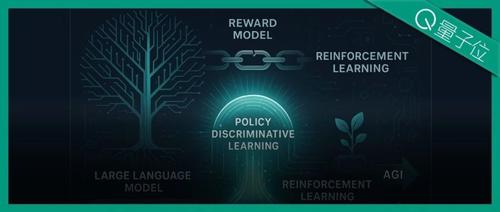
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式 2025年7月11日16时 作者 量子位 已成为AI迈向AGI进程中的关键技术节点。 然而,其中 奖励模型 的设计与训练,始终是制约后训练效果
OpenAI去年挖的坑填上了!奖励模型首现Scaling Law,1.8B给70B巨兽上了一课 2025年7月11日16时 作者 新智元 性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注