阿里开源Qwen-Image,AI会写汉字了!

阿里开源Qwen-Image模型,拥有20B参数的MMDiT多模态扩散变换器,支持多种语言文本渲染和多样化艺术风格图像生成。该模型在复杂文本渲染和精确图像编辑方面取得显著进展,已在HuggingFace上排名首位。
阿里开源Qwen-Image模型,拥有20B参数的MMDiT多模态扩散变换器,支持多种语言文本渲染和多样化艺术风格图像生成。该模型在复杂文本渲染和精确图像编辑方面取得显著进展,已在HuggingFace上排名首位。

Mistral AI 发布首个先进音频模型Voxtral,提供低成本高性能的24B和3B版本,支持多语言、长文本上下文处理等。该模型已在HyperAI超神经官网上线Demo,满足语音智能市场多元需求。

Google扩展其实验性NotebookLM产品线,使其AI摘要功能支持超过50种语言。此更新标志着谷歌在增强AI工具可访问性和拓展多语言市场方面的重要一步。
网易有道开源的EmotiVoice是一款支持多语言、海量音色和情感合成的TTS系统,具有高效部署、易用接口和语音克隆等功能,在内容创作、智能语音助手、教育、客服系统及娱乐游戏等领域具有广泛应用前景。
一款免费、开源的音乐创作与编辑工具OpenUtau,兼容UTAU库和采样器,支持VSQX导入等强大功能,适用于Windows、macOS和Linux。

最近TTS开源项目大爆发。介绍4个模型:Medium、Small、Tiny和Nano,涵盖英语及多语言模型,并提供详细的Orpheus TTS项目简介和功能特点。
网易有道 EmotiVoice 开源模型支持多语言和多种音色,具有情感合成功能。通过Docker镜像或本地安装方式快速部署使用,满足开发者和企业多样化需求。

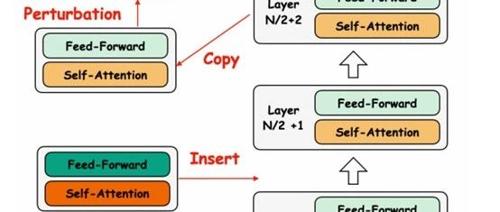
往往是由硬件和更大规模驱动的,但同样甚至更多是由
重大的算法改进和模型架构的重大变化、训练数据组合等