
1. 一分钟速览
-
问题:R1-style LRM(如 DeepSeek-R1、Kimi 1.5)在复杂任务上表现惊艳,却普遍存在 overthinking——推理链过长、冗余、重复,导致延迟 & 成本飙升。 -
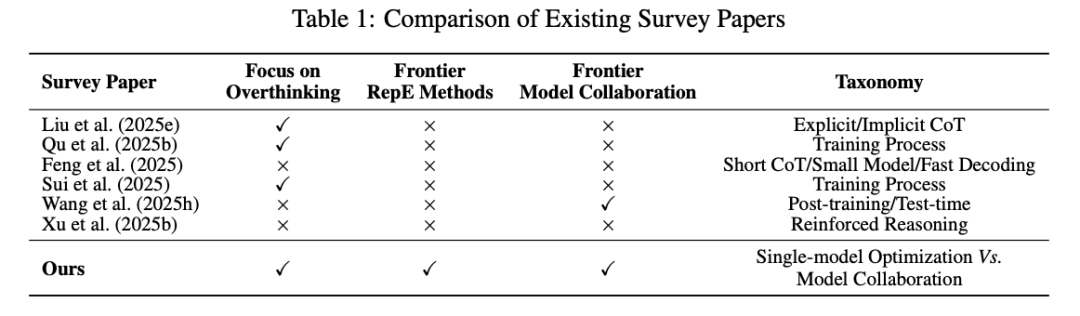
贡献:首篇系统综述高效推理的 survey,提出 「单模型优化 vs 多模型协作」 双层分类框架,覆盖 100+ 最新方法,并给出 4 大前沿应用展望。
2. 背景:当“想太多”成为瓶颈
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
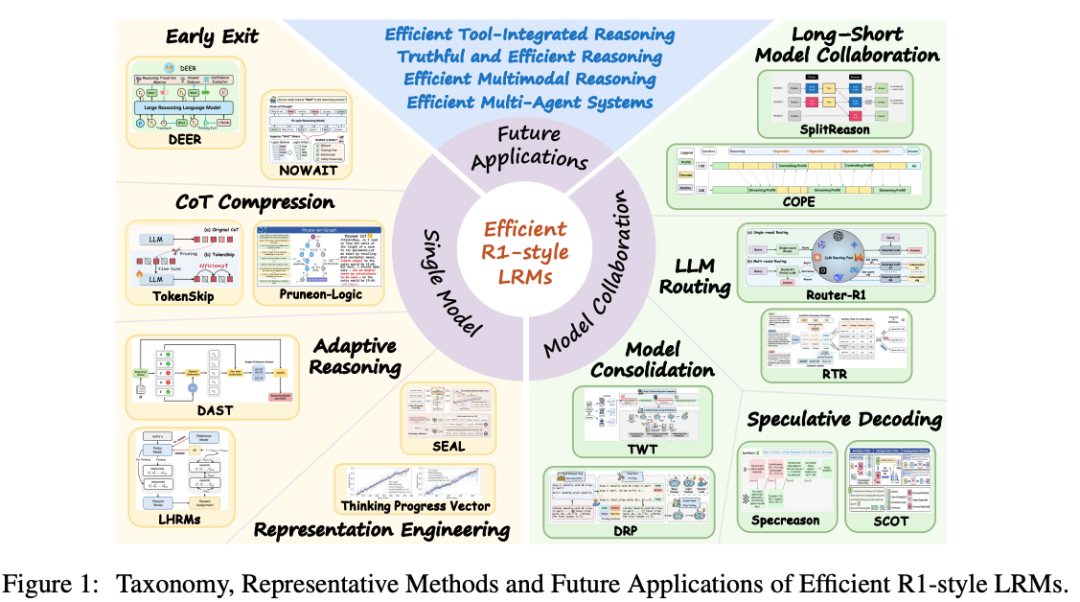
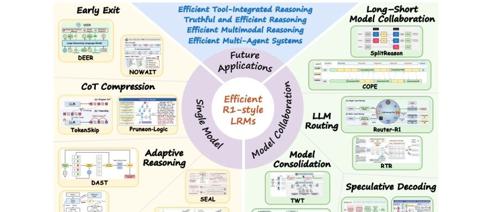
3. 方法全景:两条主线
论文将现有工作划分为 两大范式:
|
|
|
|
|
|---|---|---|---|
| 单模型优化 |
|
|
|
| 多模型协作 | 多个
|
|
|
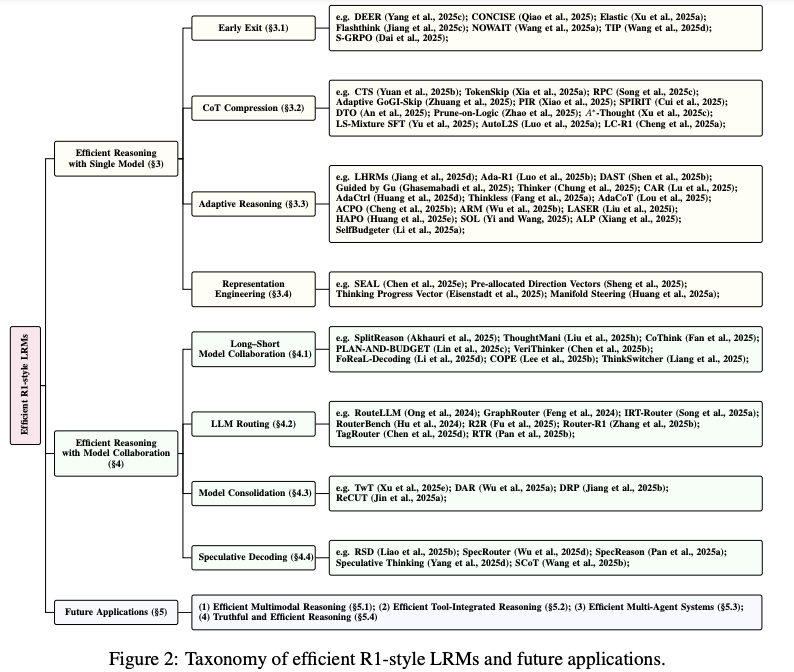
3.1 单模型优化:让模型“自省”
|
|
|
|
|
|---|---|---|---|
| Early Exit |
|
|
|
| CoT 压缩 |
|
|
|
| 自适应推理 |
|
|
|
| RepE |
|
|
|
3.2 多模型协作:打组合拳
|
|
|
|
|
|---|---|---|---|
| Short-to-Long |
|
|
|
| 模型路由 |
|
|
|
|
|
|
|
|
| 投机解码 |
|
|
|
4. 未来 4 大应用方向
|
|
|
|
|
|---|
(文:PaperAgent)