
“ 数据分析和长文本处理是大模型在企业应用中的两个最有价值,也最具落地场景的技术方向。”
随着大模型技术和应用的不断发展,大模型应用场景不但越来越丰富,而且也越来越深化;但有两个应用场景可以说是现在2B场景中的重点场景——数据分析和长文本处理。
在信息时代,数据的重要性就不言而喻了;随着云计算和大数据技术的发展,以及我们每天产生的海量数据,怎么对这些数据进行分析处理,是很多企业需要考虑的问题;在大模型技术发展之前,数据处理基本上都是靠人工运维,根据需求编写大量的SQL和数据分析代码。
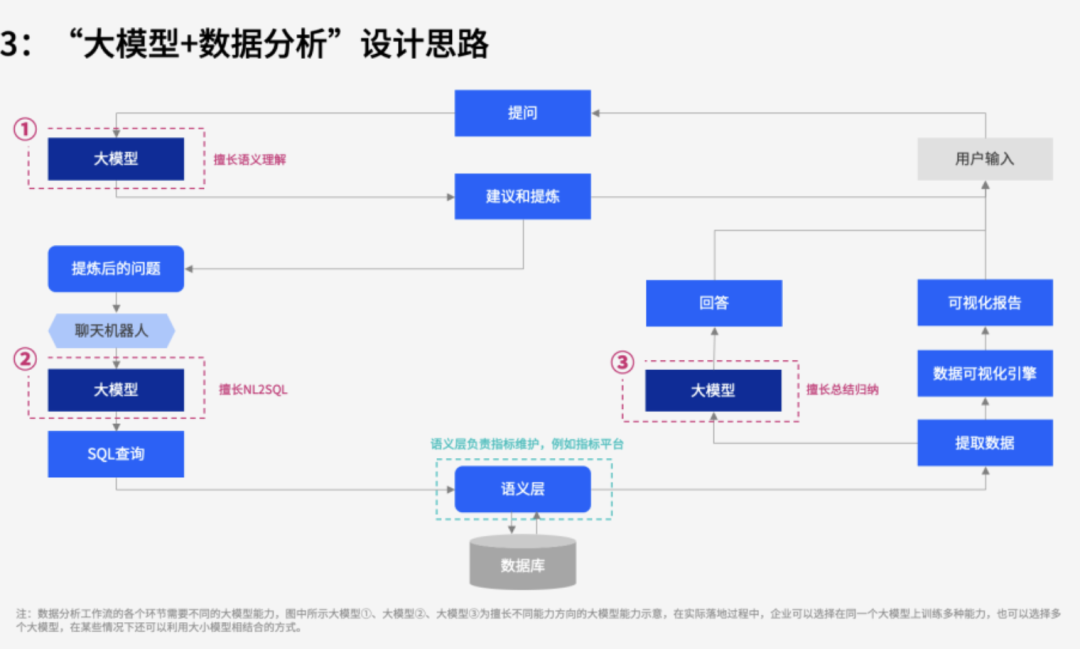
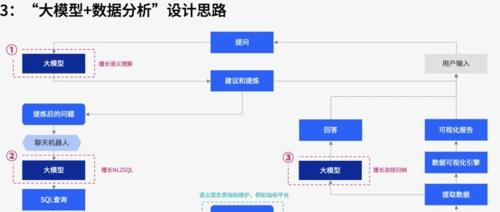
但有了大模型之后,我们可以把大模型的能力应用到数据分析领域;简单来说就是,让大模型扮演DBA的角色,让模型根据用户需求,自己编写SQL语句或数据处理代码;这样就能大大提升数据处理的速度。
其次关于长文本处理,受限于模型上下文窗口的限制,以及模型本身能力的问题(大模型在处理文本时,比较关注开头和结尾,对中间内容处理能力较弱);大模型在文本处理方面一直存在各种各样的问题,特别是面对长文本或超长文本时,更是心有余而力不足。
因此,怎么解决模型的长文本处理问题是企业应用中必须面对的问题。
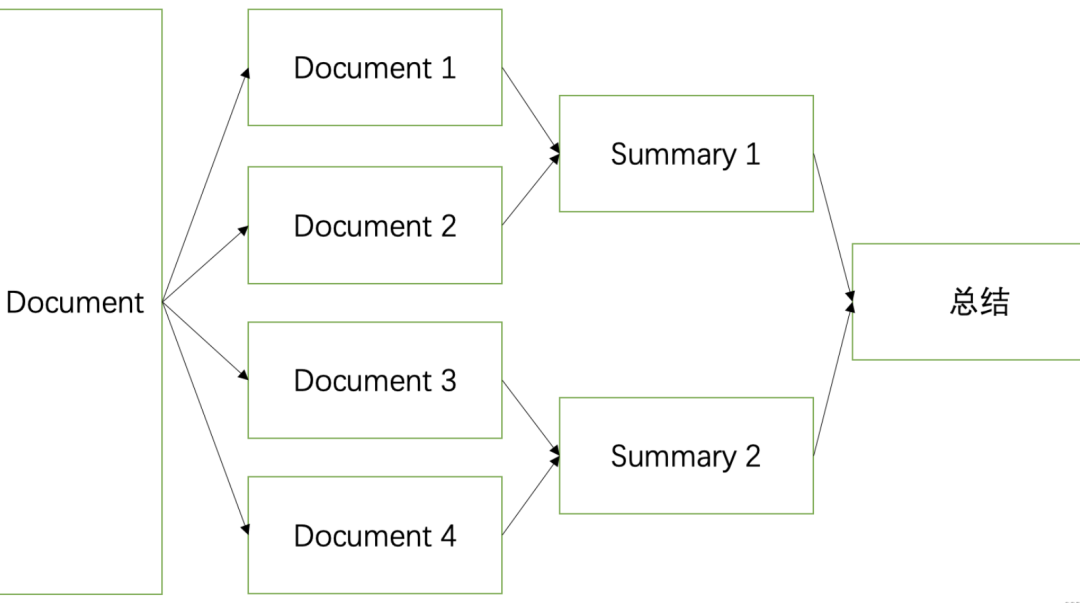
比如说RAG技术的出现,就是为了弥补大模型能力不足的问题,否则直接把所有文档直接丢给大模型,那么就不需要去优化RAG了。
而且,数据分析和长文本处理是目前企业应用中最有价值,以及落地性最强的两个典型场景。
数据分析场景
典型应用
|
|
|
|---|---|
| 自然语言问数 |
|
| 报表生成与解读 |
|
| 数据异常检测解释 |
|
| BI 智能助手 |
|
技术实现方式
-
使用 LangChain/LangGraph + SQL/Pandas Agent自动生成代码执行。
-
启用工具调用(Tool Calling),模型仅负责生成分析逻辑,由工具执行。
-
与数据平台对接(如 ClickHouse、BigQuery、Snowflake)打通数据流。
长文本处理场景
典型应用
|
|
|
|---|---|
| 合同/政策解析 |
|
| 客服知识库构建 |
|
| 会议纪要整理 |
|
| 法律、科研文献分析 |
|
技术实现方式
-
使用 RAG(检索增强生成)技术,通过向量数据库检索文档相关内容供大模型参考。
-
配合 分段处理、层级摘要、多轮提问实现对极长文本的深入理解。
-
支持结构化输出(如 JSON/表格),便于后续集成。
从技术本质上来说,其实就是让模型扮演人的角色;作为数据分析师,大模型就是一个会写SQL,写代码的人;作为长文本处理工具,大模型就是一个秘书和档案管理人员,需要对文档进行整理,总结,提炼。
(文:AI探索时代)