

Claude 3.7硬控马里奥90秒,GPT-4o开局暴毙!Karpathy直呼基准失效,游戏成LLM新战场

加州大学圣迭戈分校Hao AI Lab用超级马里奥等游戏评估AI智能体,Claude 3.7表现亮眼。谷歌的Gemini也进行了测试。对比结果显示GPT-4o和GPT-4.5在多种游戏中都明显逊色。
AI三小时做的小游戏,9天赚12万!马斯克:AI游戏前景无限
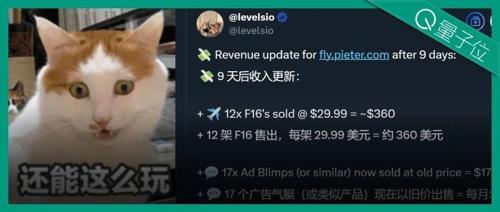
一个人用3小时靠AI开发的游戏《飞行模拟器》9天赚12.64万。游戏通过广告模式盈利,每售出一个F16飞机和多个广告汽艇等产品每月收入约17360美元。开发者Pieter Levels通过不断尝试成功闯出自己的天地,并分享了自己的创业经验。

南大周志华团队获奖,AAAI 2025杰出论文奖出炉

AAAI 2025 共有 12957 篇有效投稿,录用 3032 篇,录取率为 23.4%。三篇杰出论文分别由南京大学、多伦多大学和波尔多大学等机构的研究者获得。AI 对社会影响特别奖颁发给斯坦福大学等机构的 DivShift 研究。


标点符号成大模型训练神器!KV缓存狂减一半,可处理400万Tokens长序列,来自华为港大等 开源

来自华为、港大、KAUST和马普所的研究者提出了一种新的稀疏注意力机制——SepLLM,它通过根据原生语义动态划分token数量来显著减少KV缓存使用量,并在免训练、预训练和后训练场景下实现了50%以上的KV缓存减少。

让大模型成为能够操控计算机的智能体,作者带来OmniParser V2详解

OmniParser V2 是通过更大规模的交互元素检测数据和图标功能描述数据训练,实现更高效的 GUI 解析,并在 ScreenSpot Pro 基准测试中取得了 39.6 的 SOTA 准确率。