
Google开源MCP数据库工具箱轻松连接各类数据库

Google开源新项目genai-toolbox简化数据库集成,支持PostgreSQL、MySQL等主流数据库,通过统一的YAML配置文件定义数据源和工具集,开发者只需配置tools.yaml文件即可启动服务器并调用AI应用中的数据库工具。
Google开源新项目genai-toolbox简化数据库集成,支持PostgreSQL、MySQL等主流数据库,通过统一的YAML配置文件定义数据源和工具集,开发者只需配置tools.yaml文件即可启动服务器并调用AI应用中的数据库工具。

《面向人工智能的数据标注合规指南》团体标准草案稿研讨会顺利召开,聚焦数据来源、标注内容与过程操作等五大关键议题,助力AI企业发展。现诚邀相关企业及服务机构加入标准起草编制组,参与行业规范建设。

随着AI能力增强,开发者面临运行不可信代码的安全挑战。Microsandbox通过微虚拟化技术解决了这一难题,支持硬件级隔离和毫秒启动,并适用于多种应用场景如AI代码执行、数据分析等。
Cursor陷入由定价策略引发的信任危机,原本为用户提供至少20美元的模型推理额度和无限制使用Auto模式改为计算量限制后,用户因不满服务缩水和沟通不透明而集体反弹,最终Cursor宣布全额退款、增加透明度等补救措施。
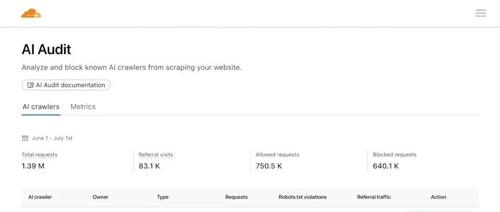
Cloudflare推出按爬取付费机制,阻止AI数据爬虫访问网站内容,从技术架构上设计优雅。此举旨在保护原创内容创作者的收益,并可能引发一系列后果和新商业模式的变化。

《人工智能大模型私有化部署技术实施与评价指南》团体标准正式立项,旨在解决当前企业大模型私有化部署过程中遇到的技术选型混乱、算力资源错配等痛点。该标准涵盖关键技术标准与安全治理标准,通过全流程要点覆盖(选用+部署+优化)、深度融合(技术+安全+评价+案例)及三方协作机制,推动人工智能产业高质量发展。
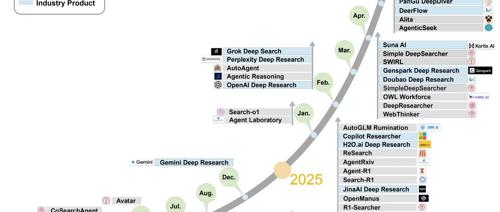
DeepResearch智能体是大语言模型驱动的AI系统,能够进行复杂研究任务的动态推理、自适应规划和工具使用,并生成全面报告。论文提出了DR智能体的关键技术组件及其挑战与未来方向。
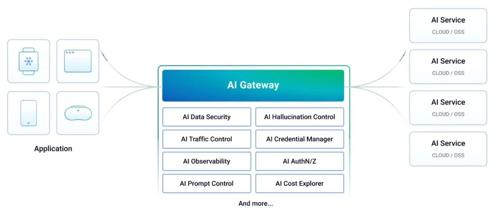
AI Gateway 解决了大模型应用中复杂的问题,通过 Arch Config 文件实现智能路由和工具调用。它将一些公共逻辑剥离至基础设施层统一处理,如上下文注入、模型选择及安全防护等。项目旨在让开发者专注于核心业务逻辑,提高开发效率与系统稳定性。
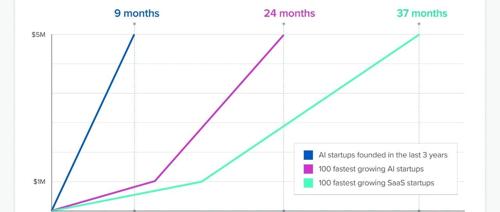
a16z 新博文《From Demos to Deals: Insights for Building in Enterprise AI》指出,AI 已成为几乎所有企业的战略核心,为公司带来巨大机会,但也存在挑战。文章总结了成功进入市场的关键点,包括实现模型的可靠性、构建强大“脚手架”、深入客户业务逻辑等。此外,AI 公司的增长速度远超传统 SaaS 企业,且护城河建立方式多样。
