
任务级奖励提升App Agent思考力,淘天提出Mobile-R1,3B模型可超32B
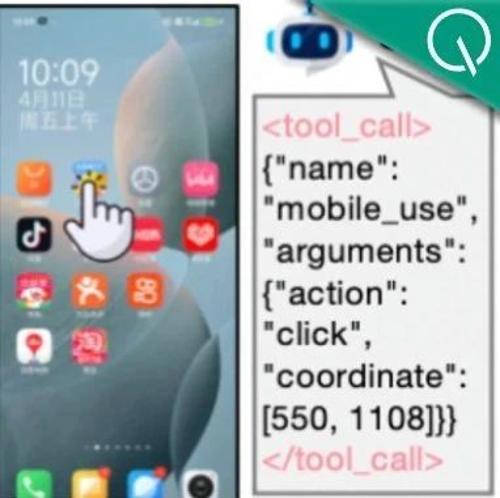
Mobile-R1团队提出了一种新的交互式强化学习框架Mobile-R1,结合任务级奖励和多阶段训练流程,显著提升了基于视觉语言模型的移动代理能力。通过三阶段训练过程(格式微调、动作级在线训练和任务级在线训练),Mobile-R1成功处理了包括用户指令在内的复杂任务,展示了在动态环境中进行有效学习的能力。
Mobile-R1团队提出了一种新的交互式强化学习框架Mobile-R1,结合任务级奖励和多阶段训练流程,显著提升了基于视觉语言模型的移动代理能力。通过三阶段训练过程(格式微调、动作级在线训练和任务级在线训练),Mobile-R1成功处理了包括用户指令在内的复杂任务,展示了在动态环境中进行有效学习的能力。

ByteDance Research 的视频理解大模型眼镜猴(Tarsier)迎来了重大更新,发布了第二代模型 Tarsier2 及相关技术报告。Tarsier2 能够分析复杂的影视名场面,并对真人和动画、横屏和竖屏、多场景和多镜头的视频进行描述,其性能超越了 GPT-4o 和 Gemini-1.5-Pro 等闭源模型,在多个公开基准上表现出色。