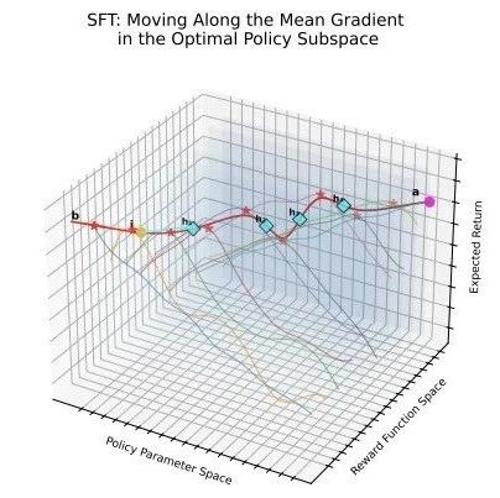
邱锡鹏老师团队发现SFT与DPO破壁统一:内隐奖励作为桥梁 2025年7月5日14时 作者 机器学习算法与自然语言处理 本文探讨了SFT与DPO的理论关联及其改进方法,提出小学习率策略与基于f散度的新目标可显著提升LLM性能,揭示隐式奖励在两者优化中的作用,并为未来统一框架提供了基础。