
民间大神魔改4090 48G秒杀5090!老黄显卡炒作被打脸,“最失败50系显卡”也支棱不起来了?

款“全新”、非官方规格的显卡。淘宝厂家甚至给出了基础款和升级款两种选择,其中基础款用的是拆机进口颗粒
款“全新”、非官方规格的显卡。淘宝厂家甚至给出了基础款和升级款两种选择,其中基础款用的是拆机进口颗粒

DeepSeek的开源周Day2发布了DeepEP库,这是一个为MoE模型训练和推理定制的通信库,支持高吞吐量、低延迟的All-to-All GPU内核,并提供针对非对称域带宽转发优化的内核。
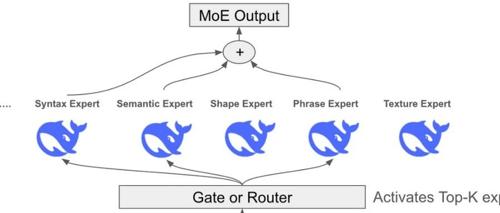
DeepSeek 开源周第二天,带来了 DeepEP 通信库,旨在优化混合专家系统和专家并行模型的高效通信。其亮点包括高效的全员协作通道、专为训练和推理预填充设计的核心以及灵活调控GPU资源的能力,显著提升MoE模型的性能和效率。

DeepSeek 开源首个用于MoE模型训练和推理的EP通信库 DeepEP,优化高效通信和并行处理,支持FP8精度,并提供灵活资源调度。
DeepSeek OpenSourceWeek 发布了首个面向MoE模型的开源EP通信库 DeepEP。它提供了高性能All-to-All通信内核、集群内和集群间全面支持,以及训练和推理预填充及推理解码低延迟内核等特性。性能测试显示其在不同场景下都能提供出色的通信性能。

DeepSeek本周发布的新版本DeepEP为混合专家模型提供高效的通信解决方案,支持Hopper GPU架构。通过优化的核心、低延迟操作和创新的通信-计算重叠方法提升了模型在训练和推理阶段的性能。

DeepEP是针对Hopper GPU优化的MoE模型训练与推理高效通信库,支持FP8和低延迟推理解码,通过NVLink和RDMA提升效率。
DeepSeek发布第二款开源软件库DeepEP,专为MoE模型训练与推理设计,提供高效的全对全通信计算核,支持FP8精度运算。

DeepSeek开源第二弹来了!首个用于MoE模型训练和推理的开源EP通信库DeepEP提供高吞吐量和低延迟的all-to-all GPU内核,支持低精度运算包括FP8。性能方面涵盖高效和优化的all-to-all通信、NVLink和RDMA的支持、预填充任务和推理解码任务等。团队建议使用Hopper GPUs及更高版本Python 3.8及以上CUDA 12.3及以上PyTorch 2.1及以上环境,并提供详细的使用指南。
