




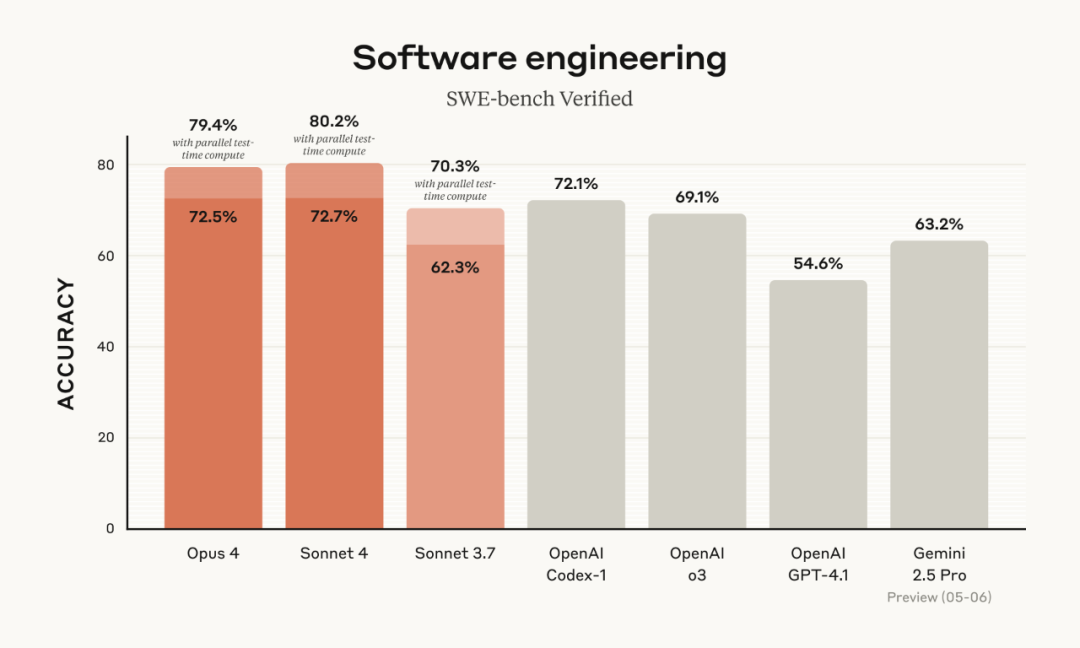

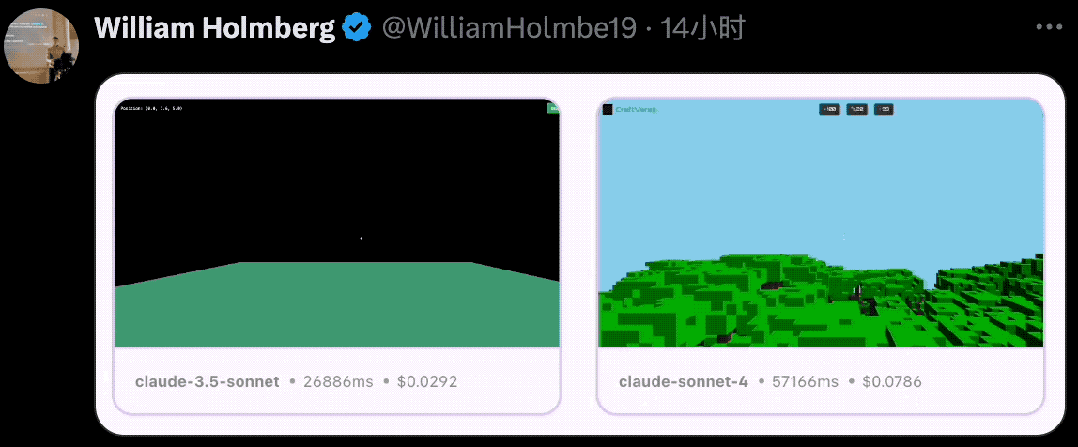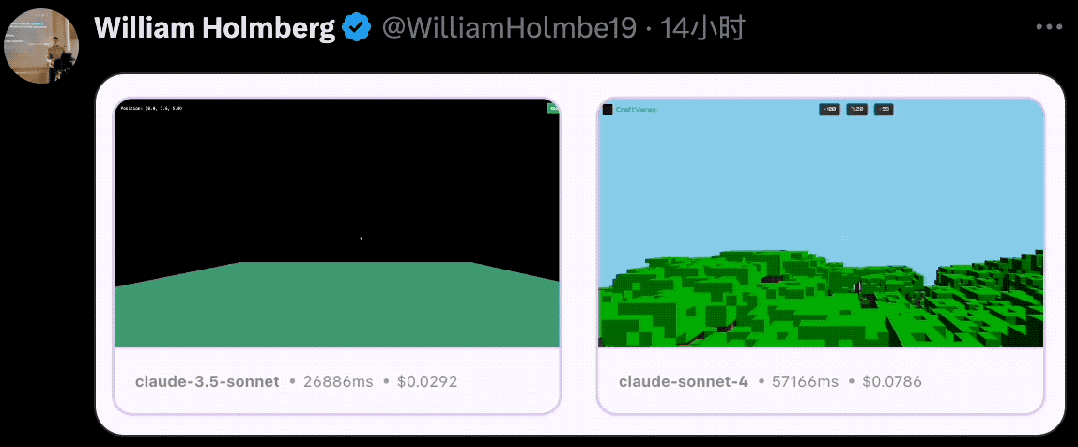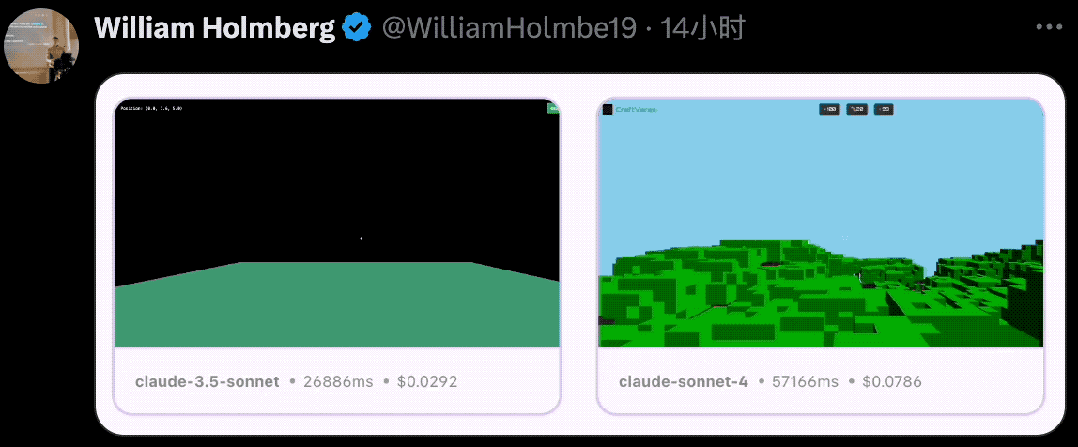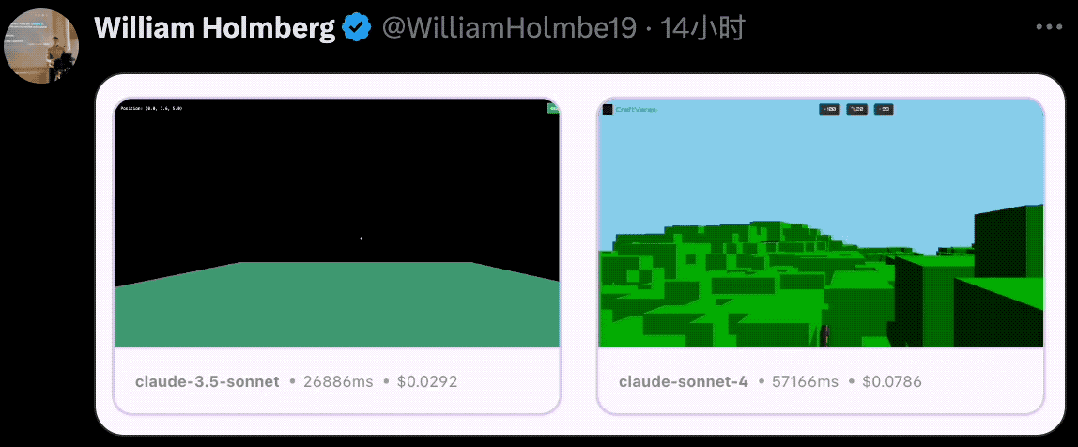
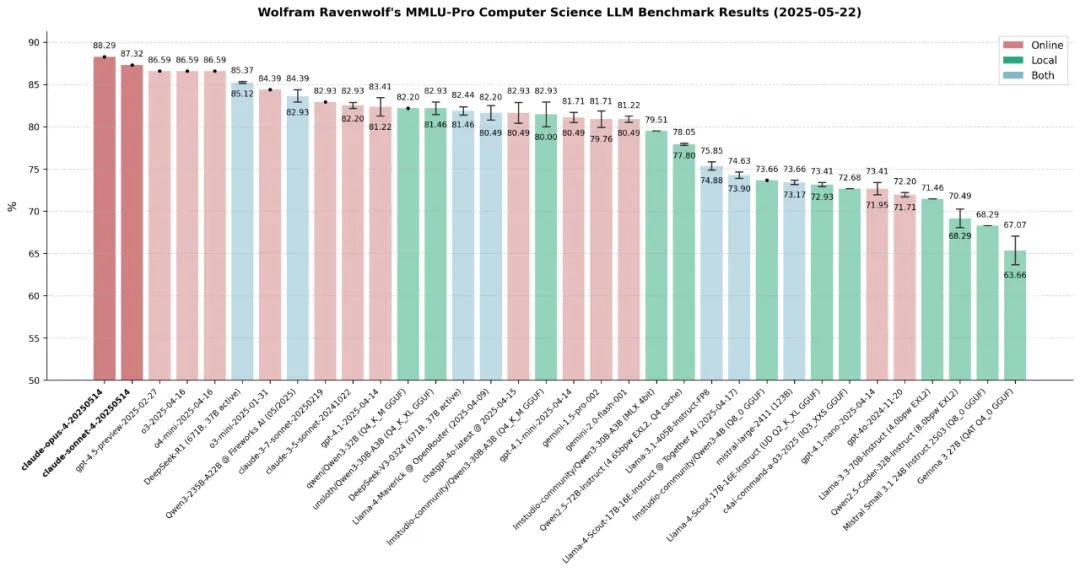
