


在当今数字化时代,文本转语音(TTS)技术的应用越来越广泛,从智能助手到有声读物,再到播客等多媒体内容创作。然而,传统的TTS系统在处理长文本、多说话人对话以及情感表达方面存在诸多限制。微软最近开源的VibeVoice模型,以其创新的技术和卓越的性能,为这一领域带来了重大突破。

一、项目概述
VibeVoice是一个新型的文本到语音(TTS)模型,能够生成富有表现力、长篇幅、多说话者的对话式音频。它通过创新的连续语音标记化技术和下一代标记扩散框架,结合大型语言模型(LLM),实现了高效处理长序列音频的能力,同时保持高保真度。VibeVoice能够合成长达90分钟的语音,支持多达4位不同说话者,突破了传统TTS系统在长度和说话人数上的限制。

二、核心功能
(一)多说话者支持
VibeVoice能够生成多达4位不同说话者的对话式音频,适用于播客、有声读物等场景。这一功能使得生成的音频更加接近真实的对话场景,每个说话者的声音特征和语调都能被准确地捕捉和再现。
(二)长篇幅对话
VibeVoice支持生成长达90分钟的连续语音,突破了传统TTS系统在长度上的限制。这一功能使得VibeVoice能够处理复杂的长篇对话,如播客、有声读物和多参与者有声书等。
(三)富有表现力的语音
VibeVoice根据文本内容生成带有情感和语调的语音,使对话更加自然和生动。这一功能使得生成的语音不仅在内容上准确,而且在情感表达上也更加丰富。
(四)跨语言支持
VibeVoice支持多种语言的语音合成,能够处理跨语言的对话场景。这一功能使得VibeVoice在国际化的应用中具有广泛的应用前景。
(五)高保真音频
VibeVoice生成的语音质量高,接近人类的自然语音,提供更好的用户体验。这一功能使得VibeVoice在各种应用场景中都能提供高质量的音频输出。
(六)实时交互
VibeVoice能够实时生成语音,支持动态对话和交互式应用。这一功能使得VibeVoice在实时交互场景中具有强大的应用能力。
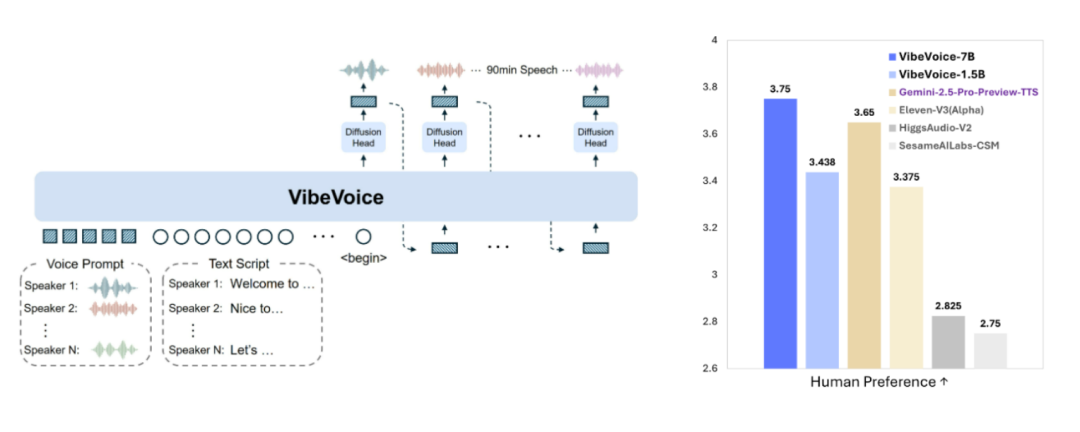
二、技术原理
(一)连续语音标记化
VibeVoice采用连续的语音标记化技术,将音频信号分解为语义和声学标记。标记以极低的帧率(如7.5 Hz)运行,提高了计算效率,同时保留了音频的高保真度。
(二)下一代标记扩散框架
基于扩散模型的生成框架,结合大型语言模型(LLM)理解文本上下文和对话流程。扩散模型通过逐步细化生成的音频标记,最终生成高质量的语音信号。
(三)多说话者一致性
通过特定的说话者嵌入(Speaker Embeddings)技术,确保不同说话者的声音特征在长篇幅对话中保持一致。VibeVoice支持多说话者的语音合成,能够自然地处理说话者之间的切换和对话流程。
(四)高保真音频生成
采用先进的声码器(Vocoder)技术,将生成的标记转换为高质量的音频信号。通过优化声码器的参数,确保生成的语音在音质上接近人类的自然语音。
三、应用场景
(一)播客制作
VibeVoice能够生成多达4位不同说话者的对话式音频,支持长达90分钟的连续语音,非常适合制作多主持人播客节目。这一功能使得播客制作更加高效,能够自动生成完整的对话内容,无需人工干预。
例如,在一个科技播客中,可以有多个主持人和嘉宾参与讨论,VibeVoice能够自然地处理说话者之间的切换和对话流程,使听众能够清晰地分辨出每个说话者的声音。
(二)有声读物
VibeVoice生成富有情感和语调的语音,使有声读物更加生动有趣,提升听众的阅读体验。这一功能使得有声读物不仅在内容上准确,而且在情感表达上也更加丰富。
例如,在一个儿童有声读物中,VibeVoice可以根据文本的情感内容生成带有相应情感的语音,如悲伤、喜悦、愤怒等,使听众能够更好地沉浸在故事中。
(三)虚拟助手
VibeVoice生成的语音自然流畅,适合用于虚拟助手的语音交互,为用户提供更加人性化的服务,增强用户体验。这一功能使得虚拟助手在各种应用场景中都能提供高质量的音频输出。
例如,在一个智能家居系统中,VibeVoice可以实时生成语音回复,与用户进行自然流畅的对话,提高服务效率和用户满意度。
(四)教育和培训
VibeVoice适用于模拟课堂讨论等教学场景,情感表达功能让互动式教学材料更加生动,提高学习效果。这一功能使得教学内容更加生动有趣,能够更好地吸引学生的注意力。
例如,在一个在线课程中,VibeVoice可以根据教学内容生成带有情感的语音,使学生能够更好地理解和吸收知识。
(五)娱乐和游戏
VibeVoice为虚拟角色生成富有表现力的语音,增强游戏和互动娱乐应用的沉浸感,让玩家有更真实的体验。这一功能使得游戏中的角色语音更加自然流畅,能够更好地提升玩家的沉浸感。
