
李飞飞、DeepSeek为何偏爱这个国产模型?

阿里云通义千问的Qwen模型在短短时间内取得了显著突破,仅用1000个样本在H100上监督微调26分钟就训练出与顶尖推理模型相当的新模型s1-32B。这一成果引起了AI社区的关注和赞誉,取代了Llama成为开源AI社区的重要标杆基座模型。
阿里云通义千问的Qwen模型在短短时间内取得了显著突破,仅用1000个样本在H100上监督微调26分钟就训练出与顶尖推理模型相当的新模型s1-32B。这一成果引起了AI社区的关注和赞誉,取代了Llama成为开源AI社区的重要标杆基座模型。

阿里云通过开源领先模型繁荣AI生态,推动技术创新与商业良性循环。通义千问系列模型屡获佳绩,吸引开发者和企业加入其云计算平台,实现’全尺寸、全模态、多场景’的开源布局。

文章介绍了通过16块H100 GPU在26分钟内训练出低成本语言模型S1K的方法,该模型与OpenAI的o1系列和DeepSeek R1系列性能相当。但实际研究发现,论文核心是基于开源Qwen2.5-32B模型,进行小数据集监督微调,并非直接复制了DeepSeek R1。

斯坦福大学李飞飞团队联合华盛顿大学研究人员利用不到50美元的云计算费用训练出了名为s1的推理模型,其数学与编码能力表现接近OpenAI、DeepSeek等大模型。该模型已在GitHub上发布,并且通过精心挑选的数据集和蒸馏方法实现了低成本高效训练。
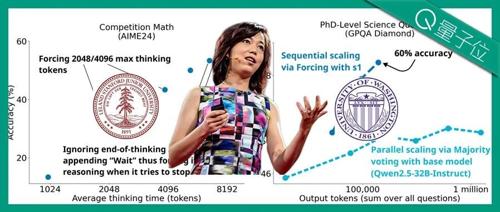
研究团队通过蒸馏技术从阿里通义Qwen2.5-32B-Instruct模型出发,结合Gemini 2.0 Flash Thinking实验版数据集训练出高性能推理模型s1-32B,在数学评测集中表现优异。
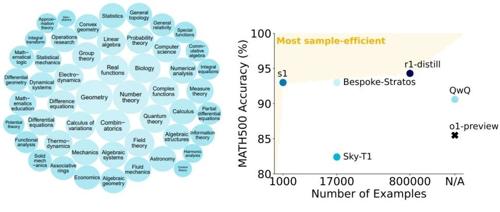
一种新的语言建模方法Test-time Scaling通过测试时增加额外计算来提升性能,作者李飞飞等新作S1提出了一种简单而有效的测试时扩展方法,并展示了其实用性。
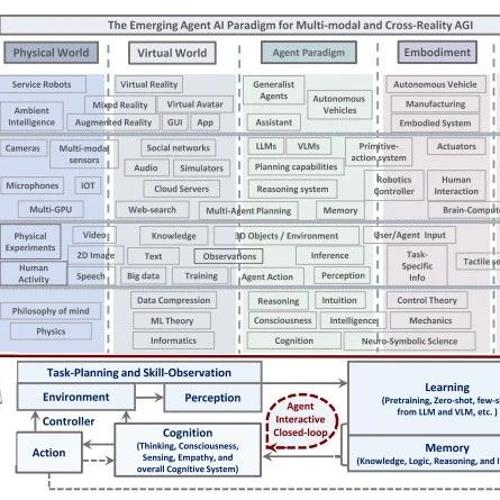
论文探讨了Agent AI的全面框架,定义其为能够感知视觉和语言输入并产生具身行为的交互式系统。该框架强调跨现实性、多模态方式以及认知能力,未来可应用于虚拟现实和各类软件产品中。

李飞飞发布Agent AI综述性报告,指出LLM之上是Agent AI,并从多模态感知、交互、学习、应用等方面进行阐述,革新游戏、机器人、医疗等行业,推动AI迈向通用人工智能。

李飞飞教授在2024年创立了World Labs公司,并发布了首个基于图像生成3D场景的AI系统。同年,她担任斯坦福大学计算机科学教授、HAI研究院院长,并发表了多场关于空间智能的重要演讲和论文。
