

先看一下可视化结果:
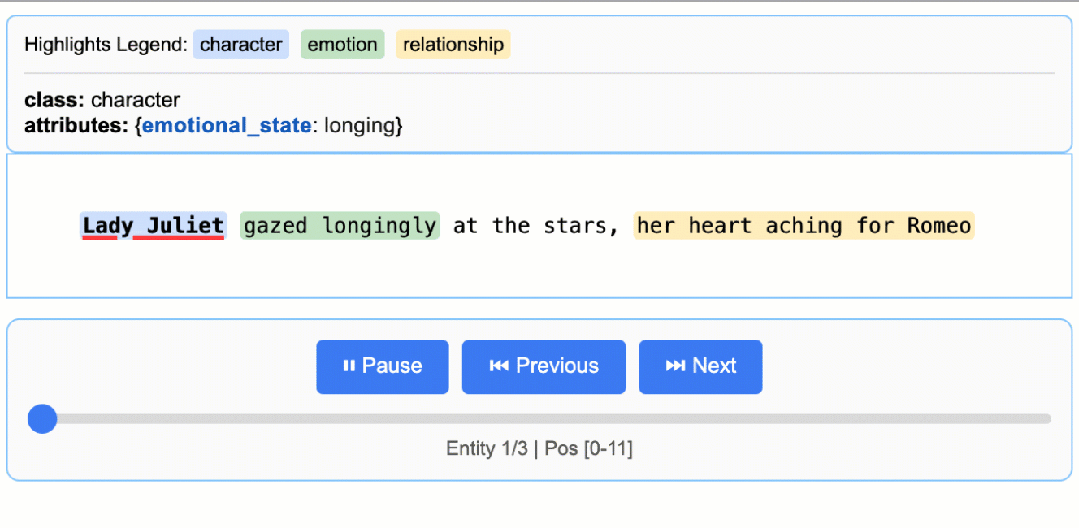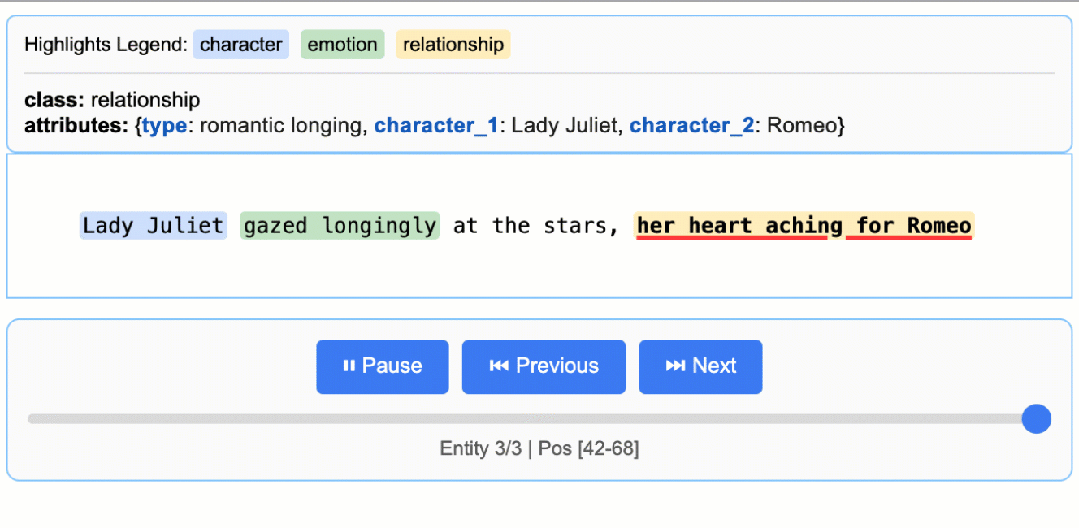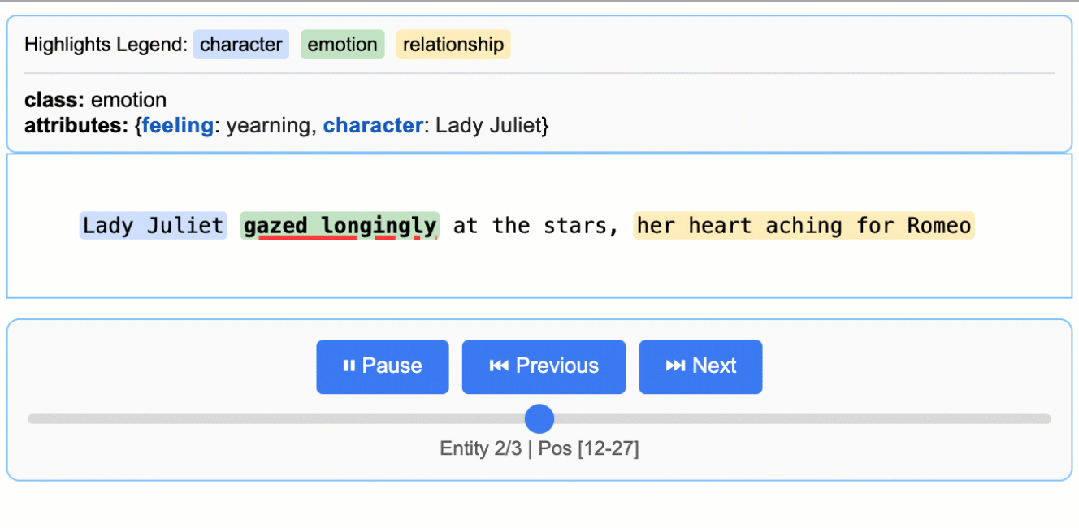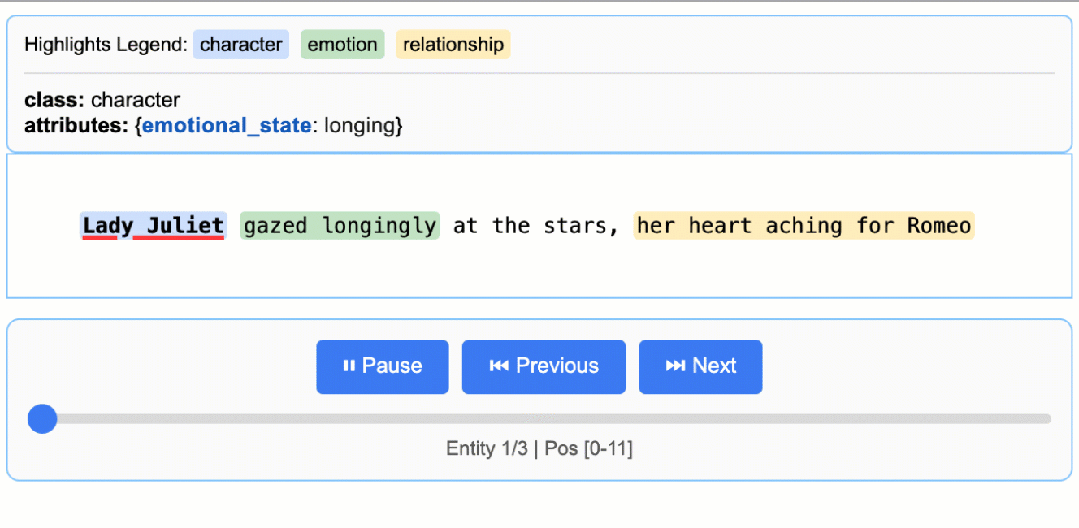
- 精确的源接地:将每个摘录映射到源文本中的精确位置,实现视觉突出显示,以便于追溯和验证。
- 可靠的结构化输出:根据您的少量示例强制执行一致的输出模式,利用 Gemini 等受支持模型中的受控生成来保证稳健的结构化结果。
- 针对长文档进行优化:通过使用文本分块、并行处理和多次传递的优化策略来实现更高的召回率,克服了大型文档提取的“大海捞针”难题。
- 交互式可视化:立即生成一个独立的交互式 HTML 文件,以在原始上下文中可视化和审查数千个提取的实体。
- 灵活的 LLM 支持:支持您喜欢的模型,从基于云的 LLM(如 Google Gemini 系列)到通过内置 Ollama 界面的本地开源模型。
- 适用于任何领域:只需几个示例即可定义适用于任何领域的提取任务。LangExtract 能够适应您的需求,无需任何模型微调。
- 利用 LLM 世界知识:利用精准的提示措辞和少量示例来影响提取任务如何利用 LLM 知识。任何推断信息的准确性及其是否符合任务规范取决于所选的 LLM、任务的复杂性、提示说明的清晰度以及提示示例的性质。
# gemini-2.5-flash这是推荐的默认设置,它在速度、成本和质量之间实现了极佳的平衡。# 对于需要更深入推理的高度复杂任务,gemini-2.5-pro可能会提供更优的结果# The input text to be processedinput_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"# Run the extractionresult = lx.extract(text_or_documents=input_text,prompt_description=prompt,examples=examples,model_id="gemini-2.5-flash",)
https://github.com/google/langextract
(文:PaperAgent)