
强化学习



阿里开源创新AI Agent:媲美Deep Research,Github每日增长第一
专注AIGC领域的专业社区分享微软&OpenAI、百度文心一言等大语言模型的发展和应用,强调信息检索挑战及解决方案。介绍阿里通义实验室开源的创新AI Agent框架WebSailor,在复杂任务中的出色表现及其技术原理。



小扎火速挖走谷歌IMO金牌模型华人功臣!以后还是别公布团队名单了吧

谷歌DeepMind三位华人核心成员因获得IMO金牌被曝加入Meta。杜宇、Tianhe Yu和王薇月曾负责Gemini模型的思考后训练,谷歌随后挖角微软也宣布从谷歌挖来20多名人才。
打脸OpenAI!谷歌Gemini高级版获IMO 2025官方认证金牌:纯自然语言端到端推理
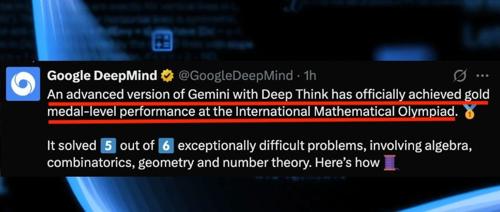
谷歌DeepMind的Gemini模型在2025年国际数学奥林匹克竞赛中以金牌标准完成6题解出5题,全程使用自然语言推理,获得IMO官方认证。这一成就反映了AI在“深度思考”方面的进步。
美团提出多模态推理新范式:RL+SFT非传统顺序组合突破传统训练瓶颈

美团团队提出Metis-RISE框架,通过强化学习激励和监督微调增强多模态大语言模型的推理能力。最终产生7B和72B参数的模型,在OpenCompass多模态推理榜单上取得了优异成绩,验证了方法的有效性和可扩展性。