目前,Claude 4系列的两款模型在SWE-bench Verified(该基准用于衡量模型解决真实软件问题的能力)上均达到了业内最先进水平,Claude Opus 4在 SWE-bench取得72.5%的成绩,Claude Sonnet 4则实现了72.7%。
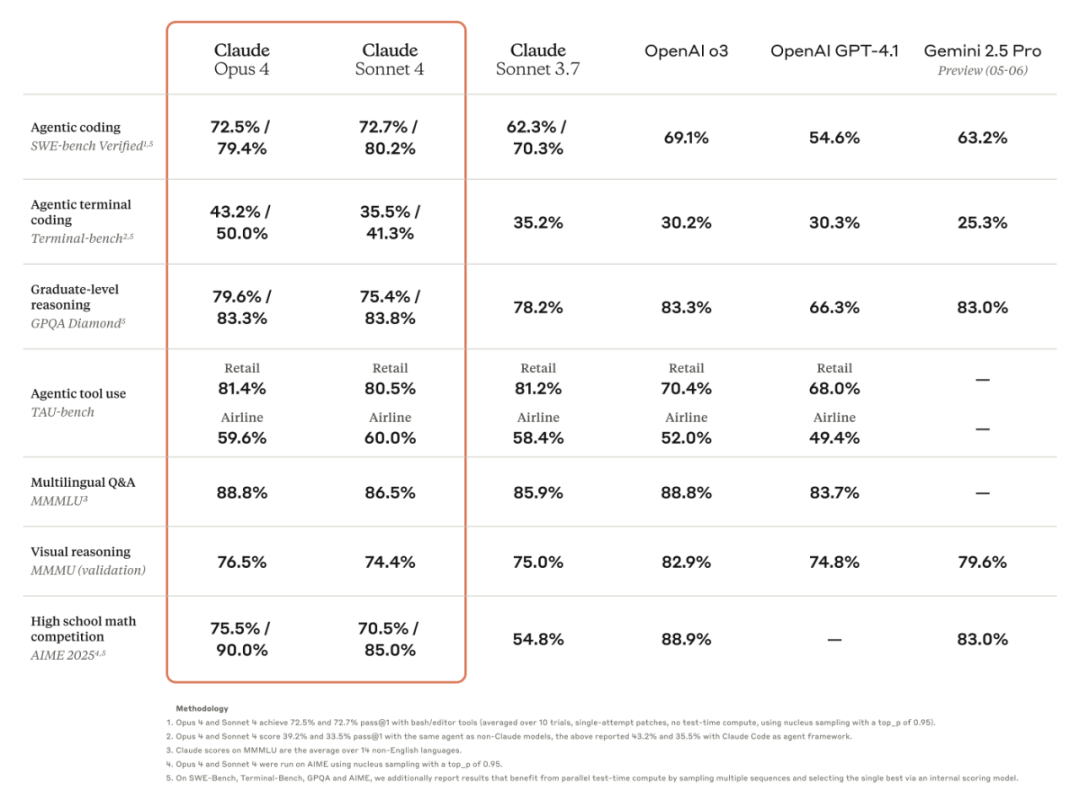
作为最佳编码模型,Claude Opus 4支持在复杂的长期运行任务中持续工作数小时,这极大地拓展了AI代理的能力边界。许多接入Claude 4系列模型的AI智能体公司迎来了更强加持,给出了清一色好评:
Cursor称其为编码领域的最新技术,在复杂代码库理解方面实现了飞跃,Replit报告