
分享
谷歌 Gemini 2.0 曝光,挑战 GPT-4o!
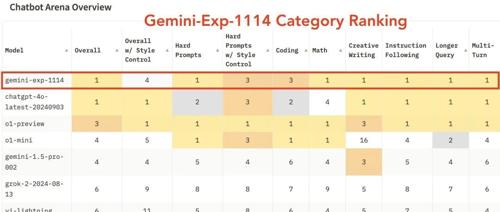
一周前谷歌的Gemini-Exp-1114模型取代GPT-4o成为AI多模态大模型榜首。但GPT-4o更新后再次夺回第一。谷歌和OpenAI在多模态大模型上的竞争激烈,技术正向原生多模态方向发展。多位审稿人将在12月6日带来关于多模态大模型的公开课。


谷歌新整了个 GenChess,让万物都可变成象棋!

上周谷歌邀请我们参观国际象棋世界冠军赛,体验了AI展区,特别是GenChess能根据关键词生成独一无二的国际象棋棋子和对手。得益于Imagen 3和Gemini Flash模型,用户可以通过调整设置观看3D视角下的游戏,并设计电脑对手对比主题风格。
Coral AI 重塑了文档分析

文档作为工作和生活中常见的信息存储方式,Coral AI通过先进的AI技术提高了信息处理效率和准确性,促进了不同文化背景之间的沟通与交流,适用于各种多语言文档处理场景。
Kimi悄悄开源了自家推理框架Mooncake~

Mooncake是Kimi的服务平台,后者是由Moonshot AI提供的大型语言模型服务。基于KVCache的解耦架构和预测性早期拒绝策略,Mooncake在高过载场景下实现了显著的吞吐量增加,并且通过改进的传输引擎支持灵活的数据传输。

被 AutoGLM 秀一脸,这才是 Agent 该有的样子

智谱发布的升级版AutoGLM让AI Agent能模拟人类操作手机执行复杂任务。用户可通过文字或语音指令控制手机,实现从表达到执行的范式转变。新版本包括复杂步骤与循环操作、跨App操作、记忆与快捷指令等功能,极大提升用户的工作效率。