
同样1GB文本,为何中文训练效果差?对话EleutherAI研究员Catherine,看懂多语言模型的“诅咒”与“祝福”

跨界到自然语言处理(NLP),Catherine Arnett 深刻体会到,
多语言背景带来的思维多
跨界到自然语言处理(NLP),Catherine Arnett 深刻体会到,
多语言背景带来的思维多

马斯克的人工智能初创公司xAI计划筹集120亿美元资金,目的是在AI竞赛中保持领先地位。该公司正准备通过股权与债务融资筹得至多120亿美元的资金。

扩散语言模型(dLLMs)因并行解码、双向上下文建模和灵活插入masked token而备受关注。然而,上海交通大学等团队在最新研究中指出,dLLMs存在根本性架构安全缺陷,几乎毫无防御能力。DIJA攻击无需训练或改写模型参数,就能生成有害内容,并揭示了扩散语言模型的弱点,为dLLMs的安全研究拉开序幕。
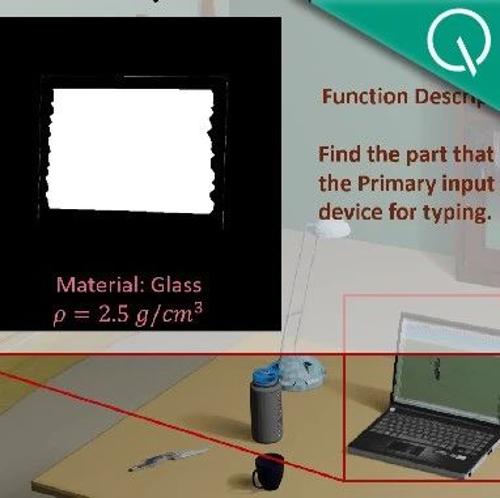
南洋理工大学与上海人工智能实验室提出首个全面的物理属性3D数据集PhysXNet,包含超过26K带有丰富注释的3D物体,涵盖五种核心物理属性,并介绍了一种基于此的数据生成框架PhysXGen。
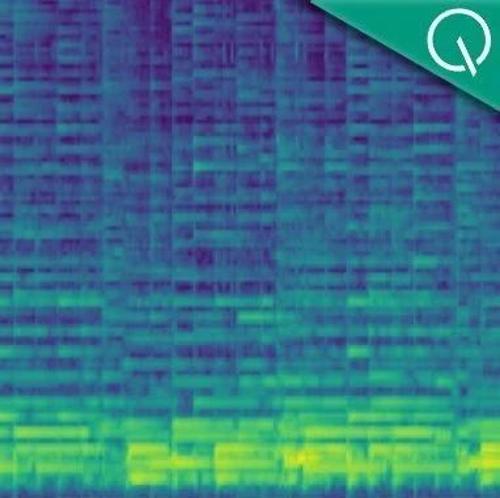
文生音频系统FreeAudio实现精确时间控制与90秒长时音频生成,相比现有方法具有显著提升。它无需额外训练即可同时支持时间和长时生成,并在多个指标上优于主流方法。

英伟达顶级工程师何宜晖加入xAI,正式发布的新模型Grok-4引发广泛关注。何宜晖此前在英伟达深度参与先进世界模型平台Cosmos的研发,并对Grok-4表现出高度关注。



