
学术

ICML 2025 Spotlight|华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍

Mixture-of-Experts(MoE)架构尽管稀疏激活减少了计算量,但显存资源受限的端侧部署仍面临挑战。研究提出Mixture-of-Lookup-Experts(MoLE),通过将专家输入改为嵌入(token) token,利用查找表代替矩阵运算,有效降低推理开销,减少数千倍传输延迟。
刚刚,Gemini 2.5 Pro升级,成编程模型新王

Google DeepMind的Gemini 2.5 Pro更新提升了编程能力和多模态推理功能,可构建Web应用、游戏和模拟程序,并根据自然图像生成代码。
CVPR 2025 满分论文|收敛速度提升21倍!VA-VAE:重建 vs. 生成,解决 LDM 的优化困境

256 生成上实现了最佳 (SOTA) 性能,FID得分为1.35,同时在短短64个epoch内就达
SGLang Team:在 96 个 H100 GPU 上部署具有 PD 分解和大规模专家并行性的 DeepSeek
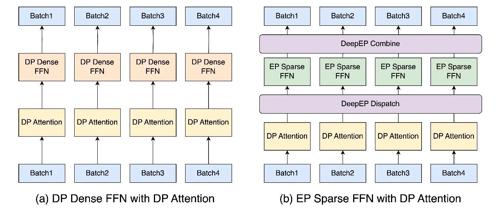
25-05-05-large-scale-ep
DeepSeek 是一个广受欢迎的开源大型语言模型
3B逆袭7B巨头!Video-XL-Pro登顶长视频理解SOTA,单卡万帧准确率超98%

上海交通大学、北京智源研究院和特伦托大学的研究团队推出了一种新的超长视频理解大模型Video-XL-Pro,该模型通过创新的重构式令牌压缩技术实现了近一万帧视频的单卡处理,并在多个基准测试中超越了此前发布的大型模型。
ICML 2025 注意力机制中的极大值:破解大语言模型上下文理解的关键

近日,ICML 2025 新研究揭示大型语言模型中注意力机制的查询 (Q) 和键 (K) 表示存在极大值现象,而值 (V) 表示则没有这种模式。极大值对上下文理解至关重要,研究提出保护 Q 和 K 中的大值能有效维持模型的上下文理解能力。