例如,在一个角色扮演游戏中,VibeVoice可以根据角色的性格和情感生成带有相应情感的语音,使玩家能够更好地投入到游戏中。
(六)研究与开发
作为一个开源框架,VibeVoice为AI语音合成的研究人员提供了灵活的工具,可以用于新技术的验证和优化。这一功能使得研究人员能够更好地探索和开发新的语音合成技术。
例如,研究人员可以利用VibeVoice的开源代码,进行模型优化和新技术的验证,推动语音合成技术的进一步发展。
四、快速使用
(一)环境准备
在开始之前,确保您的系统满足以下要求:
硬件要求:VibeVoice生成语音时需要至少7GB的GPU显存。推荐使用8GB显存的消费级显卡,如NVIDIA RTX 3060。
软件要求:Python 3.8+、CUDA(支持NVIDIA GPU)、Docker(可选,用于管理CUDA环境)
(二)安装CUDA环境(可选)
为了确保CUDA环境的稳定性和兼容性,推荐使用NVIDIA Deep Learning Container。以下是安装步骤:
# 使用NVIDIA PyTorch Container 24.07 / 24.10 / 24.12sudo docker run --privileged --net=host --ipc=host --ulimit memlock=-1:-1 --ulimit stack=-1:-1 --gpus all --rm -it nvcr.io/nvidia/pytorch:24.07-py3# 如果您的环境中没有flash attention,请手动安装pip install flash-attn --no-build-isolation
(三)克隆VibeVoice仓库并安装依赖
# 克隆VibeVoice仓库git clone https://github.com/microsoft/VibeVoice.gitcd VibeVoice/# 安装依赖pip install -e .
(四)启动Gradio演示
Gradio是一个简单的Web界面,用于快速测试和展示模型。以下是启动Gradio演示的步骤:
# 安装ffmpeg(用于演示)apt update && apt install ffmpeg -y# 启动Gradio演示(使用1.5B模型)python demo/gradio_demo.py --model_path microsoft/VibeVoice-1.5B --share# 如果需要使用7B模型,请确保您的GPU显存足够python demo/gradio_demo.py --model_path WestZhang/VibeVoice-Large-pt --share
(五)从文件直接生成语音
您也可以直接从文本文件生成语音。以下是具体步骤:
# 从文件生成语音(使用1.5B模型)python demo/inference_from_file.py --model_path WestZhang/VibeVoice-Large-pt --txt_path demo/text_examples/1p_abs.txt --speaker_names Alice# 生成多说话人的语音python demo/inference_from_file.py --model_path WestZhang/VibeVoice-Large-pt --txt_path demo/text_examples/2p_music.txt --speaker_names Alice Frank
注意事项
-
中文语音生成:在生成中文语音时,建议使用英文标点符号(如逗号和句号),以避免可能出现的发音问题。
-
语音速度:如果生成的语音速度过快,可以尝试将文本分段,并为每段文本指定相同的说话者标签。
-
模型选择:7B模型在稳定性和表现力方面表现更好,但需要更多的GPU显存。如果您的硬件条件有限,可以使用1.5B模型。
五、结语
VibeVoice作为微软开源的长文本多说话人语音合成模型,凭借其创新的技术和强大的功能,为TTS领域带来了新的突破。它不仅在长文本处理和多说话人支持方面表现出色,还在情感表达和语音质量上达到了新的高度。VibeVoice的开源,为研究人员和开发者提供了宝贵的资源,有望推动语音合成技术的进一步发展。
六、项目地址
项目官网:https://microsoft.github.io/VibeVoice/
GitHub仓库:https://github.com/microsoft/VibeVoice
技术论文:https://arxiv.org/pdf/2508.19205
(文:小兵的AI视界)