
清华大学

清华SageAttention3,FP4量化5倍加速!且首次支持8比特训练

清华大学陈键飞团队提出SageAttention3,实现了5倍于FlashAttention的推理加速。此模型在多种视频和图像生成等大模型上保持了端到端的精度表现,并首次提出了可训练的8比特注意力用于大模型的训练加速。


微软&清北RPT:强化学习的风又吹到了预训练!

微软研究院、北大和清华联合提出强化预训练新范式RPT,通过RL训练提高LLMs预训练性能。该方法在OmniMATH数据集上优于现有模型,并且随着计算量增加预测准确性提升。
视频扩散模型新突破!清华腾讯联合实现高保真3D生成,告别多视图依赖

清华大学联合腾讯提出 Scene Splatter,利用视频扩散模型从一张图像生成满足三维一致性的多视角视频片段,解决单张图片条件下三维重建的病态问题。
韦东奕论文登数学顶刊,将散焦方程的爆破性研究扩展至d≥4

韦东奕与两位合作者的论文《On blow-up for the supercritical defocusing nonlinear wave equation》发表于数学顶刊《Forum of Mathematics, Pi》,研究了散焦非线性波动方程在特定条件下的爆破解现象。该研究成果填补了相关空白,并提出了新的证明方法,可以推广到其他偏微分方程的爆破研究。
MSRA清北推出强化预训练!取代传统自监督,14B模型媲美32B

微软亚洲研究院联合清华大学、北京大学提出RPT预训练范式,将强化学习深度融入预训练阶段,通过生成思维链推理序列和使用前缀匹配奖励来提升模型预测准确度。
清华给电子显微镜加上Agent,DeepSeek V3全程调度,数天流程缩短至几分钟
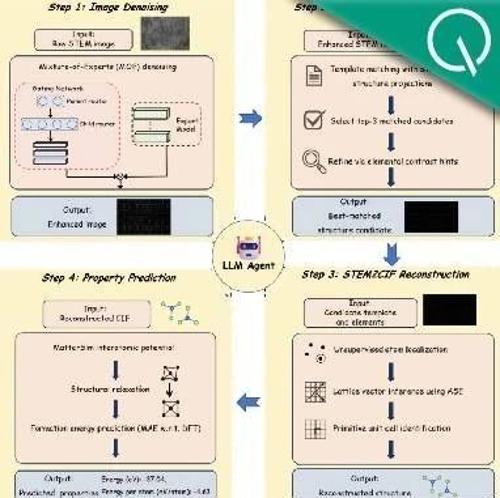
清华大学团队发布电镜领域的AI代理AutoMat,能够自动将原子级STEM图像转换为标准CIF结构,并准确预测形成能等物性。该系统在多个难度级别下均表现出色,超越了现有工具。
Qwen&清华团队颠覆常识:大模型强化学习仅用20%关键token,比用全部token训练还好

近期清华大学团队提出的研究表明,在强化学习训练大模型时,仅使用20%的高熵token就能显著提升模型性能。研究指出80%低熵token会影响模型推理能力,并可能起到负面作用。