
OpenAI推出真实世界百万报酬AI编程能力测试基准:实测Claude 3.5 最强!
OpenAI联合一众大佬发布SWE-Lancer,一个评估前沿LLM在真实软件工程任务中的基准测试。它从Upwork精选了超过1400个真实的软件工程任务,总价值高达100万美元。SWE-Lancer包含个人贡献者和技术领导者的两种类型的任务,采用端到端测试模拟真实环境。研究结果显示模型表现仍有提升空间,OpenAI开源了数据集以促进更多研究。
OpenAI联合一众大佬发布SWE-Lancer,一个评估前沿LLM在真实软件工程任务中的基准测试。它从Upwork精选了超过1400个真实的软件工程任务,总价值高达100万美元。SWE-Lancer包含个人贡献者和技术领导者的两种类型的任务,采用端到端测试模拟真实环境。研究结果显示模型表现仍有提升空间,OpenAI开源了数据集以促进更多研究。

Thinking Machines Lab由前OpenAI成员组成,包括Lilian Weng、John Schulman等。该公司强调开源共享、平等享用人工智能,并致力于研发多模态系统和安全措施。
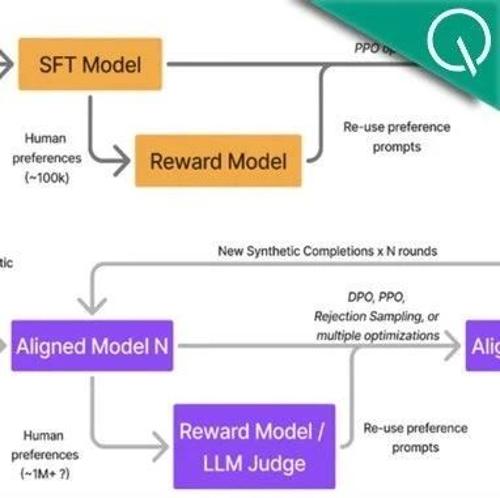
OpenAI前员工John Schulman和Barret Zoph分享了他们在后训练阶段开发ChatGPT的经验,并发布了相关PPT。他们讨论了监督微调、奖励模型和强化学习等关键组成部分,以及如何处理拼写错误和其他挑战。

专注AIGC领域的专业社区分享了OpenAI开源的SWE-Lancer测试基准,用于评估大模型处理真实开发任务的能力。该测试集包含1488个真实的开发任务,总价值达100万美元。SWE-Lancer采用端到端测试方法和用户工具来模拟真实场景,揭示了大模型在复杂软件工程任务中的局限性。
nking Machines Lab 的新创业公司建立了,而其背后有一个堪称有史以来最豪华的大模型创

马斯克旗下的人工智能公司 xAI 重磅发布了 Grok 3 系列模型,宣称其在数学、科学和编码基准测

DeepSeek爆火重塑AI圈,仅需一小部分成本即可达到顶尖性能。企业接入AI成为必然趋势,2030年将有400万AI人才缺口。未来5年需要具备大模型应用开发能力的程序员,大厂内推机会让入局更轻松。知乎知学堂推出就业速成计划,涵盖技术原理、实战应用及职业发展等内容。

Grok3发布会来袭,马斯克宣布其推理能力超越OpenAI。主要分为Grok3和Reasoning两个部分,前者在数学、科学及代码领域表现突出,而后者则在推理方面优于其他模型。此外还推出了Agent工具DeepResearch。马斯克表示X上的Premium用户最早可体验Grok3及其相关功能。

1等模型一决高下。
北京时间2月18日12点30分左右,
马斯克xAI团队展示和OpenAI一样的发
