
超CLIP准确率11%!伯克利港大阐明「LLM文本-视觉」对齐深层机制

新智元报道
UC伯克利和香港大学团队的新工作LIFT首次系统性地剖析了冻结大语言模型作为文本编码器在多模态对齐中的优势来源、数据适配性和关键设计选择,显著提升了组合语义理解能力和长文本处理效果。
新智元报道
UC伯克利和香港大学团队的新工作LIFT首次系统性地剖析了冻结大语言模型作为文本编码器在多模态对齐中的优势来源、数据适配性和关键设计选择,显著提升了组合语义理解能力和长文本处理效果。
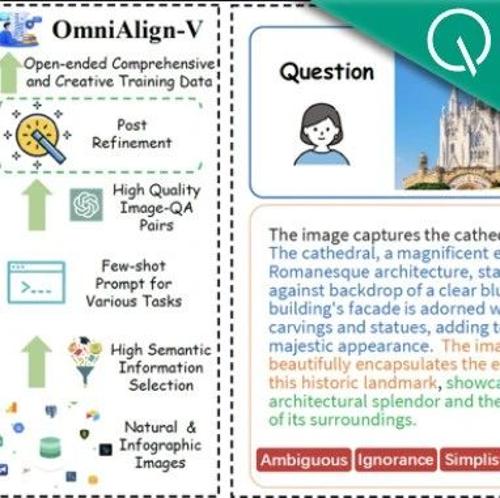
上海交大团队通过实验发现多模态数据对语言质量的影响有限,提出OmniAlign-V数据构建Pipeline,包含高质量的多模态数据,并在多个基准测试中验证了其有效性。
