3.5 倍,吞吐量分别比 Sana-0.6B 和 Show-o 高 1.5 倍和 7.9 倍。
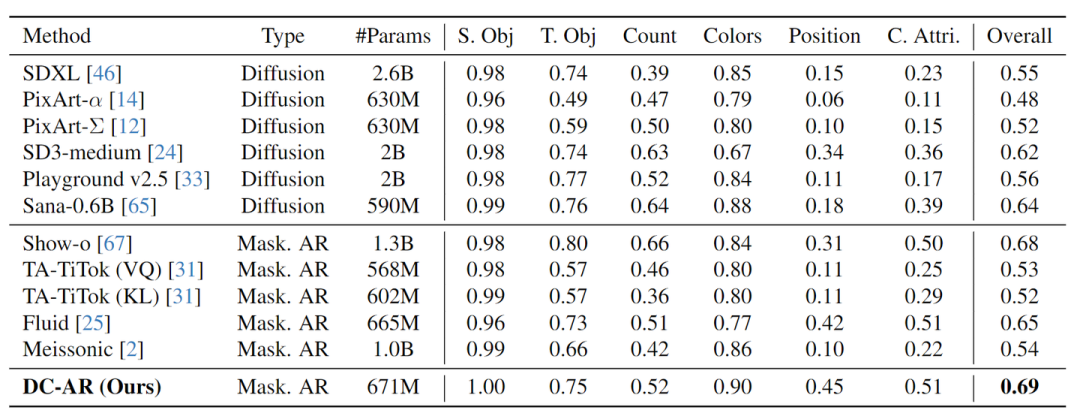
在 GenEval Benchmark 测试中,DC-AR 的总体得分为 0.69,对标了最先进的掩码自回归模型 Show-o,而规模小 2 倍。此外,DC-AR 的性能优于其他类似尺度的模型至少 0.04。
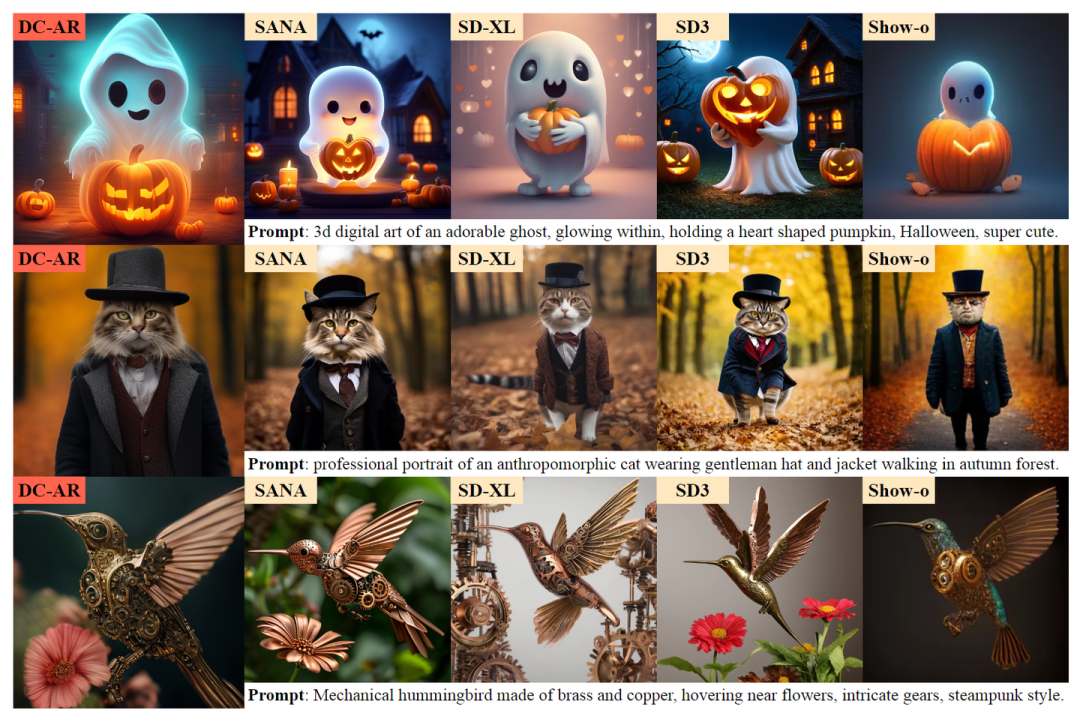
此外,作者在图 8 中提供了将 DC-AR 的生成结果与其他高级模型进行比较的定性样本。
推理效率优势
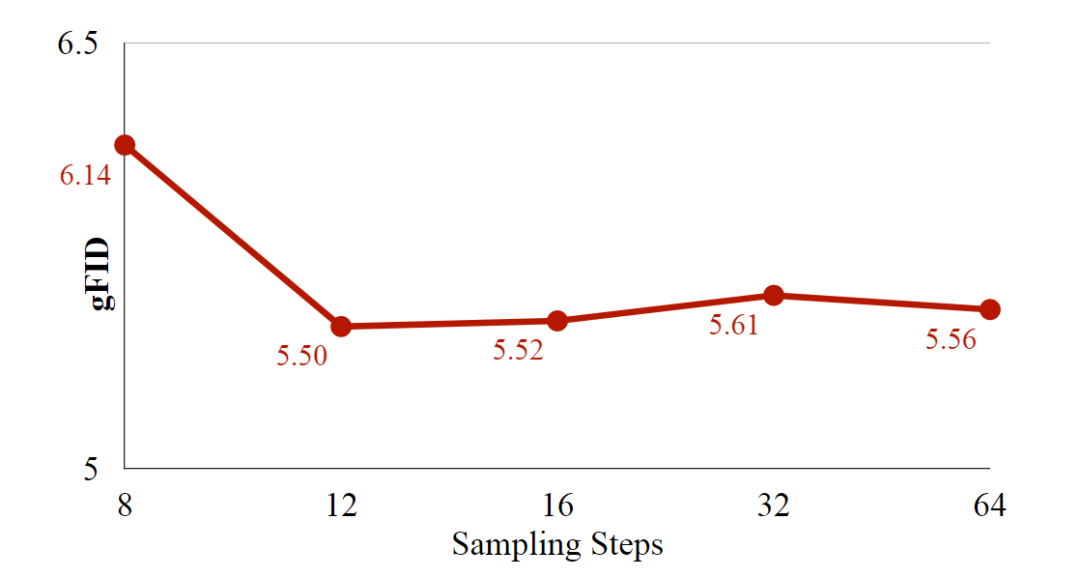
图 9 展示了 DC-AR 在不同采样步骤下的 gFID 结果。本文的离散令牌主导生成策略使得 DC-AR 能够以 12 个采样步骤实现最优图像质量。相比之下,基于 MAR 的模型需要大量步骤才能达到最佳性能。这种对采样步骤的需求减少,为 DC-AR 带来了巨大的效率优势,同时也不会损害生成质量。
参考
-
Deep compression autoencoder for efficient high-resolution diffusion models -
Hart: Efficient visual generation with hybrid autoregressive transformer -
Autoregressive image generation without vector quantization -
Maskgit: Masked generative image transformer
(文:极市干货)