新纪录!小米又抛出一个开源模型,在22个公开评测集上实现SOTA,主打声音理解

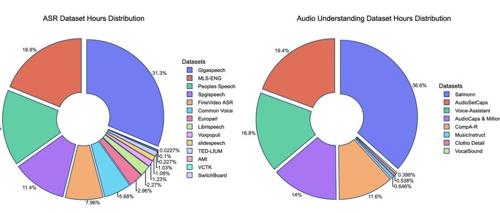
小米发布MiDashengLM-7B音频模型,通过统一理解语音、环境声与音乐的跨领域能力提高用户场景理解的泛化性。该模型基于公开数据集进行预训练和有监督微调,展示了在多项关键任务上的优势,并支持在边缘设备上部署。
小米发布MiDashengLM-7B音频模型,通过统一理解语音、环境声与音乐的跨领域能力提高用户场景理解的泛化性。该模型基于公开数据集进行预训练和有监督微调,展示了在多项关键任务上的优势,并支持在边缘设备上部署。

OpenAI发布了两款新的音频模型GPT-4o-transcribe和GPT-4o-mini-transcribe,旨在提升语音转文本的准确性,并引入可操控性文本转语音功能。此举为自然、直观的口语对话迈出了重要一步。

OpenAI发布了三种新的先进音频模型:两款语音转文本模型表现优于Whisper,新TTS模型可教AI说话。为了让开发者构建强大的‘语音智能体’,OpenAI推出了三项重要功能:全新语音转文本模型、文本转语音模型和升级版Agent SDK。

多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,