大模型领域新书推荐!献给想要转型LLM应用开发的朋友

2025年,DeepSeek现象席卷全中国。文章探讨了AI时代开发者对大模型应用开发的需求与挑战,指出这一领域技术标准未定型且无序化。作者通过整理个人笔记,撰写了《探秘大模型应用开发》一书,帮助读者系统了解大模型开发知识。
2025年,DeepSeek现象席卷全中国。文章探讨了AI时代开发者对大模型应用开发的需求与挑战,指出这一领域技术标准未定型且无序化。作者通过整理个人笔记,撰写了《探秘大模型应用开发》一书,帮助读者系统了解大模型开发知识。

2025年初,DeepSeek大模型凭借超低训练成本和高推理能力迅速走红,并登顶全球苹果应用商店免费榜。然而,开发者们面对大模型开发还缺乏系统知识和最佳实践。《探秘大模型应用开发》一书通过整理归纳大量碎片化信息,帮助读者理解大模型技术,解答相关疑问。
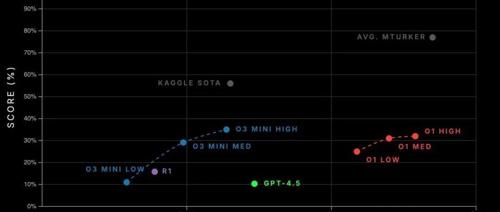
OpenAI 推出 GPT-4.5,这是迄今为止最大、知识最渊博的模型之一,预训练规模约为 GPT-4 的 10 倍。它在写作、编程和实际问题解决方面表现出色,并且幻觉率较低。

智合标准中心联合公安部第三研究所、工业和信息化部第五研究所启动《人工智能大模型私有化部署技术实施与评价指南》团体标准编制工作,旨在填补大模型部署空白,并促进其健康发展。
Anthropic公司发布了Claude 3.7 Sonnet和Claude Code两个模型,前者具备混合推理能力,后者则是一个面向开发者的智能编码助手。Claude 3.7 Sonnet在编码和前端网页开发方面表现出强大的性能,并能更好地处理复杂的代码库。Claude Code作为命令行工具,简化了开发者的工作流程,能够进行多种编码任务,如编写测试、提交代码等,显著减少了开发时间和工作量。

首个开源代码库FlashMLA针对英伟达Hopper架构GPU优化,支持BF16数据类型和分页KV缓存,提供高性能计算与内存吞吐,在内存限制配置下推理性能提升2-3倍,计算限制配置下提升约2倍。

文章介绍了AI数据标注产业面临的合规问题,并启动了《面向人工智能的数据标注合规指南》团体标准研制。该标准旨在解决数据来源、标注内容与过程操作、人员管理、数据安全和隐私保护等问题,为AI企业提供低成本的解决方案。