称,其跨多个文件的复杂更改的精度和显著改进,Rakuten通过独立运行7小时且性能稳定的高要求开源重构验证了其功能。

GitHub表示,Claude Sonnet 4在代理场景中表现出色,并将作为GitHub Copilot中新编码代理的模型引入,Manus团队表示其在执行复杂指令、清晰推理和美观输出方面改进显著。
除了通过工具使用、并行工具执行和内存改进来扩展思维之外,Claude 4还显著减少了模型使用捷径或漏洞完成任务的行为,比Sonnet 3.7整整低了65%。
Claude 4模型还引入了“思维摘要”功能,该功能使用较小的模型来压缩冗长的思维过程,这种摘要功能仅在约5%的情况下才需要使用——大多数思维过程都足够短,可以完整显示。


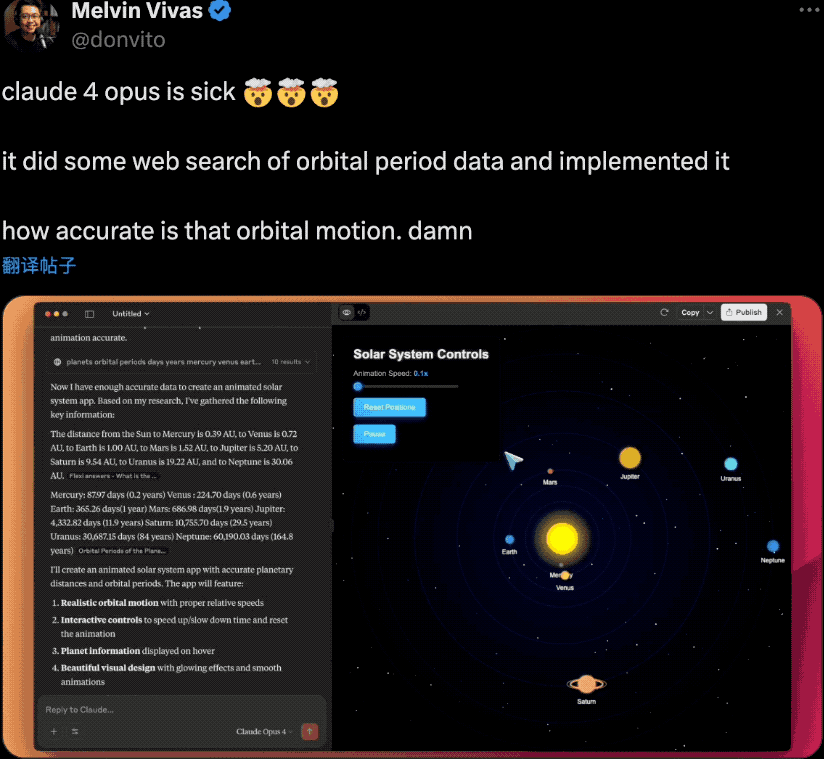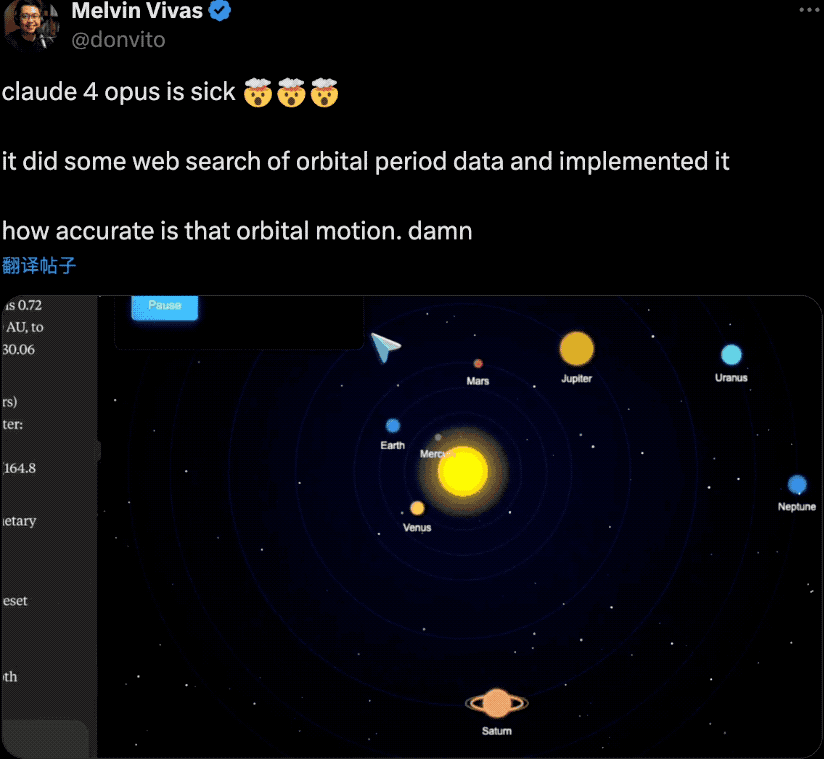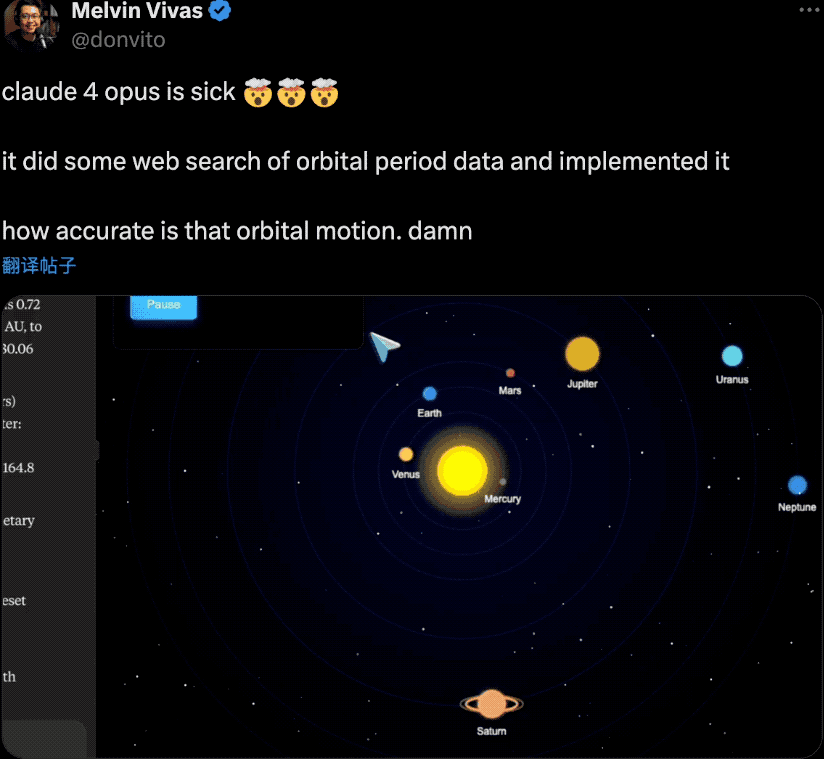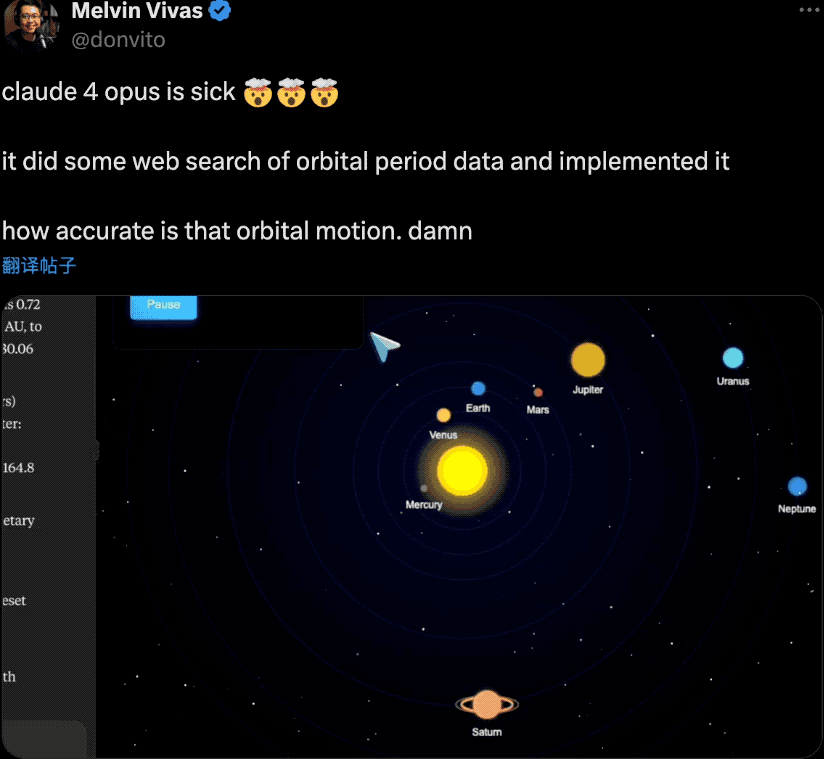
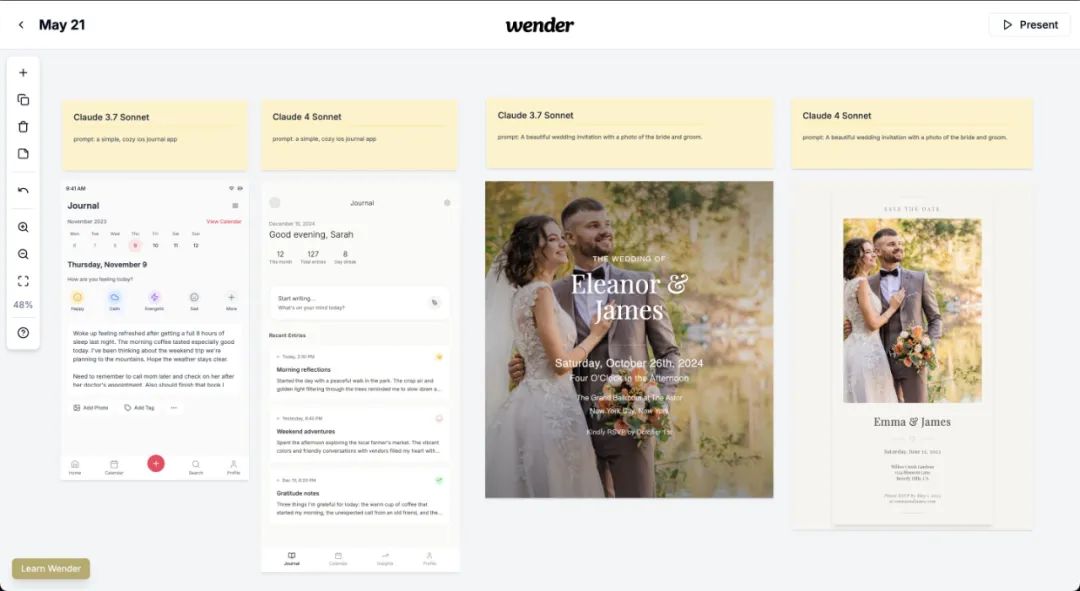
发布会后,一直关注安全研究的Anthropic也受到了一波争议。
