多模态推理新思路:D2I框架如何让模型“深思熟虑”又“直觉敏锐”?

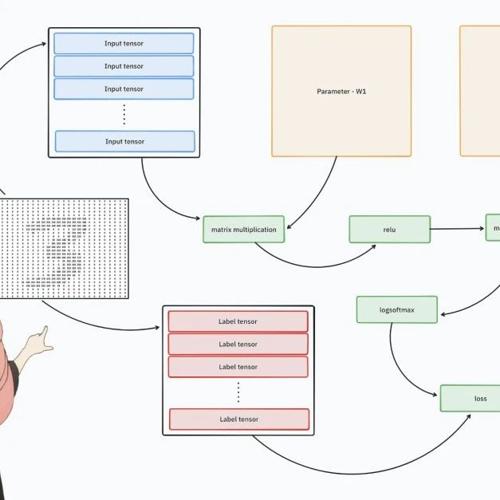
本文介绍了一种名为 Deliberate-to-Intuitive (D2I) 的推理框架,旨在提升多模态大型语言模型(MLLMs)在复杂推理任务中的表现。通过在训练阶段采用深度推理策略,并在测试阶段允许模型自由生成答案,显著提升了多模态模型的推理能力,同时保持了训练的高效性和可扩展性。
本文介绍了一种名为 Deliberate-to-Intuitive (D2I) 的推理框架,旨在提升多模态大型语言模型(MLLMs)在复杂推理任务中的表现。通过在训练阶段采用深度推理策略,并在测试阶段允许模型自由生成答案,显著提升了多模态模型的推理能力,同时保持了训练的高效性和可扩展性。

Google DeepMind发布的Gemini-2.5-Pro在LMArena中全面领先,性能第一、价格最低。它在文本、视觉、Web开发三大核心赛道上均排名第一,在多个细分类别也表现优异。同时,其价格为输入每百万token仅1.25美元,输出10美元,远低于其他竞争对手。

Claude Pro上线后,Anthropic公司发布了新版本Claude 4、Claude Code和Claude API。Claude 4引入了混合模型,性能提升且支持本地文件使用,同时API价格与前版相同。Claude Code基于OpenAI Codex设计,具有代码执行功能,并在GitHub上运行。Claude API则提高了提示语缓存时间及引入了新的功能以优化用户体验。

阿里巴巴发布Qwen3系列模型,包括两个专家混合(MoE)模型和六个Dense模型,并开源了部分权重。该系列在多个基准测试中表现出与OpenAI等顶级模型相当的性能。Qwen3还具有高效的“思考模式”,支持119种语言且训练数据量是Qwen2.5的两倍,有助于Agent调用。部署成本显著降低,整体推理成本也有所节省。
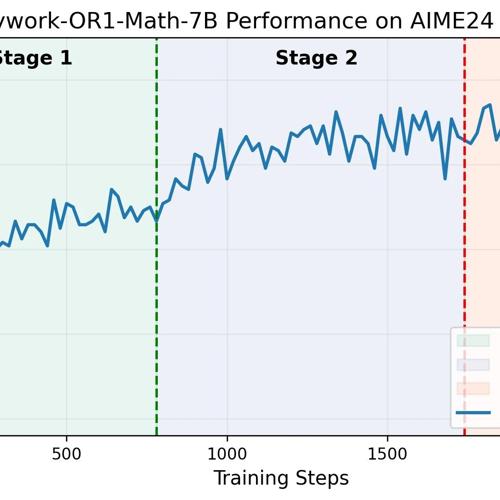
Skywork-OR1发布,7B参数量模型在AIME数学竞赛中得分69.8,性能媲美671B DeepSeek-R1,开源模型、数据和代码助力研究。

阿里开源QwQ-32B模型,性能媲美DeepSeek R1,在推理和代码能力上表现突出。该模型在本地部署和云服务上的成本效益显著,使得更多开发者能够使用高级性能的大模型。

阿里自研Qwen2.5-Max在Chatbot Arena大模型竞技场中表现优异,总分1332位列第七。尤其在编程、数学方面突出,综合排名第三,超越谷歌Gemini家族和Llama 3.1等模型。

OpenAI发布新一代推理模型o3-mini,首次向免费用户提供新模型,并提供高算力版本o3-mini-high。其性能超越了o1,在STEM领域具有优势。