
视觉理解

OpenAI发布GPT-4.1:百万token上下文,全方位碾压4o并且价格更低,GPT-4.5三个月后下线

,分别是 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano,它们仅通过 API

AI也能操作手机了!DroidRun 让 Agent 实现智能手机自动化操作!
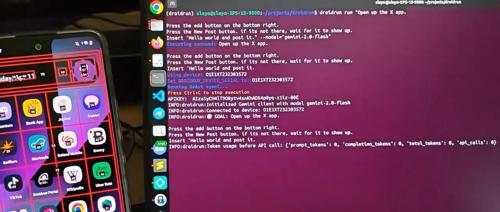
DroidRun 是一款新的开源 AI 手机操作工具,能像人类一样操作 Android 手机。结合视觉理解与 UI 结构提取技术,实现流畅的交互体验。它不仅能打开 App、发送消息,还能自动导航菜单、处理错误,甚至完成复杂任务如订车或录视频。项目尚未正式开源,但即将上线 GitHub 仓库。
视觉强化微调!DeepSeek R1技术成功迁移到多模态领域,全面开源

视觉强化微调项目 Visual-RFT 通过规则奖励和强化学习方法,实现了视觉语言模型在目标检测、分类等任务中的高效提升。项目已开源,欢迎加入。

炸裂!DeepSeek 的新春礼物——多模态模型Janus-Pro 详解

DeepSeek发布Janus-Pro模型,实现图文理解和图像生成的双面杀手。该模型通过解耦视觉编码路径实现了真正的”一心二用”,并采用统一架构设计、精心训练策略和MIT开源协议。其在理解任务得分0.8和生成质量上碾压DALL-E 3等主流模型。
实测豆包全家桶 ,推理、视觉、语音能力大增,唱歌居然跑调

临近春节,豆包1.5 Pro发布,包含基础模型、视觉和实时语音模型。测试显示其推理能力、视觉理解能力和语音识别能力均有提升,但仍有待提高。基础模型已开始灰度测试,其他两个模型已上线。

理解生成协同促进?华为诺亚提出ILLUME,15M数据实现多模态理解生成一体化

华为诺亚方舟实验室提出统一多模态大模型ILLUME,仅使用约15M图文对数据实现视觉理解、生成等任务的出色表现,并采用自提升式多模态对齐策略促进理解和生成能力协同进化。