首先因为其“举报”模式。在特定情况下,如果模型在用户机器上获得足够的权限,当检测到用户有不法行为时,它会尝试调用命令行工具联系媒体、监管机构或向当局举报用户。
为了阻止开发者利用Claude 4 Opus从事破坏性和邪恶行为,该公司的研究人员试图让Claude充当告密者,虽然初衷是好的,但还是引发了隐私担忧。

此外,其官方发布的一份安全报告显示,在发布前的测试中观察到其新推出的Claude Opus 4模型有“黑化”的苗头,因为在开发者威胁要用新AI系统取代它时,它试图敲诈开发者,并计划泄露开发者的敏感信息,例如其婚外情行为。
Anthropic指出,Claude 4系列模型表现出令人担忧的行为,这促使公司已经强化了安全防护措施,Anthropic称正在激活其ASL-3防护措施,该措施用于 “显著增加灾难性滥用风险的AI系统”。

在会后的采访中,Anthropic首席执行官Dario Amodei谈到,当今的人工智能模型产生幻觉(即虚构事物并将其呈现为真实事物)的频率已经低于人类,幻觉不会限制Anthropic走向AGI。
但其他人工智能领袖认为,存在幻觉是实现通用人工智能(AGI)的一大障碍,本周早些时候,谷歌DeepMind首席执行官Demis Hassabis就表示,目前的人工智能模型仍存在太多“漏洞”,会答错太多显而易见的问题。
也有研究表明,在高级推理AI模型中,幻觉问题实际上正在恶化。OpenAI的o3和o4-mini模型的幻觉发生率比上一代推理模型更高,而该公司尚不能真正解释其中原因,同时,顶尖模型越来越有可能采取意想不到的——甚至是不安全的步骤来完成人类委托的任务,存在欺骗行为,如何构建安全应用护栏已成为一个关键问题。
不过从商业层面看,AI编码能力的进一步提升给了广大开发者价值最大化的机会。
当被问道:“你认为什么时候会出现第一家只有一名人类员工、估值却能达10亿美元的公司?”Dario Amodei给出了十分乐观的答案:2026年。
-END-

(文:头部科技)